Docker
介绍
- https://www.dockerbook.com
- 最完整的Docker聖經 - Docker原理圖解及全環境安裝 https://joshhu.gitbooks.io/docker_theory_install/content/
- Docker — 从入门到实践 https://yeasy.gitbooks.io/docker_practice/content/
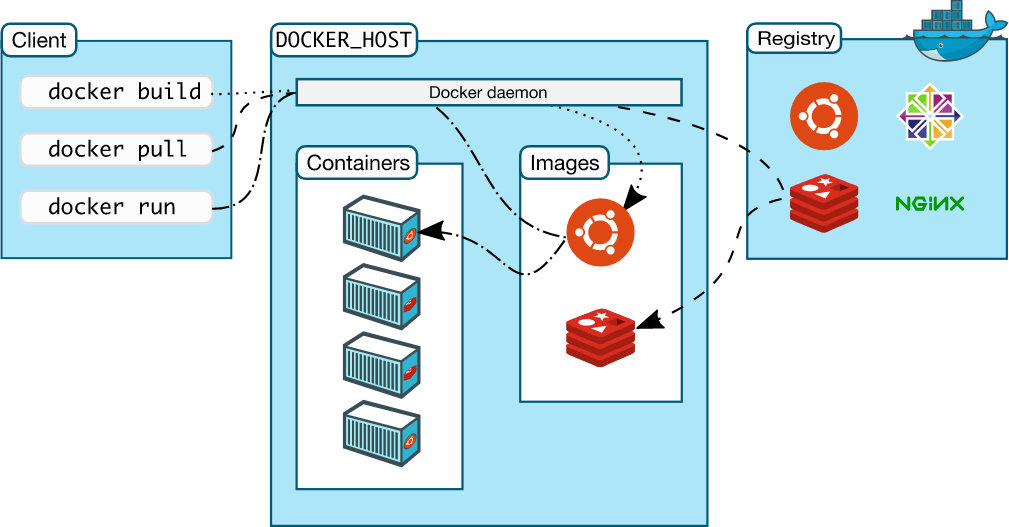
https://docs.docker.com/engine/docker-overview/#docker-architecture
base on LXC(Linux container) 每个container中运行的进程,是的确运行在host上的(用ps 可以查看的到), 这样的话,无论你的镜像是基于ubuntu, centos, 还是debian的,都是运行在主机内核上的(container中没有自己的内核)。也就是说如果主机内核不满足需求,container中的依赖此特性的应用程序就无法运行。
root@k8s-vm1:/home/ubuntu# ps aux|grep mongodb
999 8920 0.6 0.8 276684 65784 ? Ssl 03:09 0:12 mongod --config /etc/mongodb.conf --smallfiles
从上面 kubernetes 的例子可以看出:999 是 docker 用户,/etc/mongodb.conf 也是其专有的文件。但是这个 mongod 进程却是所有人都能看到。
Docker背后的内核知识—Namespace资源隔离 http://www.infoq.com/cn/articles/docker-kernel-knowledge-namespace-resource-isolation
“Linux内核实现namespace的主要目的就是为了实现轻量级虚拟化(容器)服务。在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以此达到独立和隔离的目的。”
Docker 背后的内核知识——cgroups 资源限制 本质上来说,cgroups 是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
Kubernetes 1.5引入了一个名为容器运行时接口(CRI)的内部插件API,以方便地访问不同的容器运行时,CRI允许Kubernetes使用各种容器运行时,而不需要重新编译。最广为人知的容器运行时是Docker,但在生态系统中还有其他容器运行时软件,比如Rkt、Containerd和Lxd。
Docker使用的Linux核心模組功能包括下列各項:
- Namespace – 用來隔離不同Container的執行空間
- Cgroup – 用來分配硬體資源
- AUFS(chroot) – 用來建立不同Container的檔案系統
- SELinux – 用來確保Container的網路的安全
- Netlink – 用來讓不同Container之間的行程進行溝通
- Netfilter – 建立Container埠為基礎的網路防火牆封包過濾
- AppArmor – 保護Container的網路及執行安全
- Linux Bridge – 讓不同Container或不同主機上的Container能溝通
『除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。』 从进程说起:容器到底是怎么一回事儿? Pid namespace 效果是 ps 只能看到自己创建的进程, 而且 ID 还是从 1 开始。其实 namespace 只是创建进程中要传入的一个参数而已,默认为 null。如此看来,进程和宿主机进程差别不大,要对其监控,常常需要些先导程序。
网络隔离后,相当多的容器为了轻量级,是不包含较为基础的命令的。这时就可以使用 nsenter 命令仅进入该容器的网络命名空间,使用宿主机的命令调试容器网络。但是 Debugging DNS Resolution 这个官方指南里面还是在一个专门的 pod 里面运行 nslookup 命令。
企业版 https://www.docker-cn.com/enterprise-edition 从 Infrastructure 到 Container 和 Plugin 都是 Trusted and Certified,而这些点也是被对手向 rkt 等所诟病最多的内容,docker 在 EE 版本进行了强化。我猜在 docker build 的时候会加入证书,防篡改。 对于 Docker 改名 Moby ,大家怎么看?https://www.zhihu.com/question/58805021 Moby 成了开源代码,build 好的会进入社区版。而 Docker 是注册商标。
文件系统
it use AUFS as backend storage. http://developerblog.redhat.com/2014/09/30/overview-storage-scalability-docker/ 。Docker的存储机制采用了非常灵活的模块化设计,目前支持5种存储引擎,分别为aufs、btrfs、device mapper、vfs和overlay。 http://fengchj.com/?p=2297
DOCKER基础技术:AUFS http://coolshell.cn/articles/17061.html 多层的,snapshot 类似的,『最主要的应用是,把一张CD/DVD和一个硬盘目录给联合 mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改』
Digging into Docker layers https://medium.com/@jessgreb01/digging-into-docker-layers-c22f948ed612
https://yeasy.gitbooks.io/docker_practice/cases/os/alpine.html
DevOps 流程中对于 Docker Image 的分层管理与实践:采用分层存储如果底层不变则能大幅度减少存储空间
NixOS 也是基于 alpine,但是有自己独特的包管理器。
Tini http://yunke.science/2018/04/09/Tini-command/
- 它可以防止意外造成僵尸进程的软件,僵尸进程可以(随着时间的推移)让整个系统崩溃,并使其无法使用。
- 它确保默认的信号处理程序适用于您在Docker镜像中运行的软件。 例如,对于Tini,即使您没有为其显式安装信号处理程序,SIGTERM 也会正确终止您的过程。
- 它完全透明! 没有Tini工作的Docker图像将与Tini无任何变化一起工作。
Kubernetes中的 pause 容器便被设计成为每个业务容器提供以下功能:
- 在 pod 中担任 Linux 命名空间共享的基础
- 启用 pid 命名空间,开启 init 进程
- 收割僵尸,这个和 tini 似乎类似
似乎每个 pod 都有一个对应的 pause 容器,在 docker ps 下面可以看到。http://dockone.io/article/2785 看不大懂。
Hyper is a Hypervisor-agnostic Docker Runtime. Its goal is to Make VM run like Container, by combining the best from both:
- AS Fast as Container
- Isolated by VM
HyperContainer利用虚拟化技术(而非namespaces与cgroups)实现隔离与资源限制
Hypernetes:为Kubernetes带来安全性与多租户机制 http://dockone.io/article/1340
创始人赵鹏的中文博客 https://wangxu.me/
张磊 大咖信息 http://www.itdks.com/member/people/49328
VLIS实验室云计算组张磊:关于Docker、开源,以及教育的尝试(图灵访谈) http://www.ituring.com.cn/article/203520
Runtime
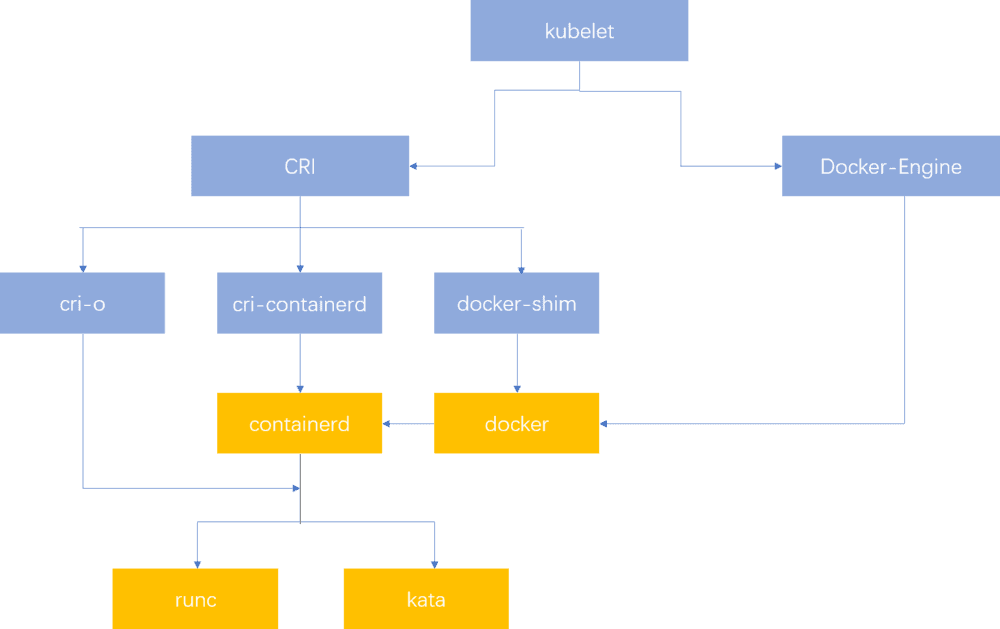
Image Come from here。OCI 和 CRI 区别在于 CRI 是 k8s 标准,OCI 是 Linux 容器标准,Docker 可以被其他调度程序比如自己的 Docker swarm 或者 Mesosphere 调用,这些都是 k8s 竞争对手,而且产生早于 k8s。所以如果要能被 k8s 调用,中间需要一层 shim 来做翻译。实现 CRI 接口的容器 runtime 有 CRI-O, fratki, cri-containerd, dockershim,而最底层的 runc 和 kata (还有 CoreOS rtk)才是真正的运行时。详细历史渊源可以看Container runtimes: clarity,Docker、Containerd、RunC…:你应该知道的所有。开源就是这样,各种分化和兼容。为什么还需要 CRI 呢?为什么不让kubelet直接调用runc呢?CRI相当于本地的容器运行时管理,除了能让kubelet有统一的容器管理接口,也能在kubelet崩溃时自我管理本地的容器。
https://unix.stackexchange.com/questions/254956/what-is-the-difference-between-docker-lxd-and-lxc lxd 更像传统的虚拟机,Docker container 可以跑在其上面。 Ubuntu 自己搞了个 LXD,LXD isn’t a rewrite of LXC, in fact it’s building on top of LXC to provide a new, better user experience. Under the hood, LXD uses LXC through liblxc and its Go binding to create and manage the containers.
Runtime 方面,Google 带来了他们自己的安全容器方案 —— gVisor。gVisor 提供新型沙箱容器运行时环境,能够在保证轻量化优势的同时,提供与虚拟机类似的隔离效果。这与去年在 Austin 的 KubeCon 上宣布成立的 KataContainer 项目定位十分类似。KataContainer 源自于 Intel 的 Clear Container 和 hyper 的 runV,是一种基于轻量级虚拟化的容器技术。它通过在容器外加装一层经过大量裁剪和优化的虚拟化,实现容器间的内核隔离。
AWS firecracker https://firecracker-microvm.github.io/,Rust 写的,Getting Started,要求 Linux 4.14+, kvm,只模拟 virtio-net, virtio-block, serial console, and a 1-button keyboard controller used only to stop the microVM,所以速度快。Kata 在 QEMU 基础上实现了容器接口(OCI),而这个只是一个更快速的 QEMU。AWS Lambda,更安全,速度更快(125ms 启动),所以更为类似的应该是 gVisor。所以,理论上,Kata Containers 也可以使用 Firecracker 运行起来。AWS 又推出Bottlerocket OS,也是 Rust 语言写的,和 firecracker 有重合地方么?
Kubernetes的未来在于虚拟机而非容器容器的隔离性差导致 k8s 现在只能运行在软租户模式,也就是说 k8s namespace 这种达不到硬租户的隔离,导致现在模式一般都是一个租户(用户、项目、产品、部门)一个 k8s 集群,这导致了资源的浪费。如果是一个大的、集中式的 k8s 集群,既提高了资源利用率,也容易升级和管理。原始文章为 Hard Multi-Tenancy in Kubernetes。
Image
保存位置可以用 docker info 来查看。Mac 因为运行在 linux vm 上面,image 也保存在这个 vm 里面。
Alpine Linux,一个只有5M的Docker镜像 http://www.infoq.com/cn/news/2016/01/Alpine-Linux-5M-Docker。”另外,Alpine Linux使用了musl,可能和其他Linux发行版使用的glibc实现会有所不同。在容器化中最可能遇到的是DNS问题,即musl实现的DNS服务不会使用resolv.conf文件中的search和domain两个配置,这对于一些通过DNS来进行服务发现的框架可能会遇到问题。” 我看monocular api server就是基于这个,没有遇到DNS的问题啊,毕竟k8s也是用dns做服务发现的。Docker hub 就是 alpine,可以直接在 k8s 里面使用。但是创建后马上 CrashLoopBackOff。没有 pause?需要加上一个命令:sleep 3600。 To run it in k8s: kubectl run alpine --rm -ti --image=alpine /bin/sh 为什么不直接使用BusyBox?https://blog.ubuntu.com/2018/07/09/minimal-ubuntu-released 这个优化过的只有 29MB。 “首先是空间占用问题,小是Alpine Linux的最大优势,但是Docker的文件系统可以进行分层缓存,对于已经构建或者拉取过镜像的机器来说,每次的增量更新内容可能并不会很多。也就是说,如果所有镜像都使用相同的基础镜像,这个镜像在所有机器上都只会拉取一遍。” Kubernetes best practices: How and why to build small container images这里有讲如何使用 Docker multi-step builds 特征来降低镜像大小,对于 Go 这种编译语言,运行不需要 SDK,可以生成编译和运行时两个镜像,这样后者可以很小。
删除 image 时会发现删除一批,这个是 overlay 的 image 么?而且之间会有依赖,比如我的 spring-demo 就依赖 openjdk,不能先删除 openjdk。这是因为 spring-demo 是建立在 OpenJDK 上面? How To Remove Docker Containers, Images, Volumes, and Networks 这里列出了清除的常用命令,比如docker image prune -a会删除没有用到的 image,否则日积月累虚拟机磁盘会占满,docker-rotate也是来做这个的,为什么清理这个功能不是 Docker 内置呢?有创建就要有对应的清理操作,这应该成为共识。
https://github.com/wagoodman/dive A tool for exploring a docker image, layer contents, and discovering ways to shrink your Docker image size.
国内 docker 仓库镜像对比,Docker 中国官方镜像加速,官方的说“该镜像库只包含流行的公有镜像。私有镜像仍需要从美国镜像库中拉取。” 其他仓库:
- https://azure.microsoft.com/zh-cn/services/container-registry/
- https://quay.io/
- gcr https://cloud.google.com/container-registry/
一般因为网络原因,拉取镜像很慢,https://cloud.google.com/container-registry/ HOW TO SET UP A REGISTRY PROXY CACHE WITH DOCKER OPEN SOURCE REGISTRY这个可以设置一个代理来缓存最近使用的镜像,这样再次拉去时就很快,但是需要给 Docker 加一个参数 --registry-mirror=https://mycache.example.com:5000,集群环境中则每台节点都要设置了。
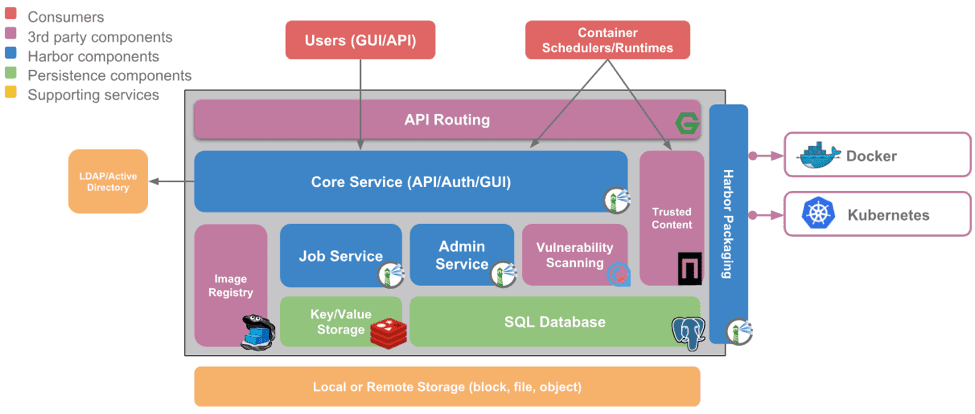
https://www.cncf.io/blog/2018/11/13/harbor-into-incubator/ 只有这个图才清楚些。
『“Harbor技术栈”中有多个第三方组件,包括NGINX,Docker,Distribution V2,Redis以及PostgreSQL。Harbor同时依赖Clair来进行漏洞扫描,依赖Notary进行镜像签名。』
其实还挺复杂的,用到了 k-v cache 和数据库,Redis 单纯做数据库的 cache 么?这里其实主要是个目录服务。Distribution V2 是 Docker 官方的 registry,也可以保存容器目录啊。那要 sql db 为何?保存用户和镜像统计信息?
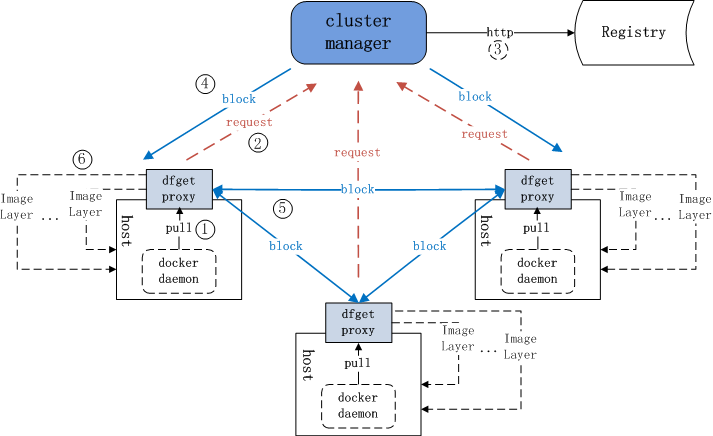
什么是 Dragonfly? & Design doc. Dragonfly中文名“蜻蜓”,是一个基于P2P的智能文件分发系统。解决了应用部署,大规模缓存文件分发,数据文件分发,图像分发等大规模文件分发场景中低效率,低成功率,浪费网络带宽等问题。 『图中镜像仓库(registry)类似于文件服务器。dfget proxy也称为dfdaemon,它拦截来自docker pull和docker push的HTTP请求,然后将那些跟镜像分层相关的请求使用dfget来处理。』这是种非侵入式技术。应用使用容器隔离后,各自为政,每个都用 pull 方式(原来是 push)去 registry 拉取应用程序,这导致 registry 客户端激增,压力增大。类比 maven 仓库,其只是在开发环境拉取数据,应用运行中并不需要。
Dockerfile
CMD [“/main”], ENTRYPOINT [“/main”],前者无法传递参数。
# Delete all containers
docker rm $(docker ps -a -q)
# Delete all images
docker rmi $(docker images -q)
Docker多阶段构建最佳实践 对于多阶段构建,您可以在Dockerfile中使用多个FROM语句。每个FROM指令可以使用不同的基础,并且每个指令都开始一个新的构建。您可以选择性地将工件从一个阶段复制到另一个阶段,从而在最终image中只留下您想要的内容。
- 容器只运行单个应用
- 将多个RUN指令合并为一个
- 选择合适的基础镜像(alpine版本最好)
Atomic/CoreOS
提供运行 Docker 环境并对容器环境优化的主机操作系统,和上面 alpine 这种 docker 镜像不同。 It aims to combine the best of both CoreOS Container Linux and Fedora Atomic Host. https://coreos.fedoraproject.org/
CoreOS Container Linux https://coreos.com/os/docs/latest/ (previously named CoreOS),有提供 OpenStack 镜像,解压后有 800MB,这和 centos cloud image 差不多,比 Fedora/Ubuntu 200MB 大多了。和 cloud-init 类似,这个自创了一个格式 Ignition 来定制镜像的初始化,挺复杂。
OpenSuse 的 kubic,使用 cri-o,更为纯粹,系统和 atomic 一样也是事务型的更新。
Tool
Introducing Jib — build Java Docker images better 这个用来加快 Java 应用容器化:不用安装 Docker,不用写 Dockerfile,不用 Root 权限,直接在 Maven 里面生成镜像,最后 push 到仓库,而且因为考虑到了 image layer,所以速度更快。
CRIU 容器的动态热迁移工具,其实普通的进程也可以,只要是在用户空间就可以。如果应用有外部依赖比如存储卷,这个迁移就比想象的复杂。
Think
看到 Docker 居然在 CI/CD 也遍地开花,不禁感叹:这种小技术为什么推广这么开?
体现的还是:分离。虚拟机是硬件资源的抽象,和软件无关,只是方便了运维人员。而 Docker 的 image 是技术/框架相关的,分离和抽象出了软件栈,一种轻量化的 PaaS。而当服务注册和发现是基于全局 DNS 和 proxy,这种隔离就更明显了,对项目代码就更无侵入性了、更透明了。
Docker 更是一种动态的封装,运行时的封装。运行 Tomcat 虽然也很简单,但仍然要了解其特定的命令。而 Docker 全部是 docker run。
那和一般的虚拟机比较呢?Docker 启动更快,因为虚拟层次少性能更好。更因为和 Linux 操作系统紧密结合灵活性更好,比如磁盘和网络的分配上面。