从 GraphQL 到 Serveless
定义
GraphQL 客户端指定查询(Client Specified Queries)
http://graphql.org/learn/ GraphQL是Facebook于2012年创建并于2015年开源的一套查询语言API规范。GraphQL的类型系统允许开发者自己定义数据schema,可以增加新字段,也可以删除旧字段,这些都不会影响已有的查询,也不需要修改客户端。GraphQL非常强大,因为它没有与特定的数据库或存储引擎绑定在一起。 GraphQL服务器使用一个单独的端点来提供所有的功能。只要定义好资源之间类型和字段的关系(这个与REST端点不太一样),GraphQL就可以跟踪属性之间的关系,在单个查询中从多个资源获取数据。在使用REST时,可能需要为单个请求加载多个URL,这样不仅增加了网络跳转,还拖慢了查询速度。通过减少网络跳转,GraphQL降低了单个数据请求所要耗费的资源。GraphQL返回的数据通常是JSON格式。 使用GraphQL还有其他好处。首先,客户端和服务器端之间解耦开了,这样就可以分开维护。GraphQL使用相似的语言进行客户端与服务器端之间的通信,所以调试更加容易了。查询结构与服务器端返回的数据结构完全匹配,因此,相比其他语言,如SQL或Gremlin,GraphQL更加高效。查询本身就反映了响应消息的结构,所以可以很容易地检测出差异,如果没有正确处理某些字段也可以很容易识别出来。因为查询更简单了,整个流程也变得更稳定。虽然说GraphQL规范主打支持外部API,但我们发现将它用在内部API中也很不错。 GraphQL的用户包括Amplitude、Credit Karma、KLM、纽约时报、Twitch、Yelp等。去年11月,亚马逊推出的AppSync就提供了GraphQL支持,可见它有多么流行。在存在gRPC和Twitch Twirp这些RPC框架的前提下,看着GraphQL的发展真是一件有趣的事情。http://www.infoq.com/cn/articles/5-microservices-trends-to-watch-in-2018
https://developer.github.com/v4/guides/intro-to-graphql/ GitHub已经换成这个,其也提供直接运行测试的 web ui,很不错。 GraphQL API Explorer 编辑器 https://developer.github.com/v4/explorer/
query {
repository(owner: "facebook", name: "react") {
name
nameWithOwner
description
}
}
也能做 request schema 校验,比如查询必填项、返回字段名,相当于对接口静态类型化,能提高编程效率。上面查询条件中 name 是必填的,如果没有,界面会马上给出校验错误。返回字段中如果随便填了字段页会马上给出错误提示。这说明这个 query 是预先声明式定义好的。这可能是 introspection 的特征:能了解 API 的各种细节。
Relay 是连接 GraphQL 和 React 的一座桥梁。GraphQL能取代 Redux吗? 这是一类东西?因为 React 对数据/状态管理是很严格的,所以新的数据模型必然要 React 重新适应了。
Linux基金会宣布将为GraphQL成立基金会,惹的我又看了看这个技术,想想最近的很多后端工作都是把几条数据合在一起然后返回这种琐碎的事情。比如 A 包含多个 B,在显示 A 详细信息的时候,也顺带显示全部的 B 列表,而原来是分开成两个 API。类似的各种组合很多,后端改起来如果熟悉的很快,但是调试-测试-部署这个效率太低。GraphQL 能做到这点?能有多大的灵活性?前面是做个请求的组合例子,对于多个请求顺序连接,比如 A 成功了在做 B 再做 C,GraphQL有没有类似优化呢?
type Document {
title: String!
content: String!
author: User!
}
如此就简单的定义了关系,这大概也是 Graph - 图关系的来源。比如在 github 中查询某个仓库下面的前10个 issue:
{
repository(owner: "facebook", name: "react") {
name
nameWithOwner
description
createdAt
updatedAt
issues(first: 10) {
nodes {
title
number
state
}
}
}
}
其对于错误的处理也很有启发,比如查询一个不存在的 issue:
{
repository(owner: "facebook", name: "react") {
name
nameWithOwner
description
createdAt
updatedAt
issue (number: 23){
title
number
state
}
}
}
其返回的错误信息:
{
"data": {
"repository": {
"name": "react",
"nameWithOwner": "facebook/react",
"description": "A declarative, efficient, and flexible JavaScript library for building user interfaces.",
"createdAt": "2013-05-24T16:15:54Z",
"updatedAt": "2018-11-07T07:18:01Z",
"issue": null
}
},
"errors": [
{
"message": "Could not resolve to an Issue with the number of 23.",
"type": "NOT_FOUND",
"path": [
"repository",
"issue"
],
"locations": [
{
"line": 8,
"column": 5
}
]
}
]
}
部分正确,部分为空。Kubernetes Dashboard Go Backend 里面有很多这种做法。OpenAPI 标准么?
现在前端是方便了,后端呢?感觉这个地方在对于数据关系的处理会很麻烦,要考虑各种情况。一种新的编程模型了。 https://github.com/chentsulin/awesome-graphql 云计算领域遇到的似乎不多,大多为大的公有服务比如 GitHub。有没有好的后端例子呢? Kubernetes + GraphQL https://github.com/yipeeio/kubeiql 关注不多,『The goal of this project is to provide an alternative GraphQL interface to a Kubernetes cluster. It is not intended to entirely replace the ReST APIs as some of them (particularly the watch APIs) don’t map well onto GraphQL.』* Queries are currently supported against Pods, Deployments, ReplicaSets, StatefulSets, and DaemonSets. 按理来说这种层级关系多的用 GraphQL 是很贴合的。
有 schema / query 定义的文件么?最好和 Swagger 一样能直接生成代码。
Hasura - Instant Realtime GraphQL on Postgres
我用的是 k8s 安装 https://docs.hasura.io/1.0/graphql/manual/deployment/kubernetes/index.html https://github.com/hasura/graphql-engine Haskell, Go, JavaScript,好吊的项目
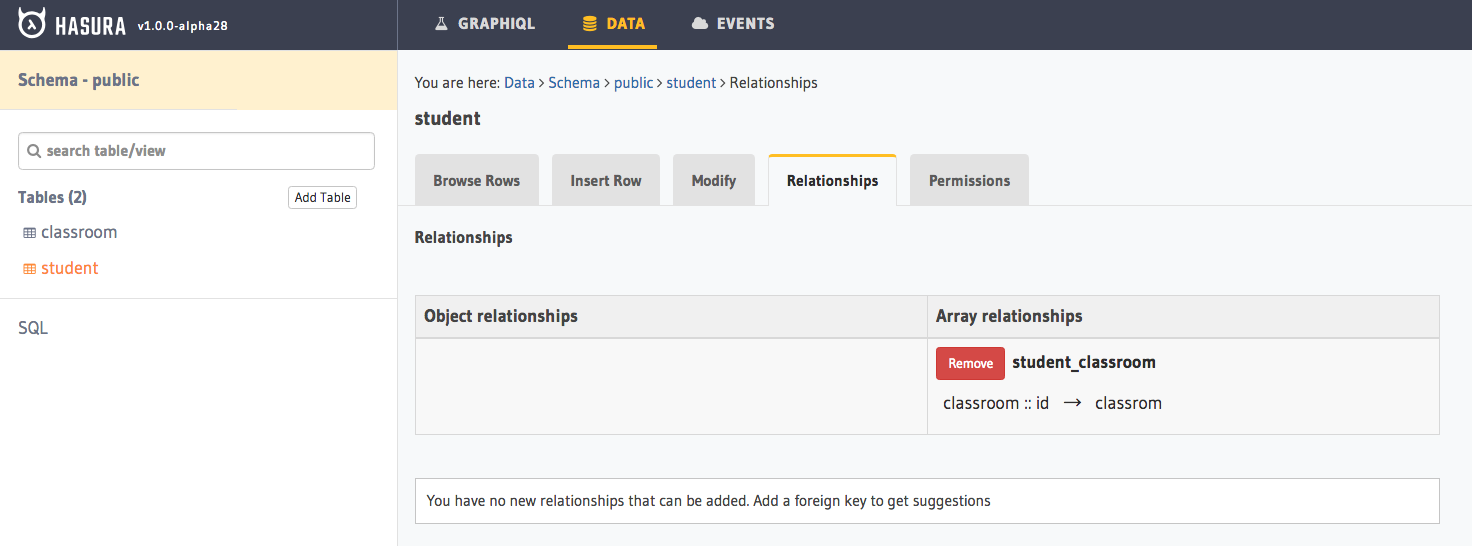
在 student 中加了这个关系后,GraphQL 编辑器中才可以这样写:
query {
student(limit: 10) {
name
student_classroom{
name
}
}
}
我看了下,在 Postgres 中并没有建立外键,看了是 Hasura 自己维护的关系,而且在 query classroom 中并没有自动的建立反向的关系。(页面上似乎由地方可以根据数据库的外键关系,点击『add』按钮自动把关系同步到 engine 里面来。)
其部署架构为:
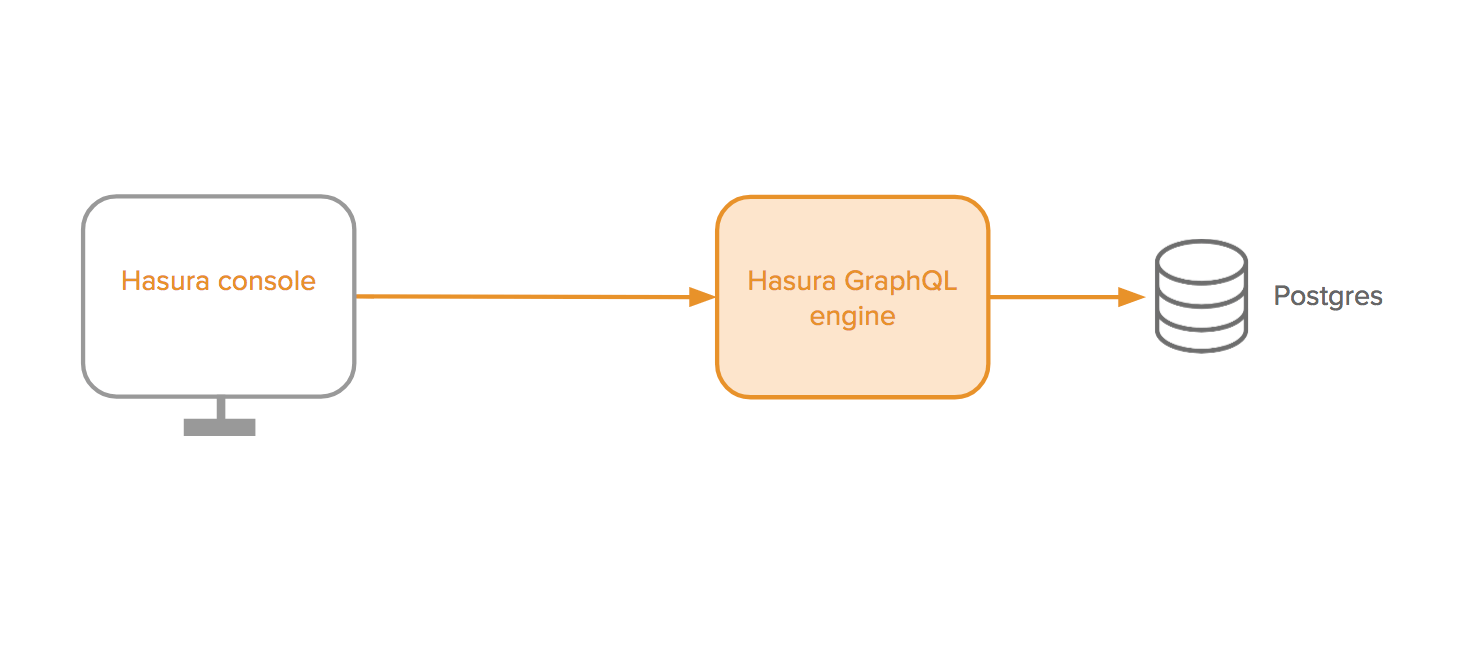
对已有的 Postgres 的一个 GraphQL 代理,但是 Hasura 需要维护 table schema,其本身提供创建 table 和定义 schema 的功能。也可以导入或者导出 Hasura Metadata - it stores information about your tables, relationships, and permissions that is used to generate the GraphQL schema and API.。 为什么不扩展到任意的关系数据库呢?

来源:https://github.com/hasura/graphql-engine 支持第三个认证,原来有个 GraphQL Proxy 的东西,数据库走向微服务化了啊!
Trigger webhooks or serverless functions: On Postgres insert/update/delete events https://github.com/hasura/graphql-engine/blob/master/event-triggers.md 一个有趣的 feature,Building reactive UX for your async backend with realtime GraphQL 这个 event triggers 是 Postgres 的专有特性么? 要这个搞啥呢?实时的数据监控应用?前后端的一整套方案,能减少开发时间。 GraphQL 可以有订阅功能?
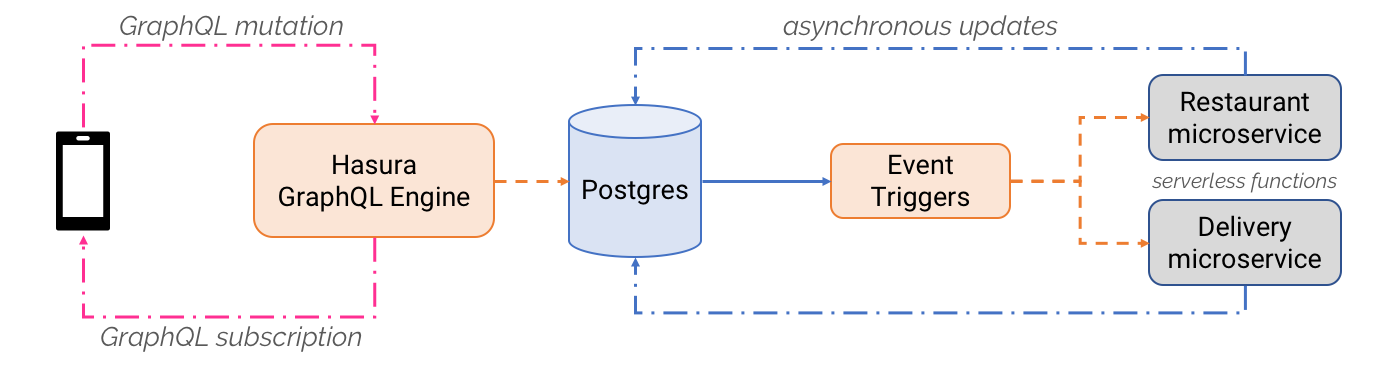
他也提供了一个很好的 demo https://github.com/coco98/hasura-serverless,可以直接运行。运行时会起一个 web socket:
wss://serverless-demo.hasura.app/v1alpha1/graphql
这样页面能跟随数据实时变化。 如上图所示,前端只和 Hasura Engine 打交道,mutation[基因突变,这些人调皮] 用来创建一个订单,尔后都都是自动触发的,被触发的都是 Node.js serverless function,部署在 aws上面,部署好后地址填入 GraphQL Engine Events 界面,这些微服务后也会发送一个 mutation 请求回来,来修改数据库,这样就会触发 graphql subscription。 如果我自己在 postgres client 里面修改了数据,会触发消息么?应该会,那这个消息触发是 Postgres 自己带的功能了?
其 UI 的代码主要基于 https://www.apollographql.com/docs/react/ Apollo Client is the best way to use GraphQL to build client applications. 支持上面提到的 Mutation, subscriptions.这个 GraphQL 生态似乎很成熟了啊!
上图的 engine 和 postgres 是自己部署在一起的一个服务(不是无服务化的),可以是企业内部数据库,搞混合云么?其实这块如果用 aws 提供的 k-v db 也可以做到无服务化,为什么没有做呢?企业内部数据库无疑了。如此一看,这个 Hasura 的目的就很清楚了,原来是做无服务化的。既然如此,就应该支持遗留数据库比如 MySql 了,这个保有量应该很大了。提了一个 issue Any plan to support other db like MySql?
这个架构能加快开发效率,但是对于性能呢?serverless 放在最后而不是最前,serverless 的异步更新访问的是 graphql engine,这导致压力都在 graphql engine ,很大瓶颈。不过既然数据库这块是独立部署,性能应该不差。首页说这个可以运行在 Heroku Free Tier (dyno + postgres),开发者不会是羊毛党吧😂。
对于 serverless 反向访问,如何进行安全控制?OpenId?
Azure API Management
Modernize your API stack with GraphQL and Azure API Management | Azure Friday
看上去能聚合各种API,只需很少的代码就能重组API。所以其成功与否取决于这种方式到底有多大的灵活性。
Think
薄薄的一层前端控制层,BFF, Backend For Frontend(服务于前端的后端)。其鸡肋不在于开发的重复劳动,而在于开发的效率。对于存在核心 API 的这种,BFF 作为前端和核心 API 的中间层,反复的调试和发布都是很耗时的,更不要谈接口变化了。 缺点么:对前后端都有侵入性,是一套方案。 如果反向代理比如 Nginx 在前后端分离中的角色是 HTTP 代理(网络层),GraphQL 就是更上一次的应用层(数据层)的代理。