Install Kubernetes by kubeadm
安装
总文档 https://kubernetes.io/docs/setup/independent/install-kubeadm/
因为 master 上面有多个 ip,所以 init 的加了参数(后来证明这很机智):
kubeadm init --api-advertise-addresses 192.168.51.132
节点加入的时候:
[discovery] Failed to request cluster info, will try again: [Get http://192.168.51.132:9898/cluster-info/v1/?token-id=2ffc9b: dial tcp 192.168.51.132:9898: getsockopt: connection refused]
显示 pods 状态时看到 romana 是 error。换一个 net:kubectl apply -f https://git.io/weave-kube,这次运行 kubectl get pods --all-namespaces 没有错误了。然后节点加入时就没问题了。
再次加入是如果token忘记了,要重新产生。
kubeadm token generate
kubeadm token create <generated-token> --print-join-command --ttl=0
常用命令:
kubectl get nodes
kubectl get pods --all-namespaces
kubectl describe nodes kubernete-1
Capacity:
alpha.kubernetes.io/nvidia-gpu: 0
cpu: 4
memory: 1883448Ki
pods: 110
这台 master 主机上面有 gpu,但是怎么在 kvm 节点间共享呢?上面的文字表示现在已经有方法了?后来找了台节点,上面有 GPU,不过还是显示不出来,看来 gpu 还是要额外配置了。
现在发现自己 create 的 pod 状态都是 creating,
kubectl describe -n kube-system pod kubernetes-dashboard-3203831700-n2wd7
kubectl logs -n kube-system kubernetes-dashboard-7955b65d66-rc6ns
Error syncing pod, skipping: failed to "SetupNetwork" for "kubernetes-dashboard-3203831700-n2wd7_kube-system" with SetupNetworkError: "Failed to setup network for pod \"kubernetes-dashboard-3203831700-n2wd7_kube-system(5fda6401-fd92-11e6-9832-525400232486)\" using network plugins \"cni\": unable to allocate IP address: Post http://127.0.0.1:6784/ip/e87f63d5e3fe2d7c9a8a50dfd816a46c98b94d1760ed424a972a4eb5df69d369: dial tcp 127.0.0.1:6784: getsockopt: connection refused; Skipping pod”
什么鬼,还是拿不到 IP?
[root@kubernete-1 vagrant]# kubectl get pods -n kube-system -o wide | grep weave-net
weave-net-7wwm6 2/2 Running 2 3h 192.168.121.205 kubernete-1
weave-net-wsx32 1/2 CrashLoopBackOff 25 3h 192.168.121.79 localhost.localdomain
非master node的weave挂了,master是好的。 可能是我的机器有多个网络设备的原因。https://github.com/kubernetes/kubernetes/issues/34101 这里讨论了很多。感觉还不如直接用 https://github.com/clifinger/vagrant-centos-kubernetes 这个。
weave troubleshot 方法 https://www.weave.works/docs/net/latest/kube-addon/ 。log 在 dashboard 上面也可以查看。 我把上面clifinger 的库里面的 install.sh 的 “$1” == “-master” 一段胡乱运行了一遍:
kubectl -n kube-system get ds -l 'component=kube-proxy' -o json \
| jq '.items[0].spec.template.spec.containers[0].command |= .+ ["--proxy-mode=userspace"]' \
| kubectl apply -f - && kubectl -n kube-system delete pods -l 'component=kube-proxy'
cp /etc/kubernetes/admin.conf /shared
这个 shell 是根据 json path 添加了一个参数到 kube-proxy 命令,删除后系统会自动重建 kube-proxy pod。然后回家吃饭。现在洗完澡发现所有的 pod 都在 running 运行状态了。 https://dickingwithdocker.com/deploying-kubernetes-1-4-on-ubuntu-xenial-with-kubeadm/ 这里也有同样的问题,用的类似的方法解决。
Dashboard
https://github.com/kubernetes/dashboard
kubectl describe svc kubernetes-dashboard -n kube-system
Name: kubernetes-dashboard
Namespace: kube-system
Labels: app=kubernetes-dashboard
Selector: app=kubernetes-dashboard
Type: NodePort
IP: 10.100.11.211
Port: <unset> 80/TCP
NodePort: <unset> 31755/TCP
Endpoints: 10.44.0.40:9090
Session Affinity: None
No events.
然后可以外网访问 http://192.168.51.132:31755 (这个是 master ip 还是 node IP?)(现在需要加 https,而且需要修改yaml让type为nodePort)
默认 yaml 需要添加一行:
# ------------------- Dashboard Service ------------------- #
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
这样端口类型就成了 node port,然后就可以不需要 Proxy 直接端口访问。
dashboard 在 node1节点上,某天我没有起这个节点。这个时候系统自动创建了一个 pod,但是有错误 ImagePullBackOff,node1 上面对应的 pod 状态为 Unknown。我猜可能是因为现在系统唯一可以用(默认 master 是 dedicated 的)的是一个 arm rpi 节点。然后我加入一个 amd64节点,系统卡在这里,并没有在新节点上试一试。kubectl delete -n kube-system po kubernetes-dashboard-3203831700-c44b8 删除之(注意要加 namespace),系统马上创建了一个新的 dashboard pod。但是 masterip:NodePort 还是无法访问,nodeip:nodeport可以访问。poweroff amd64 node。kubectl get nodes 马上显示为 NotReady,但 dashboard pod 还是 Running,只是 kubectl describe svc kubernetes-dashboard -n kube-system 里面的 Endpoints 已经为空。过了大概 5 分钟,状态才变为 Unknown,然后开始创建新的 pod。
kubectl delete -f kubernetes-dashboard.yaml 只能用这种方式删除,特么的。
1.7 添加了很多安全的东西,现在我打开网页,得到错误:
warningUser "system:bootstrap:91765f" cannot list roles.rbac.authorization.k8s.io at the cluster scope. (get roles.rbac.authorization.k8s.io)close
warningUser "system:bootstrap:91765f" cannot list clusterroles.rbac.authorization.k8s.io at the cluster scope. (get clusterroles.rbac.authorization.k8s.io)
https://github.com/kubernetes/dashboard/wiki/Installation Alternative setup 这里关闭了安全设置。按照这里重新部署后这次不要https了,但是还是报上面一样的错误。我日。
https://github.com/kubernetes/dashboard/wiki/Access-control 这里看来还要配置访问的 bearer token,但是这 token 权限粒度很细,后来直接用Admin privileges方式,这样首页就可以点击 skip 了。赋予 dashboard admin 权限也是用 yaml 方式,很奇特的交互方式。这个是 k8s 所谓的“声明式 API”,关注的是 what,而不是 how(命令式)。声明式相当于需求说明书,怎么完成我不关心;而命令式则是事无巨细的控制。
Sock Demo
[root@kubernete-1 vagrant]# kubectl describe svc front-end -n sock-shop
Name: front-end
Namespace: sock-shop
Labels: name=front-end
Selector: name=front-end
Type: NodePort
IP: 10.97.42.96
Port: <unset> 80/TCP
NodePort: <unset> 30001/TCP
Endpoints: 10.44.0.33:8079
Session Affinity: None
No events.
只有 curl [http://10.44.0.33:8079](http://10.44.0.33:8079/) 这个可以,master_ip:30001不行啊。http://192.168.51.132:30001/ 这种 host 主 ip 地址可以。
micro service demo https://github.com/microservices-demo/microservices-demo 这个好屌,能在多个平台上部署。
https://microservices-demo.github.io/docs/index.html 几种部署方法网络用的都是 weave。
详细 DEMO 解析见 Sock Shop Microservices Example
加一个 Raspberry Pi 节点 试试看
https://blog.hypriot.com/getting-started-with-docker-on-your-arm-device/ pirate:hypriot
安装很顺利。k8s 对 arm 架构支持的很完善。但是其 weave 还是 CrashLoopBackOff 状态,和前面一样的问题。用同样的方法还是老问题,怎么办。
2017-03-02T07:41:48.109827025Z 2017/03/02 07:41:48 error contacting APIServer: Get https://10.96.0.1:443/api/v1/nodes: dial tcp 10.96.0.1:443: i/o timeout; trying with fallback: http://localhost:8080
感觉如果 master 有多个网卡,部署会有各种问题,即使我在 init 的时候指定了 network interface 也一样。好吧,重新用 vagrant 做个,这次做好后我删除 vagrant nat interface,然后用 virt-manager 管理。
结果这次连 join 都不行:
[discovery] Failed to request cluster info, will try again: [Get http://192.168.51.113:9898/cluster-info/v1/?token-id=790772: dial tcp 192.168.51.113:9898: getsockopt: connection refused]
换成 kubeadm init --api-advertise-addresses 192.168.51.113,再来过。
这次节点 join 就可以了,不用修改 kube-proxy 的配置。可能是 init 时候加了 ip 的原因,也可能是我先关了防火墙配置。网上看 centos 问题挺多。
[root@k8s-master ~]# netstat -ltpn | grep 9898
tcp6 0 0 :::9898 :::* LISTEN 15516/kube-discover
可以看到9898端口。为什么前面的连这个端口都没有。
rpi 还是一样的问题。我另外找了台 Ubuntu 的物理机,可以加入,weave pod 也是好好的,没有任何问题。什么鬼呢?然后根据 Limitation 里面提示,发现这台 rpi 上面的 hostname -i 返回 127.0.0.1,改好后返回真实外网 ip,但问题依旧。后来发现这节点上面没有 kube-proxy pod,没有这个也有可能 ping 不通10.96.0.0 的 ip。也没有 kube-proxy 进程。docker ps 只有 2 个,正确的有 5 个。也有可能是 weave 创建好了再创建 kube-proxy。然后我在 kubectl -n kube-system get ds -l ‘component=kube-proxy’ -o json 返回里面发现 kube-proxy “image”: “gcr.io/google_containers/kube-proxy-amd64:v1.5.3”, 没有 ARM 版本的?https://console.cloud.google.com/kubernetes/images/list?location=GLOBAL&project=google-containers 这个下面有 ARM 版本的。但是我觉得这个 kube-proxy 只是在 master 创建时用的配置?
https://github.com/luxas/kubernetes-on-arm 这个master 和 node 都是 ARM 版本的。没有混合的了?有点,他有写。
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/multi-platform.md 这里也有写,不过网络只能用 flannel。但是我看 arm 上面已经自动创建了 weave 的 pod,难道是假的?
接下来部署一个小应用到这个节点上。Assigning Pods to Nodes https://kubernetes.io/docs/user-guide/node-selection/
Play on ARM
2 odroid, install Docker CE 17.03 recommended currently. xenial(Ubuntu 16.04) is currently supported version. Odroid-1t as master node.
The connection to the server localhost:8080 was refused - did you specify the right host or port? ==> export KUBECONFIG=/etc/kubernetes/admin.conf
使用 weave 网络。join 的时候没有问题,但是创建 dashboard 的时候出现问题:
Warning FailedCreatePodSandBox 6m kubelet, odroid Failed create pod sandbox.
Warning FailedSync 6s (x4 over 6m) kubelet, odroid Error syncing pod
Normal SandboxChanged 5s (x4 over 6m) kubelet, odroid Pod sandbox changed, it will be killed and re-created.
回过头来看这个其实是因为 dashboard deployment 里面指定用 amd64 image,换成 arm 即可。现在 (k8s 1.13.0) 搭建集群很成熟了,主要问题是很多镜像都没有 arm 版本。
1.8.4 还要 disbale swap,特么的。(vm 的 swap 是关闭的,直接就可以用)然后在 amd64上面又试了下,还是各种问题。我需要全新的机器来么?还是 kubeadm 不太稳定?
x64 + arm
https://github.com/kubernetes/kubernetes/issues/64234 一运行kubelet就报错,要降到低版本。
standard_init_linux.go:195: exec user process caused “exec format error” 看来还是二进制文件不对。
gcr.io/google_containers/kube-proxy-amd64:v1.10.4 这个是daemonset创建的,不能改其定义,因为其也负责其他的 x86 kube-proxy创建。直接编辑pod定义,amd64->arm。好了。
weave现在支持arm了,weaveworks/weave-kube:2.3.0,统一地址都是这个,👍。上面问题是kube-proxy的bug?hub docker.com 可以根据客户端类型返回对应Image? quay.io 不会编译所有平台的,但是 docker hub 不支持 CI 吧,都是开发者自己 push 的。https://hub.docker.com/r/giantswarm/tiny-tools/ 这个是automated build的。
改成 gcr.io/google_containers/kube-proxy:v1.10.4,虽然浏览器直接访问可以浏览,不行。
这两个都是daemonset,守护进程集,这个都会运行在每个node 上面?
Change hostname, 重启后发现两个pod 都无法起来,the server could not find the requested resource ( pods/log kube-proxy-4kwfd),重新kubeadm reset & join,发现原来kubectl get nodes显示都是和hostname 关联起来的。
Upgrade
kubeadm upgrade apply stable https://kubernetes.io/docs/tasks/administer-cluster/kubeadm-upgrade-1-9/ 它会让你先升级 kubeadm,似乎 kubeadm 版本是和 k8s 一一跟随的。 Upgrading your Static Pod-hosted control plane to version “v1.9.2”… 每个 client node 也要自己手动升级么? 升级不能跳跃小版本,比如 v1.11 只能先升级到 v1.12,然后再升级到 v1.13。
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets in turn.
可以啊!这都能升级!不过这 kubelets 是啥东西?
Join failed:
[preflight] Running pre-flight checks.
[WARNING Hostname]: hostname "k8s-4" could not be reached
[WARNING Hostname]: hostname "k8s-4" lookup k8s-4 on 192.168.51.1:53: no such host
[preflight] Some fatal errors occurred:
[ERROR CRI]: unable to check if the container runtime at "/var/run/dockershim.sock" is running: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=…`
[root@k8s-4 centos]# kubeadm join 192.168.51.11:6443 --token 7c6192.tis6ip34uslrgi0u --discovery-token-ca-cert-hash sha256:9fc0dcbe36a1d3df41941ae63e34bbb3d2078e2e656efbf4beaae96dee275c48 --ignore-preflight-errors cri
https://mp.weixin.qq.com/s/8bW-Et9WHVgQ8O2JwJarUw Kubernetes 1.11 终于等到你。主要是 coredns 和 ipvs 支持。其中 coredns 已经作为默认组件。https://github.com/kubernetes/kubernetes/tree/master/pkg/proxy/ipvs 这里有些如何切换的方法,还挺复杂。
对于 kubeadm 已经安装好的,运行 kubectl edit configmap kube-proxy -n kube-system,然后修改里面 mode: “ipvs”。(如果 ipvs module 正常被 load,这里修改可能不是必须的,因为 v1.11 默认是启用的)重启后查看 kube-proxy log:
Failed to load kernel module ip_vs_wrr with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
can't determine whether to use ipvs proxy, error: IPVS proxier will not be used because the following required kernel modules are not loaded: [ip_vs_rr ip_vs_wrr ip_vs_sh ip_vs]
我看 /lib/modules 已经 mount 了啊,按道理来说容器里面的代码会操作 host 的 kernel module,但是没有发生。我在 host 里面手工 modprobe 是可以但是不优雅。容器里面运行:
modprobe -v ip_vs_wrr
insmod /lib/modules/3.10.0-693.11.6.el7.x86_64/kernel/net/netfilter/ipvs/ip_vs_wrr.ko.xz
modprobe: ERROR: could not insert 'ip_vs_wrr': Exec format error
host 上面运行就可以。如果 host 已经 modprobe 了,上面也不会报错。原因在于:modprobe in gcr.io/google-containers/kube-proxy-amd64:v1.9.2 is not compiled with CONFIG_MODULE_COMPRESS, so that loading compressed kernel modules on hosts is not supported. 这个只在 centos 才有这个问题?难道只有 centos 用压缩的内核模块。只能自己先修改 host 配置:
[root@k8s-1 containers]# cat /etc/modules-load.d/ipvs.conf
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs
但是有的节点 kube-proxy 启动出现一堆错误:
Failed to make sure ip set: KUBE-NODE-PORT-LOCAL-TCP bitmap:port inet 1024 65536 0-65535 Kubernetes nodeport TCP port with externalTrafficPolicy=local map[] 0xc420596440 exist, error: error creating ipset KUBE-NODE-PORT-LOCAL-TCP, error: exit status 2
ipset 不支持 comment 语法,这个问题不是说 1.11.1 已经解决了么?k8s.gcr.io/kube-proxy-amd64:v1.11.2 要换成这个最新稳定版本,直接修改 kubectl edit pod kube-proxy-xxx(这 POD 的参数定义在哪里?/etc/kubernetes/ 下面没有)。这个 ipvs 如果工作不正常,连 weave 也不正常。现在 ipvsadm -ln 会返回一堆东西。
[centos@k8s-1 ~]$ kubectl log kube-proxy-t8zj4 -n kube-system
log is DEPRECATED and will be removed in a future version. Use logs instead.
I0823 07:38:19.917429 1 server_others.go:183] Using ipvs Proxier.
W0823 07:38:19.941986 1 proxier.go:349] clusterCIDR not specified, unable to distinguish between internal and external traffic
W0823 07:38:19.942013 1 proxier.go:355] IPVS scheduler not specified, use rr by default
I0823 07:38:19.942160 1 server_others.go:210] Tearing down inactive rules.
I0823 07:38:20.017820 1 server.go:448] Version: v1.11.2
I0823 07:38:20.039200 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072
I0823 07:38:20.039297 1 conntrack.go:52] Setting nf_conntrack_max to 131072
I0823 07:38:20.039371 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_established' to 86400
I0823 07:38:20.039411 1 conntrack.go:98] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_close_wait' to 3600
I0823 07:38:20.042981 1 config.go:202] Starting service config controller
I0823 07:38:20.043016 1 controller_utils.go:1025] Waiting for caches to sync for service config controller
I0823 07:38:20.043549 1 config.go:102] Starting endpoints config controller
I0823 07:38:20.043568 1 controller_utils.go:1025] Waiting for caches to sync for endpoints config controller
I0823 07:38:20.150279 1 controller_utils.go:1032] Caches are synced for service config controller
I0823 07:38:20.150367 1 controller_utils.go:1032] Caches are synced for endpoints config controller
1.11 改用 coredns 后,pod 一直处于 CrashLoopBackOff。按这里说 https://kubernetes.io/docs/setup/independent/troubleshooting-kubeadm/ 如果没有安装 CNI 前,coredns 会一直处于 Pending 状态,这个对的上。一安装 weave 后马上就 CrashLoopBackOff。
Kubectl describe 返回说 0/1 nodes are available: 1 node(s) were not ready. Kubectl log 没有返回。后来在 /var/log/containers/coredns.log 里面发现原来 kubectl logs 返回的是真正的 log:
standard_init_linux.go:178: exec user process caused “operation not permitted”,
原来我装 EFK 的时候修改了 Docker 的配置 /etc/sysconfig/docker:
OPTIONS='--selinux-enabled --log-driver=json-file --signature-verification=false’ 去掉其中的 selinux。
今天发现 k8s-1 master 上面的 weave 反复重启(以前没有过?我没做啥修改啊),日志里面有:
FATA: 2018/10/12 09:52:45.999563 [kube-peers] Could not get peers: Get https://10.96.0.1:443/api/v1/nodes: dial tcp 10.96.0.1:443: i/o timeout Failed to get peers
不能访问 api server?我发现 k8s-1上面居然没有 kube-proxy pod?这是正常的么?为什么kube-proxy没有起来呢?DaemonSet不是每个node都起一个么 ,你看weave就是。不对,rook ceph就没有。原来现在默认DaemonSet是不在Master node上运行的,weave有如下调度策略配置:
"tolerations": [
{
"operator": "Exists",
"effect": "NoSchedule"
}
]
kube-proxy yaml也有类似,但是格式和上面不同,可能是升级导致。修改后现在k8s-1上面也有一个kube-proxy pod 了。详细看 https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/。
题外话:如果 api server 所在的 node 上面没有 weave,api server 如何和其他节点上的 pod 通信知道其状态?pod 之间通信才需要 weave,pod 状态是 kubelet 反馈的。
Dashboard pod 不是大量访问 api server 么?Dashboard 是 in-cluster 方式访问,并没有指定 api server ip,所以,我猜是通过 kubelet 来做的代理,这里 kubelet 和 proxy 功能有重合。没有了kube-proxy,怪不得现在不能通过http://k8s-1:NodePort来访问service了。
为什么 dashboard pod 一直可以访问api server,而 istio injector就必须通过 kube-proxy 访问 webhook 呢?Istio 可以运行在 cluster 外部?
https://kubernetes.io/docs/concepts/architecture/master-node-communication/ 这个似乎也没讲清楚。
今天发现 etcd 没有起来,api server container log: Unable to create storage backend: config. err (dial tcp 127.0.0.1:2379: connect: connection refused) 没有 etcd log,docker ps 没有 etcd,正常情况下是有个的。 journalctl –no-pager -u kubelet -n 4000 似乎是磁盘压力:
eviction_manager.go:156] Failed to admit pod weave-net-gb5l5_kube-system(2bec0ea4-b667-11e8-86d6-aa90b3cbae01) - node has conditions: [DiskPressure]
删除些东西后就正常了,不知道是不是根本原因。或者是 etcd 写入出现问题,前面我有强制删除 pvc。不管怎样,情况有点吓人。
kube-controller-manager 起不来,failed,无日志。
[centos@k8s-1 containers]$ kubectl describe pod kube-controller-manager-k8s-1 -n kube-system
The node was low on resource: ephemeral-storage. Container kube-controller-manager was using 60688Ki, which exceeds its request of 0.
其参数配置在:
/etc/kubernetes/manifests/kube-controller-manager.yaml
添加值 ephemeral-storage: 100Mi。修改后 systemctl restart kubelet 不起作用,reboot node 也没用。kubectl edit pod 里面显示的还是老的值。我等了大概半个小时后 kube-controller-manager-k8s-1 正常启动了,配置也更新了。不知道这个是 kubelet 还是 kubeadm 的机制。现在又从 200M 增加到 300M,这个控制器应该是无状态的啊,为什么占这么多资源。
关于ephemeral-storage,https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/. 这个『短暂』存储保存的是 kubelet’s root directory (/var/lib/kubelet by default) and log directory (/var/log),这个要这么大?
kube-controller-manager 起不来会导致系统中 Statefulset 创建了,但是 pod/pvc 都没有创建,也没有任何错误,但是界面上没有任何有效的警告信息。这个可以做成 HA 么?否则影响太大。或者告警那里能重点监控 kube-system 里面的 pod。
Inside
How kubeadm Initializes Your Kubernetes Master https://www.ianlewis.org/en/how-kubeadm-initializes-your-kubernetes-master
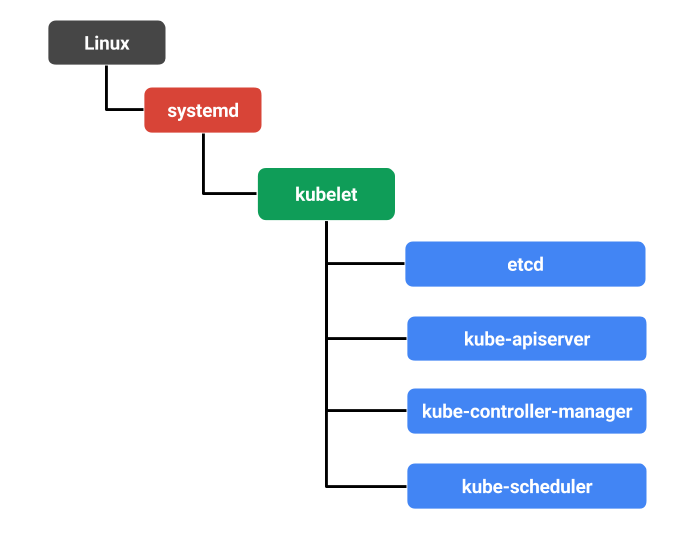
Troubleshooting
Dmesg 反复显示:
[959776.150708] IPVS: Creating netns size=2048 id=77
[959776.353964] weave: port 8(vethweple4c80f4) entered blocking state
[959776.356498] weave: port 8(vethweple4c80f4) entered disabled state
[959776.390464] device vethweple4c80f4 entered promiscuous mode
[959776.456718] IPv6: ADDRCONF(NETDEV_UP): vethweple4c80f4: link is not ready
[959776.504730] IPv6: ADDRCONF(NETDEV_CHANGE): vethweple4c80f4: link becomes ready
[959776.507472] weave: port 8(vethweple4c80f4) entered blocking state
[959776.509741] weave: port 8(vethweple4c80f4) entered forwarding state
[959776.757383] IPv6: eth0: IPv6 duplicate address fe80::3c75:1eff:fea9:3828 detected!
[959777.369007] weave: port 8(vethweple4c80f4) entered disabled state
[959777.405632] device vethweple4c80f4 left promiscuous mode
[959777.407870] weave: port 8(vethweple4c80f4) entered disabled state
这个是因为 IPVS 规则变化的原因? 先禁用 ipv6 on centos:
sysctl -w net.ipv6.conf.all.disable_ipv6=1
sysctl -w net.ipv6.conf.default.disable_ipv6=0
但这个似乎是 openvswitch kernel module 必须的,重启后还是能看到上面日志。其实这个 eth0 是不存在的一个 interface,只在 /etc/sysconfig/network-scripts 里面存在,ip addr 里面没有,不知道为何这里会出现。删除后问题依然,这里说这是 docker 上面一个有名的问题,和 DAD stands for Duplicate Address Detection 有关系。Fedora 28 下面没有这个问题。
kubelet bootstrap 流程,首先会先从 master node 那里拿到 token,然后 work node 会根据 token 拿到证书,尔后访问都会根据证书来访问 API Server。有了 token 后 master node 才会信任 work node 然后颁发证书。
openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet-client-current.pem
Validity
Not Before: Jul 12 04:29:00 2018 GMT
Not After : Jul 12 04:29:00 2019 GMT
Subject: O=system:nodes, CN=system:node:k8s-2-new
这个有效期有一年,这么长!到期会自动 renew 续签,这种有了 token 后都是自动的,安全性比只用 token 要高么?
使用 kubeadm 搭建 multi-master k8s 集群总结, 有提供 Ansible。
证书过期的问题:
2018/12/07 10:57:09 Error while initializing connection to Kubernetes apiserver. This most likely means that the cluster is misconfigured (e.g., it has invalid apiserver certificates or service accounts configuration) or the --apiserver-host param points to a server that does not exist. Reason: Get https://192.168.1.140:6443/version: x509: certificate has expired or is not yet valid
有时候运行基本的命令也不行:
kubectl get nodes
error: You must be logged in to the server (Unauthorized)
api-server log一堆这样的错误: Unable to authenticate the request due to an error: x509: certificate has expired or is not yet valid。
奇怪的是集群内部的 dashboard 正常运行,in-cluster 访问 api server 不校验证书?这个问题有个 kubeadm issue 解决,就是太麻烦了。这个 stackoverflow 的方法不用重启节点。Certificate Management with kubeadm这里显示 kubeadm 1.15 对这个问题做了改进,现在只需要运行 kubeadm alpha certs renew all 就可以了,查看证书是否过期 kubeadm alpha certs check-expiration,单独的查看命令:
openssl x509 -in /etc/kubernetes/pki/apiserver-kubelet-client.crt -noout -text |grep ' Not '
Not Before: Jul 5 06:40:11 2018 GMT
Not After : Jul 5 06:40:12 2019 GMT
可以看出这个文件证书过期了(现在日期2019/7/19)。那么问题怎么发生的呢?从上面文档看,每次运行kubeadm upgrade都会更新证书啊。另外 apiserver 为什么要去主动连接 kubelet?不是 kubelet 到 api server 中注册本身的节点么?双向的?
升级(kubeadm upgrade plan)过程中出现错误:
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
error syncing endpoints with etc: dial tcp 192.168.51.11:2379: connect: connection refused
2379 是 etcd 的端口,为什么不能访问?运行sudo curl https://127.0.0.1:2379/health --key /etc/kubernetes/pki/etcd/healthcheck-client.key --cert /etc/kubernetes/pki/etcd/healthcheck-client.crt -k可以,但是如果把 IP 改成 192.168.51.11 就会出现 connection refused,按道理非 HA 模式下 etcd 只会被 api server 访问,所以 127.0.0.1 应该就够了。我找到的方法是修改 kubeadm-config ConfigMap 里面的 IP 即可以。