容器网络
概述
- http://events.linuxfoundation.org/sites/events/files/slides/Container%20Networking%20Deep%20Dive.pdf
- https://blogs.vmware.com/cloudnative/2017/05/19/video-series-deep-dive-container-networking-2/
- Kubernetes OpenVSwitch GRE/VxLAN networking
- Comparison of Networking Solutions for Kubernetes
-
[最新实践 将Docker网络方案进行到底](http://blog.shurenyun.com/shurenyun-docker-133/) 写的不错,对比了各种不同网络。可以看出 ovs 和 flannel 都是“隧道网络(Overlay)”,还有一种是“路由网络”。前者是 L2 路由,后者是 L3 路由。 - Container-Native Networking - Comparison,很细致,有谈网络 feature 比如 ingress/engress,但是 ovs 谈的不多,暂时看不出来容器网络和 ovs 有啥很大区别。
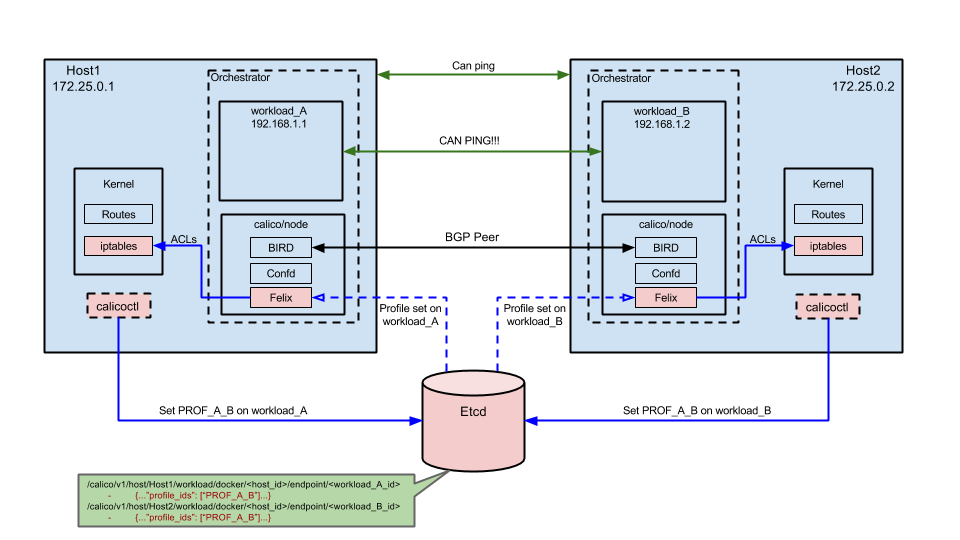
Calico - 典型的路由网络
Image come from https://docs.projectcalico.org/v1.6/reference/without-docker-networking/docker-container-lifecycle 一步一步的演示如何让容器可以 ping 通。 网络包没有像 overlay 那样需要封包和解包动作,全靠 kernel 的 iptables 来进行路由。这种基于 IP 三层网络。感觉有点像静态路由。”最新实践 | 将Docker网络方案进行到底” 这个讲了不少 Calico。如此一来,每台 host 机器上面的 iptables 会不会很巨大?因为这个要定义一对一的访问路径。”* Route Reflector(BIRD),大规模部署时使用,摒弃所有节点互联的 mesh 模式,通过一个或者多个 BGP Route Reflector 来完成集中式的路由分发。” 那这种集中式的就需要很高的转发能力了?而且还得是集群模式。route reflector - RR 似乎是交换机领域已有的东西。https://en.wikipedia.org/wiki/Route_reflector
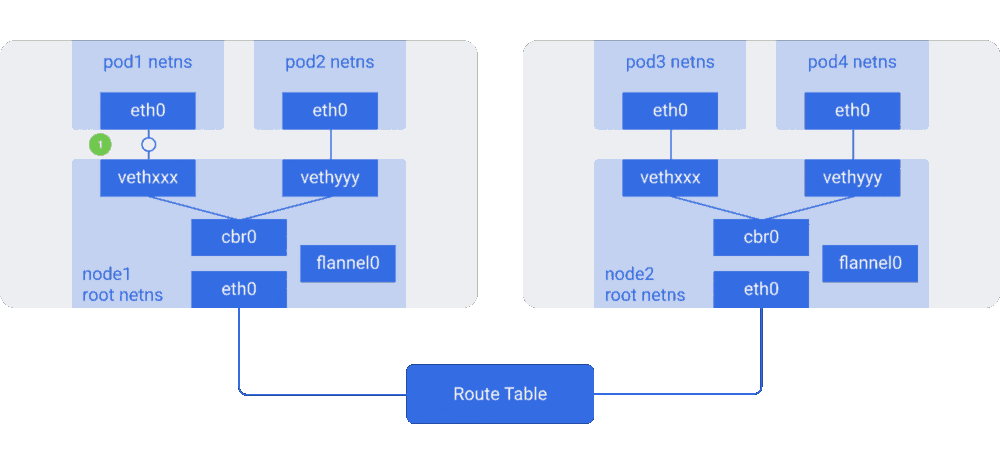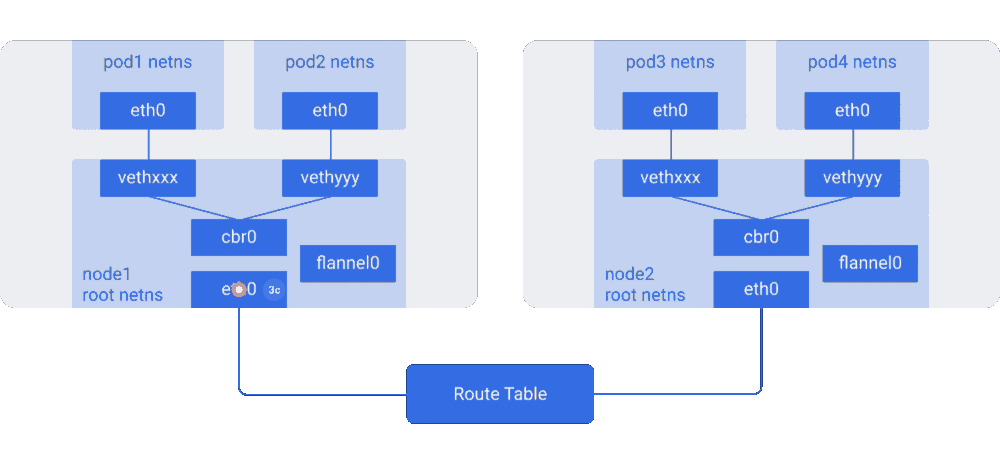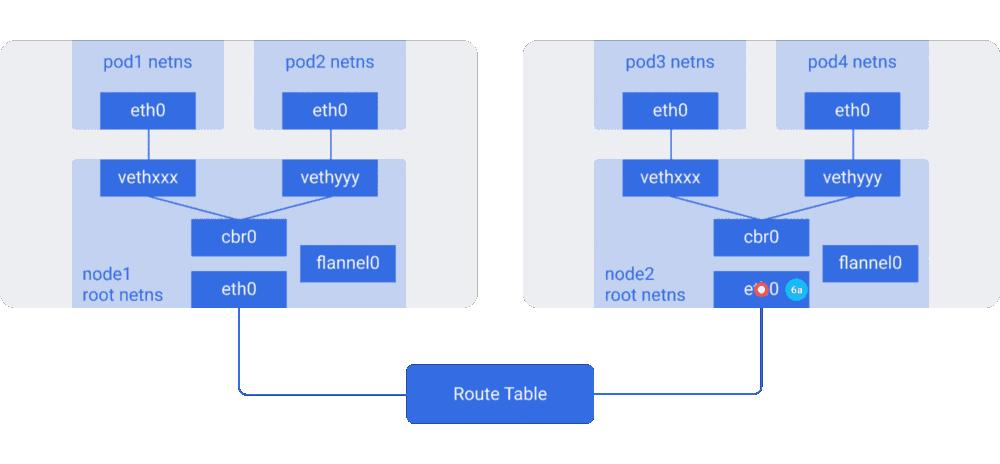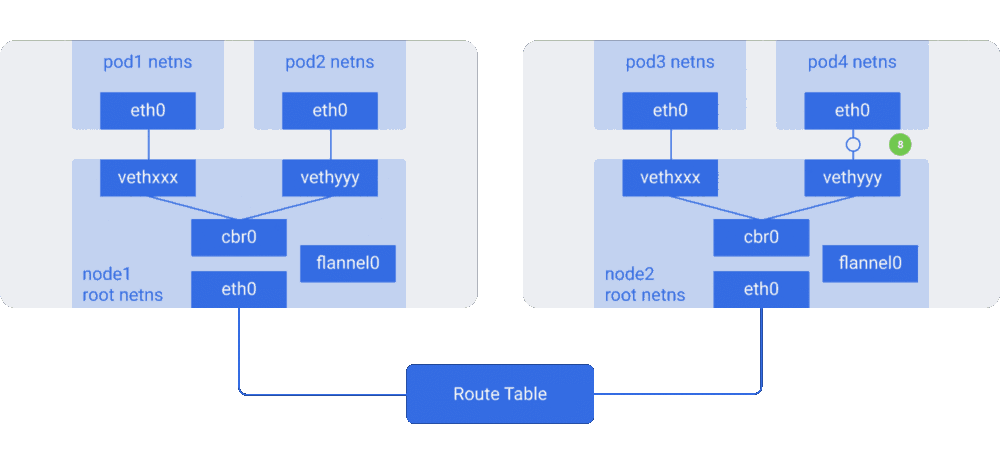
图解Kubernetes网络(二)http://dockone.io/article/3212 图解Kubernetes网络(一)http://dockone.io/article/3211
“例如,AWS路由表最多支持50条路由才不至于影响网络性能。因此如果我们有超过50个Kubernetes节点,AWS路由表将不够。这种情况下,使用Overlay网络将帮到我们。”
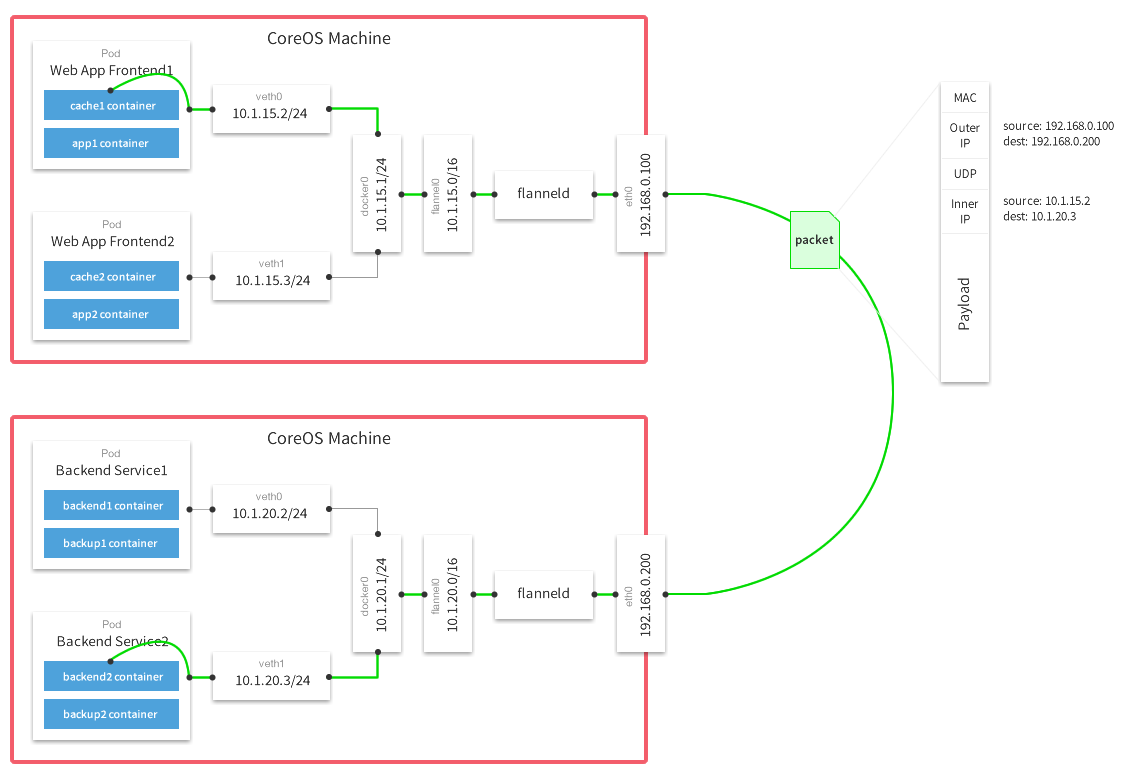
从上面这张 flannel 官网的经典之图可以看出网络包有封包和解包的过程,这个是 ovs 的特点,也没有用额外的 etcd 来保存路由规则。DockOne技术分享(十八):一篇文章带你了解Flannel Flannel通过Etcd分配了每个节点可用的IP地址段,确保他们不会重复。etcd信息会作为封包使用,否则如何知道Outer IP里面的dest IP呢?
Weave - overlay 网络
Fast Datapath & Weave Net, 因为 weave 是 overlay 网络,为了提高封包、解包的效率,这里利用了网卡的 VXLAN offload 功能。而且避免了包在用户态和核心态反复进入和出去,如果不需要进入 weave router,报文里面就包含了路由信息 - 知道怎么去目的?
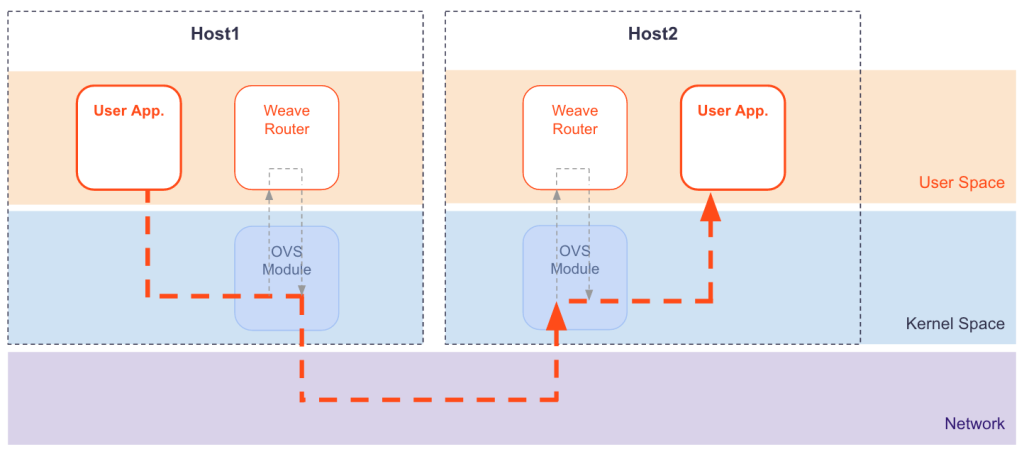
Container-Native Networking - Comparison 这里面说 Weave 不需要 etcd。https://www.weave.works/docs/net/latest/concepts/ip-addresses/ 这里看还是用 linux ip router 实现,因为他需要每个节点安装 weave-net 容器(非pod里面的sidecar),所以可以内部管理路由表。 https://www.weave.works/docs/net/latest/concepts/network-topology/ 如何组建整个拓扑,有提 spanning tree,和交换机的路由学习有点像。看看他内部是如何保存的。 在集群节点上:
[centos@k8s-2 ~]$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default OpenWrt.lan 0.0.0.0 UG 0 0 0 ens3
10.32.0.0 0.0.0.0 255.240.0.0 U 0 0 0 weave
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.51.0 0.0.0.0 255.255.255.0 U 0 0 0 ens3
[centos@k8s-2 ~]$ ifconfig
datapath: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1376
inet6 fe80::204d:80ff:fedb:65cf prefixlen 64 scopeid 0x20<link>
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ens3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.51.12 netmask 255.255.255.0 broadcast 192.168.51.255
vethwe-bridge: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1376
inet6 fe80::58c4:5bff:fe38:ddbf prefixlen 64 scopeid 0x20<link>
vethwe-datapath: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1376
inet6 fe80::eceb:49ff:fe9e:2894 prefixlen 64 scopeid 0x20<link>
vxlan-6784: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 65470
inet6 fe80::acb7:35ff:feb6:3a41 prefixlen 64 scopeid 0x20<link>
weave: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1376
inet 10.40.0.0 netmask 255.240.0.0 broadcast 10.47.255.255
Fast Datapath & Weave Net 这里说 The required open vSwitch datapath (ODP) and VXLAN features are present in Linux kernel versions 3.12 and greater,但是我在 Centos 7 kernel v3.10 里面也看到相关的内核模块。
直接查看代码 https://github.com/weaveworks/weave/blob/master/net/bridge.go
2. BridgedFastdp
+-------+ /----------\
(container-veth)-+ weave +-(vethwe-bridge)--(vethwe-datapath)-+ datapath +
+-------+ \----------/
"weave" is a Linux bridge and "datapath" is an Open vSwitch datapath; they are connected via a veth pair. Packet capture and injection use the "datapath" device, via "router/fastdp.go:fastDatapathBridge"
上面 ifconfig 里面的 datapath 是 Open vSwitch 创建的? 看来 overlay 的网络都使用了 Open vSwitch,对于 Weave 来说,只是用来封包、解包、组成隧道,但是路由是自己控制的? 每个节点上面 weave pods 里面包含了两个 Docker 容器(猜测):weave-kube & weave-npc。
通过 RIP/OSPF 来直接连接两个网络而不需要容器网络: 一条命令取代etcd+flannel,全网贯通无需端口映射。 深入理解动态选路协议——RIP、OSPF和BGP协议 http://blog.csdn.net/liao152/article/details/44919673 BGP(Border Gateway Protocol)即边界网关协议,是互联网上一个核心的去中心化自治路由协议。
Canal uses Calico for policy and Flannel for networking. 感觉很高级。
Open vSwitch
http://blog.codybunch.com/2016/10/14/KVM-and-OVS-on-Ubuntu-1604/ http://docs.openvswitch.org/en/latest/howto/libvirt/
<virtualport type='openvswitch’/> 现在改成这个了。但是 virt-manager 还是会加上一个 mode type = rtl8139。这种桥接的方式会拿到一个外网 ip。ovs-vsctl show 也会在 vm 开机后多一项。
Currently there is no Open vSwitch support for networks that are managed by libvirt (e.g. NAT). As of now, only bridged networks are supported (those where the user has to manually create the bridge).
看来 Docker 这种才会有 NAT 模式的(DHCP 获取 IP?)。一般hypervisor 自己也提供 nat,这个和 ovs 有啥区别?
Open vSwitch 感觉在 openstack 里面会用的比较多,但是对于 Docker 而言,容器网络种太多了吧,不得必须用 ovs。
在 Ubuntu* 上使用 Open vSwitch* 和 DPDK DPDK这个太高级了
OpenvSwitch实现Docker容器跨宿主机互联 http://orangebrain.blog.51cto.com/11178429/1741242 利用OpenVSwitch构建多主机Docker网络 http://dockone.io/article/228
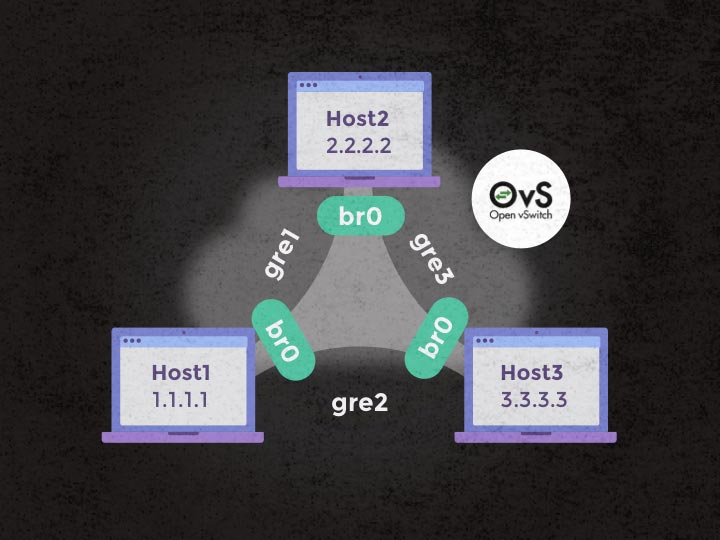
这两篇文章都是通过remote_ip来建立路由。如果新加节点,每台机器就得配置 N-1 条隧道了?Open vSwitch 只有交换功能,没有路由功能?openflow 才有路由?
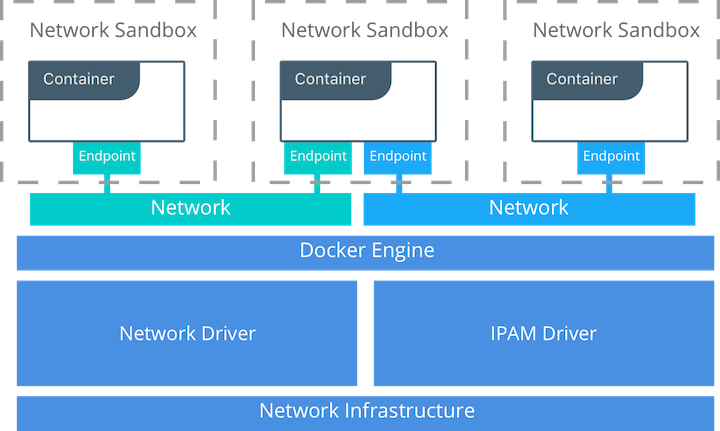
Docker Reference Architecture: Designing Scalable, Portable Docker Container Networks Docker 官方的容器网络模型
调试方法:
[centos@k8s-1 ~]$ curl 'http://127.0.0.1:6784/status'
Version: 2.5.1 (version 2.5.2 available - please upgrade!)
Service: router
Protocol: weave 1..2
Name: 16:54:5e:ad:21:d4(k8s-1)
Encryption: disabled
PeerDiscovery: enabled
Targets: 4
Connections: 4 (3 established, 1 failed)
Peers: 4 (with 12 established connections)
TrustedSubnets: none
Service: ipam
Status: ready
Range: 10.32.0.0/12
DefaultSubnet: 10.32.0.0/12
Network Policies
https://kubernetes.io/docs/concepts/services-networking/network-policies/ 这里是一个很好的测试验证的方法。如果被禁止,访问表示是一直等待到 timeout。
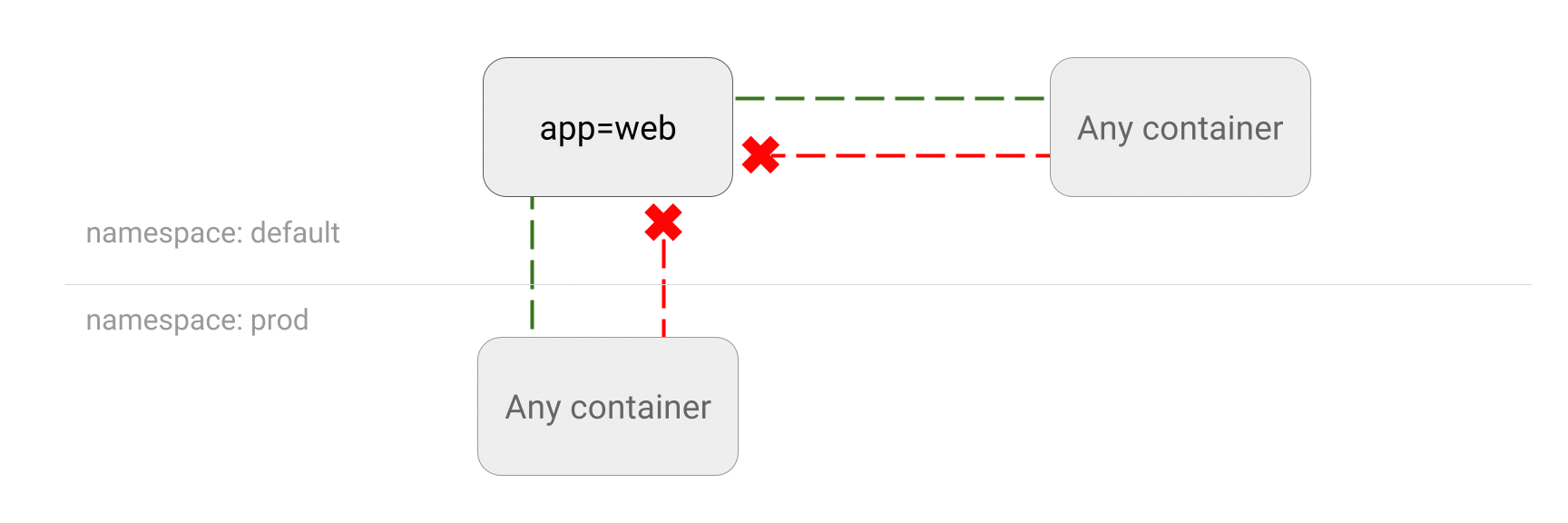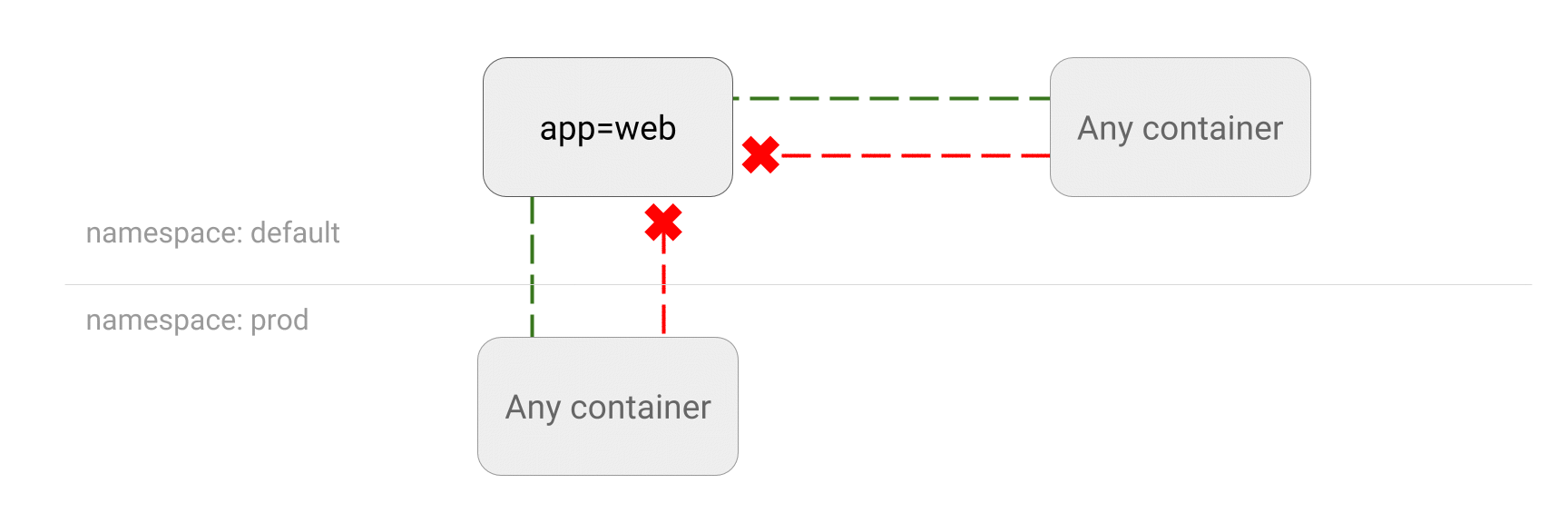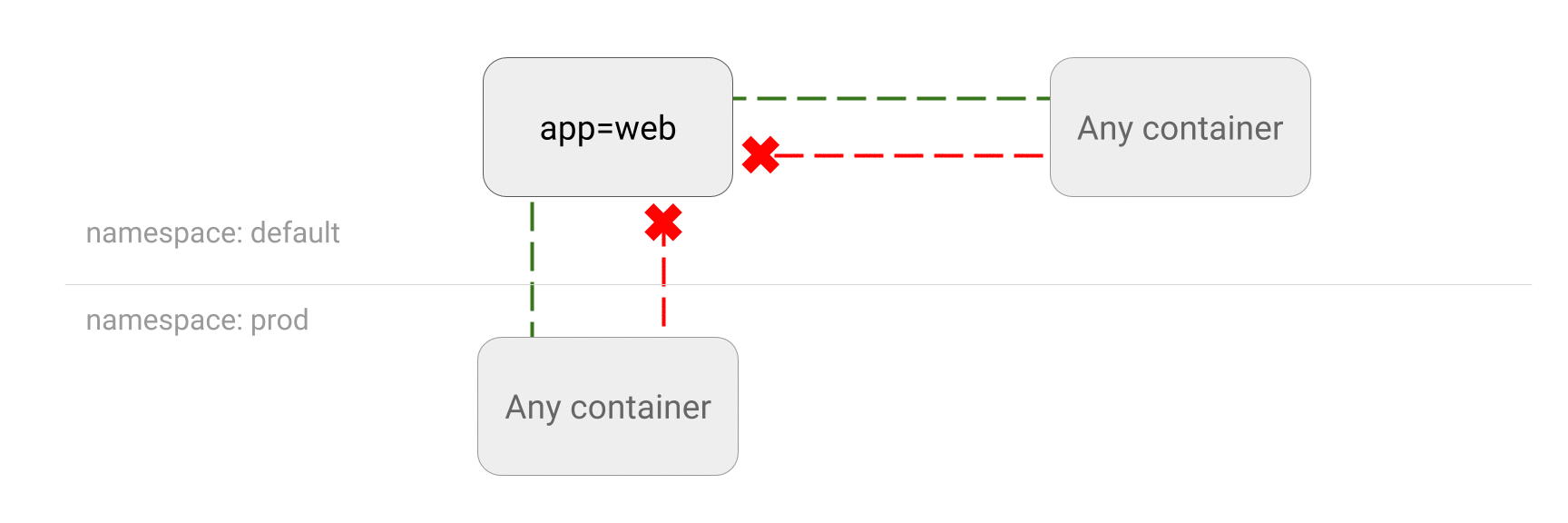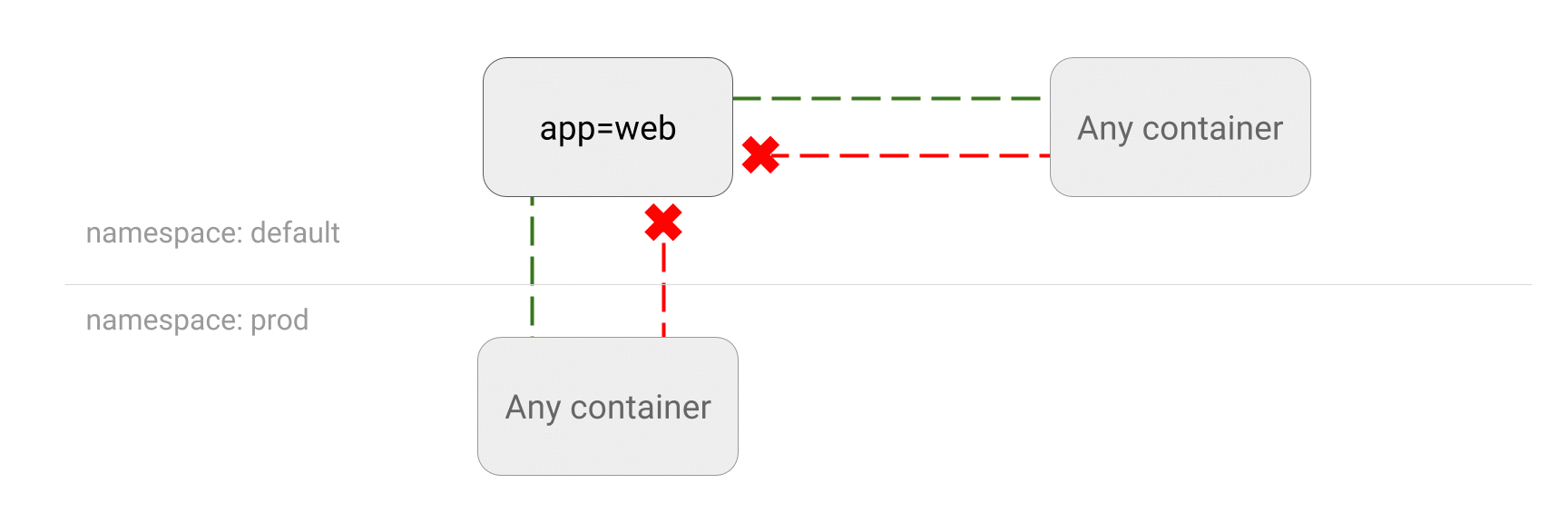
From https://github.com/ahmetb/kubernetes-network-policy-recipes 有很多例子 这个是控制 pod 之间的相互访问的网络连通性。不是所有的 CNI 都支持完整的特性。 授权管理的只能是通过 k8s api 访问资源,namespace 之间的 pod 相互访问也没有问题(?),所以这个控制的不同层面的东西。如此一来,kind: NetworkPolicy 资源需要的授权级别应该比较高了,否则这个控制就很容易突破了。
Contiv
苏宁容器云Kubernetes + Contiv网络架构技术实现 京东也用 Contiv,感觉这帮人都是从 OpenStack 出来的吧。部署kubernetes1.8.4+contiv高可用集群,容器网络插件 Calico 与 Contiv Netplugin深入比较。苏宁容器云基于Kubernetes和Contiv的网络架构技术实现,
实现了Pod-IP固定、网络双向限速、支持租户隔离、支持多种虚拟网络加速等需求进行定制。
Cilium
L3 路由,但是特殊的地方是使用eBPF/XDP 处理数据包,这个性能比较强。最Cool Kubernetes网络方案Cilium入门,官方介绍,居然有中文。原来最新Calico也支持BPF。 具备 API 感知的网络和安全性管理的开源软件 Cilium Cilium使用 (Cilium 3)