深度学习
机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1) https://github.com/ty4z2008/Qix/blob/master/dl.md
Google CEO Sundar Pichai刚刚在官方博客宣布开源自己的最新机器学习系统TensorFlow,并称希望此举有助于机器学习社区通过代码而不是论文
为了满足研究人员和开发者日益增长的各种需求,微软亚洲研究院于日前将分布式机器学习工具包(DMTK)通过Github开源。
继 Facebook 开源Torch、Google 开源TensorFlow以及微软开源分布式机器学习工具包DMTK之后,IBM 成为今年第四家开源自家机器学习系统的巨头,这显示出机器学习的生态构建与人才争夺战的白热化。IBM 开源的这套系统叫做SystemML,将会通过 Apache Software Foundation 开放共享,并允许开发者修改其代码,目前 SystemML 已作为孵化器项目被 Apache 接纳。
DeepMind 研发的围棋 AI AlphaGo 系统是如何下棋的? - 知乎 https://www.zhihu.com/question/41176911
谷歌工程师:再给阿尔法三个月 就能击败柯洁_Google 谷歌_cnBeta.COM http://www.cnbeta.com/articles/482765.htm>
AlphaGo开发者:人工智能将如何塑造未来 http://www.cnbeta.com/articles/482765.htm
Google开源了Parsey McParseface语言工具 http://www.cnbeta.com/articles/500905.htm
Google已经发布了开源的SyntaxNet自然语言神经网络框架,以帮助机器更好地理解自然语言。SyntaxNet中包括了Parsey McParseface,后者是一种专门用于“解剖”英语的语言解析器。Google称之为世界上最准确的语言解析器,并且已经放出了允许人们借助自有数据来训练SyntaxNet的全部代码。SyntaxNet和Parsey McParseface都是自然语言理解(NLU)系统的一部分。给出一个句子,它就会将之分解成各种部分,比如名词、动词、形容词。对自然语言研究人员和需要这种应用程序的人们来说,这款开源工具显然会助力相关研究的爆发式发展。据Google自述,经过TensorFlow框架训练后的Parsey McParseface,是其出产的“最复杂的网络”之一。在某一测试中,他们发现该模型的准确度超过94%——作为比较,训练有趣的语言学家的准确率在96-97%左右——这表明该软件的技能熟练度已与人类相当。
谷歌DeepMind Lab开源,量身打造个人AlphaGo http://www.infoq.com/cn/news/2016/12/Google-DeepMindLab-Open
人工智能里程碑:新AlphaGo Zero横空出世,彻底摆脱人类 https://wallstreetcn.com/articles/3035942
关于AlphaGo Zero https://zhuanlan.zhihu.com/p/30262872
虽然现在《不使用人类知识掌握围棋》,其走的也只是加快训练过程的路子而已。居然不需要训练数据,看上去很吸引人,但是这个如何处理现实生活的例子呢?因为围棋规则其实代表了一切,而对于现实生活比如诊断病症,很多病因都是未知的,更没有规则。模拟细胞?
https://zh.wikipedia.org/wiki/Leela_Zero http://zero.sjeng.org/
Leela Zero是依照DeepMind在科学期刊《自然》上对于AlphaGo Zero所发表的论文《Mastering the game of Go without human knowledge[2]》所实做出的开源电脑围棋程序[3],也就是不使用人类棋谱与累积的围棋知识,仅实做围棋规则,使用单一类神经网络从自我对弈中学习(不像AlphaGo以人类角度思考,设计了Policy Network与Value Network)。
https://github.com/SabakiHQ/LeelaSabaki UI 界面,需要训练好的数据也就是weight.txt,然后对弈时并不需要服务器端。
https://github.com/pytorch/elf Facebook 开源了它打败专业围棋棋手的程序 ELF OpenGo
ELF OpenGo 在与目前公开可用的、最强的围棋机器人 LeelaZero 的对一种,后者采用了除ponder外的缺省配置,以及公开权重(192x15,158603eb, Apr. 25, 2018),结果 OpenGo 赢得了全部 200 场比赛。https://www.cnbeta.com/articles/tech/723041.htm
https://www.slideshare.net/agibsonccc/skymind-64189513 深度学习的基本场景
http://image-net.org/explore.php?wnid=n02512053 图像训练样本库
https://deeplearning4j.org/ 深度学习的 java 版,有用到 spark。
Angel是一个基于参数服务器(Parameter Server)理念开发的高性能分布式机器学习平台,它基于腾讯内部的海量数据进行了反复的调优,并具有广泛的适用性和稳定性,模型维度越高,优势越明显。 Angel由腾讯和北京大学联合开发,兼顾了工业界的高可用性和学术界的创新性。
MXNet
是一个轻量级、可移植、灵活的分布式深度学习框架,2017 年 1 月 23 日,该项目进入 Apache 基金会,成为 Apache 的孵化器项目。MXNet 的初衷是想结合 Minerva 和 CXXNet 两者的功能:CXXNet 通过配置来定义和训练神经网络,所以在图片分类等使用卷积网络的应用上很方便;而 Minerva 提供类似 numpy 一样的张量计算接口,更灵活。MXNet 就是这样一个两者功能都具备的系统,其名字来自 Minerva 的 M 和 CXXNet 的 XNet,其中 Symbol 的想法来自 CXXNet,而 NDArray 的想法来自 Minerva。
目前主流的深度学习系统一般采用命令式编程(imperative programming,比如 Torch)或声明式编程(declarative programming,比如 Caffe,theano 和 TensorFlow)两种编程模式中的一种,而 MXNet 尝试将两种模式结合起来,在命令式编程上 MXNet 提供张量运算,而声明式编程中 MXNet 支持符号表达式。用户可以根据需要自由选择,同时,MXNet 支持多种语言的 API 接口,包括 Python、C++(并支持在 Android 和 iOS 上编译)、R、Scala、Julia、Matlab 和 JavaScript。
由国人领导开发,可能相关的资料会多点。
http://mxnet.io/get_started/centos_setup.html Centos 上面的安装步骤,GPU 用的也是 CUDA。
http://www.infoq.com/cn/articles/use-mxnet-in-deep-learning-part01 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
国产的,但是我觉得没有官方的好 http://mxnet.io/tutorials/python/mnist.html 官方的有测试和验证的步骤。试问如果没有这一步,怎么看效果呢?
腾讯云已经有了 https://www.qcloud.com/product/fpga
谷歌硬件工程师揭秘TPU为何会比CPU、GPU快30倍? http://www.cnbeta.com/articles/tech/600043.htm Jouppi表示,谷歌的硬件工程团队在转向定制ASIC之前,早期还曾用FPGA来解决廉价、高效和高性能推理的问题。但他指出,FPGA的性能和每瓦性能相比ASIC都有很大的差距。他解释说,“TPU可以像CPU或GPU一样可编程,它可以在不同的网络(卷积神经网络,LSTM模型和大规模完全连接的模型)上执行CISC指令,而不是为某个专用的神经网络模型设计的。一言以蔽之,TPU兼具了CPU和ASIC的有点,它不仅是可编程的,而且比CPU、GPU和FPGA拥有更高的效率和更低的能耗。
https://www.r-bloggers.com/lang/author/%E5%86%99%E9%95%BF%E5%9F%8E%E7%9A%84%E8%AF%97
深度学习入门资源索引 https://www.r-bloggers.com/lang/chinese/2083
对比深度学习十大框架:TensorFlow 并非最好?
http://www.oschina.net/news/80593/deep-learning-frameworks-a-review-before-finishing-2016
Yoshua Bengio新书《Deep Learning》中文版开放预览(附PDF下载链接)http://jiqizhixin.com/article/1955
深度学习-LeCun、Bengio和Hinton的联合综述 http://www.csdn.net/article/2015-06-01/2824811 http://www.csdn.net/article/2015-06-02/2824825
Neural Networks and Deep Learning https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/ 短小精悍。这个极客学院也有,但是没这个完整。
Data 8X: Foundations of Data Science now on edX https://data.berkeley.edu/education/data-8x 据说讲的很深入浅出
机器学习速成课程 https://developers.google.cn/machine-learning/crash-course/ 谷歌的,中文
『在20系显卡的首发评测中,我们说到过,完整版TU106采用的是全新设计的图灵计算单元,其中包括为光线追踪而生的RT Core,为深度学习打造的Tensor Core』深度学习要买RTX 2080吗?,深度分析】深度学习选GPU,RTX 20系列性价比最高,NVIDIA深度学习Tensor Core核心全面解析:测试篇,NVIDIA Tensor Core深度学习核心解析:全是干货。20 系列卖的这么贵,原来是有 Tensor Core?那么问题来了,一般游戏用户不会用到这个吧?
TensorFlow
中文版 http://wiki.jikexueyuan.com/project/tensorflow-zh/ 安装部分有点旧了。
http://wiki.jikexueyuan.com/project/tensorflow-zh/get_started/os_setup.html TensorFlow 的 GPU 特性只支持 NVidia Compute Capability >= 3.5 的显卡。官网上是 >= 3.0,日了狗啊。
https://developer.nvidia.com/cuda-gpus 兼容性列表
https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units all video cards
SLI 对于 CUDA 没有用处 The SLI connection is not used by CUDA. If you have two cards, they will appear as two devices in CUDA, even if they are connected with SLI. So, your CUDA application has to handle each GPU individually.
https://developer.nvidia.com/cuda-downloads
https://developer.nvidia.com/compute/cuda/8.0/prod/docs/sidebar/CUDA_Installation_Guide_Linux-pdf
安装完后还要设置环境变量, example dir : /usr/local/cuda-8.0/samples/,编译需要点时间。上面 pdf 里面也有安装后的确认方法,保证整个基础环境是正确的。nvidia-smi 会显示显卡状态,GTX 9 系列都有低负载风扇停转的功能。酷。
安装 Tensorflow https://www.tensorflow.org/get_started/os_setup
TensorFlow似乎默认的是没有 GPU 版本的,只用 CPU?这个安装完也有个 verify 的方法。
>>> sess = tf.Session()
I tensorflow/core/common_runtime/gpu/gpu_device.cc:885] Found device 0 with properties:
name: GeForce GTX 960
major: 5 minor: 2 memoryClockRate (GHz) 1.1775
pciBusID 0000:03:00.0
Total memory: 3.94GiB
Free memory: 3.90GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:906] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 960, pci bus id: 0000:03:00.0)
酷!
还有个 demo 的例子,就是识别手写数字的。例子最好用 root 运行,这样前面环境变量也要在 root 里面设置一遍,否则会说找不到某某库。
一会儿训练完了,但是结果呢?识别手写数字例子 http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html 。看完了,还是不知道讲的啥。里面有说每个点的 weight,如何计算呢?我随机出一个,然后用数据训练?那得多慢啊。
Spark上的深度学习框架再添新兵:Yahoo开源TensorFlowOnSpark http://www.infoq.com/cn/news/2017/02/Spark-Yahoo-TensorFlowOnSpark 这里 Spark 并不控制 GPU,只是通过 gRPC 和 TF GPU 通信。
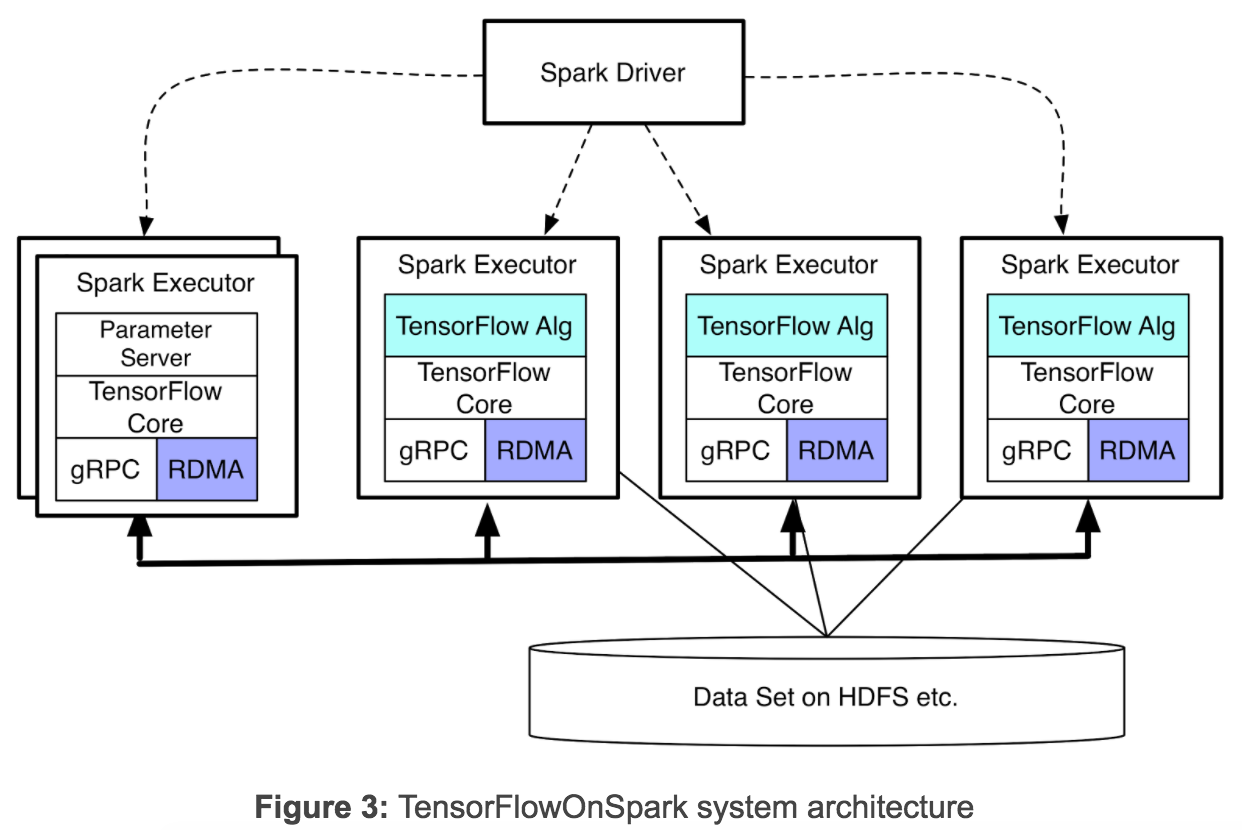
http://www.infoq.com/cn/news/2017/06/Google-TensorFlow-API Google发布新的TensorFlow物体检测API,这个挺好,能在手机上面运行,不用云访问。
https://www.tensorflow.org/serving/docker 这个很简单,在 ubuntu image 上面安装 bazel 开发环境,然后用 python grpcio 库和 tensorflow 通信。
PaddlePaddle
百度搞的,https://github.com/paddlepaddle/book 这里有 7 个例子,都中文的,不错哦。而且还可以直接在 docker 上面运行 Jupyter Notebook !!!
跑在Kubernetes上的开源深度学习,百度这次带来了哪些技术看点?http://mp.weixin.qq.com/s/He9hkR-M3LITo5wNivjRaA
https://github.com/facebookresearch/DrQA DrQA is a system for reading comprehension applied to open-domain question answering.
谷歌最新语义图像分割模型DeepLab-v3+现已开源 https://www.cnbeta.com/articles/soft/707419.htm

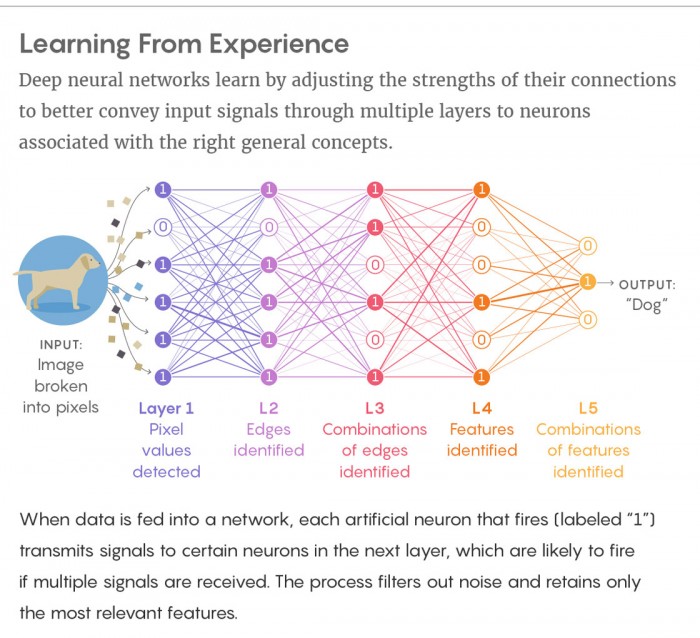
CNNs通过逐层累加调整实现分类。它首先检测到边缘,然后是形状,然后是实际的识别对象。CNN的实现方式极具创新,然而在这一过程中却有一项重要的信息丢失了——特征之间的空间关系。https://www.oschina.net/news/92998/hinton-open-source-capsule-networks
机器学习难以直面“房间里的大象”https://hot.cnbeta.com/articles/funny/771857
在计算机视觉领域,人工智能系统会尝试识别和分类对象。在这项研究中,研究人员向计算机视觉系统展示了一幅客厅的场景,系统正确的识别了椅子、人和书架上的书。研究人员随后向场景中引入了异常对象:一只大象的图像。然后 AI 系统疯了,它忘记了已经识别的对象,将椅子识别为沙发,将大象识别为椅子,其它此前已经识别的对象都视而不见了。论文合作者 Amir Rosenfeld 称,研究显示了目前的对象识别系统是多么的脆弱。研究人员仍然在尝试理解为什么计算机视觉系统如此容易犯错。他们猜测是 AI 缺乏人类那种从容处理海量信息的能力。
把大象认识成椅子,原因是什么?很简单:原来训练的图片都没有家具和大象在一起的,大多为家具和人、电视在一起。如果将物体从背景里面剥离出来,比如只包含大象,或者只包含家具,则识别率会大大提高。也就是是说这些训练数据过拟合,图片过于相识,导致沙发和椅子产生了关联性。而人因为观察角度和实际的触觉感觉,已经对沙发产生了比二位图片更为全面的信息。
再复杂的 GUI 也能搞定!西安交通大学提出前端设计图自动转代码的全新方法 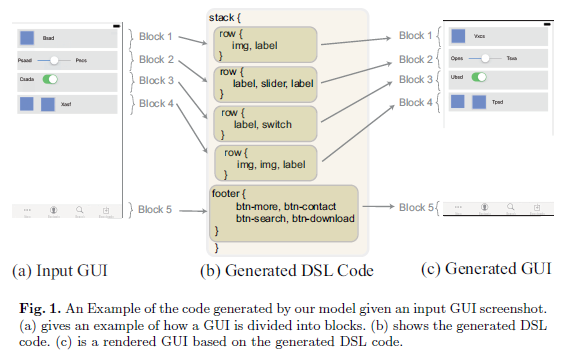 这个例子有点『走火入魔』+『手里拿着锤子哪里都是钉子』的感觉。
这个例子有点『走火入魔』+『手里拿着锤子哪里都是钉子』的感觉。
DeepMind官博详解AI打星际争霸:靠战略水平 而非手速,原文,训练需要暴雪官方大量的历史对战数据,但是 RTS 游戏和围棋差别还是很大的。
自然语言处理 NLP
图像领域深度学习已经完美解决了,文本领域则是复杂的多。图像完全可以通过像素来量化,文本则包含文字的 ASCII 码和背后含义。
NLP:经典算法·从ELMo、GPT到bert,效果逆天的通用语言模型 GPT 2.0 来了,它告诉了我们什么?
PaLM模型,还能自我解释。表面上和传统的机器人问答很像,但是其对文本进行深入的理解和组织。

机器学习基础算法
蒙特卡罗方法入门 http://www.ruanyifeng.com/blog/2015/07/monte-carlo-method.html
如何识别图像边缘?http://www.ruanyifeng.com/blog/2016/07/edge-recognition.html
理解矩阵乘法 http://www.ruanyifeng.com/blog/2015/09/matrix-multiplication.html
朴素贝叶斯分类器的应用 http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html
泊松分布和指数分布:10分钟教程 http://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html
神经网络入门 http://www.ruanyifeng.com/blog/2017/07/neural-network.html
正态分布为什么常见?http://www.ruanyifeng.com/blog/2017/08/normal-distribution.html
推荐算法不够精准?让知识图谱来解决 前员工揭内幕:10 年了,为何谷歌还搞不定知识图谱?,感觉这块人工干预太多。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。
k均值聚类(K-means) http://www.cnblogs.com/leoo2sk/archive/2010/09/20/k-means.html 这个有个例子,把几个队伍分成一流二流三流,相同的聚合在一块。和分类不同的是他们没有事先训练好的数据。
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
CDAP 举的例子是把计算一堆点的中心点。
语义分析的一些方法(一) link
API 网上算法,按调用付钱,提供了很多例子 https://algorithmia.com/
Comparison of top data science libraries for Python, R and Scala 对比了很多框架