CDAP 架构分析
运行架构
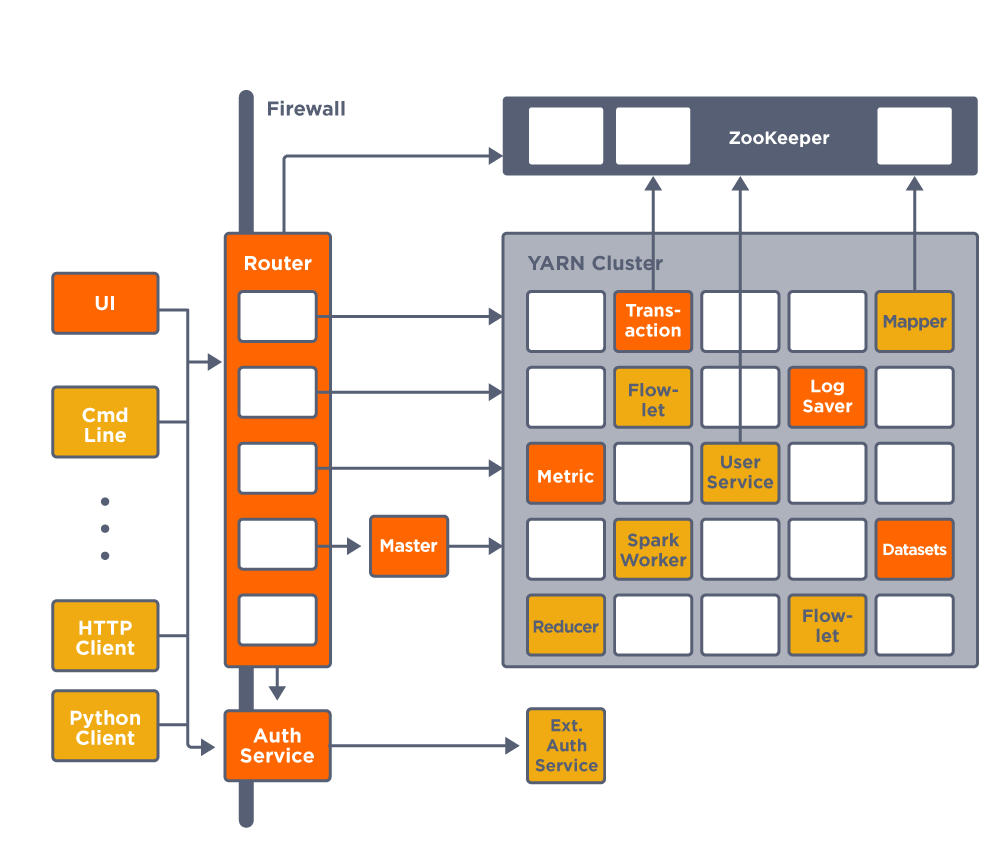
Router 和 Master 是运行在 YARN Cluster 之外的节点,叫 edge node。Master 负责创建其他的 YARN 管理的 service。
部署架构
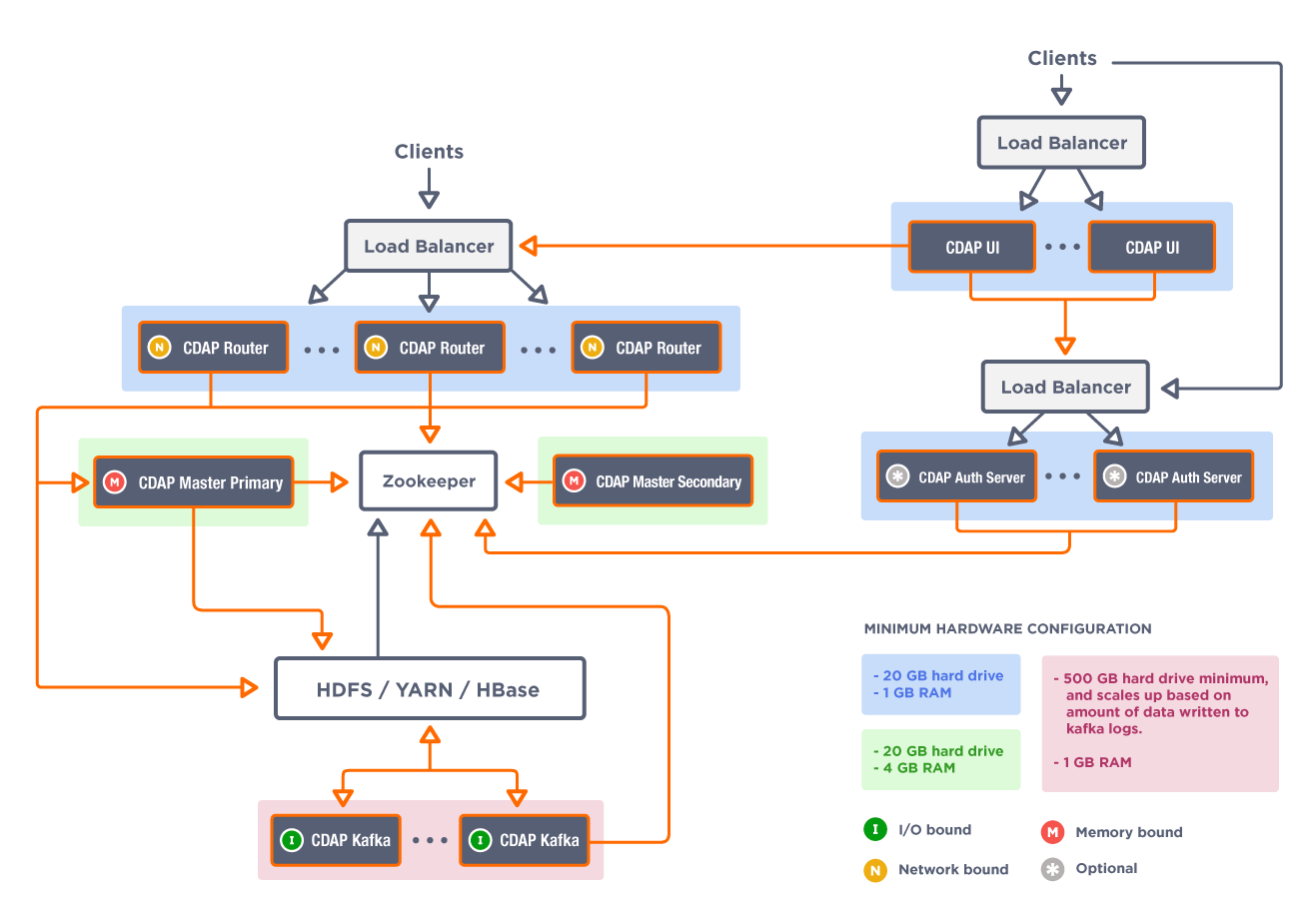
Router 运行在 Netty 上面,其实为微服务的中间层,会连上 ZK 发现后台服务。然后转发 REST API 到 master 相应的服务比如 appfabric,为了提高 IO 吞吐量,这里做了集群。主要是 UI 层会发大量的 REST 请求,集群后,会有多个网卡服务这些请求。转发对 IO 要求比较高,所以这里选择了 Netty。其实后面的自定义的 Application 也用的是 Netty。
但是我看 ZK 里面没有啥注册服务啊?这里的服务其实是 Twill 的服务(一个简化 YARN 开发的库),通过 YARN 运行,和一般的微服务不大相同。运行在 YARN 上面的服务也没办法做集群把。其 log 在 logs/cdap-debug.log.1 里面。其请求处理逻辑在HttpRequestHandler.messageReceived,首先RouterPathLookup会根据 URL 转换(有 hard code 的东西)成对应的 service,
public static final RouteDestination APP_FABRIC_HTTP = new RouteDestination(Constants.Service.APP_FABRIC_HTTP);
public static final RouteDestination METRICS = new RouteDestination(Constants.Service.METRICS);
public static final RouteDestination STREAMS_SERVICE = new RouteDestination(Constants.Service.STREAMS);
然后 RouterServiceLookup 会调用 org.apache.twill.discovery.DiscoveryServiceClient 发现服务。所以 fabic 也是直接注册到 twill 里面?废话。
找到对应服务后,转发请求。这块大量用了 Netty 的代码,并没有使用gRPC之类的东西。比如 fabic 里面的 ProgramLifecycleHttpHandler 就是一个标准的 REST,那为什么cdap-app-fabric/pom.xml没有包含 REST 的依赖呢?
系统有两种不同类型的 service:
[zk: localhost:2181(CONNECTED) 4] ls /cdap/discoverable
[dataset.service, messaging.service, log.framework, streams, metrics.processor, dataset.executor, metrics.processor.messaging.fetcher, log.saver, metrics.processor.kafka.consumer, explore.service, appfabric, metadata.service, metrics, remote.system.operation, transaction]
[zk: localhost:2181(CONNECTED) 5] ls /cdap/twill
[service.default._Tracker.TrackerService, master.services, service.default.ProjectApp.ProjectServiceHandler, service.default.wrangler.service, flow.default._Tracker.AuditLogFlow]
"CDAP Master Services—Transaction, Apache™ Twill®, CDAP programs (flows, MapReduce, services, workers) and CDAP Explore queries—run in YARN on default YARN queues."
app_fabric, metrics 这些 service 只是 master.service 下面暴露出来的 service?service 之间如何调用?
ServiceDiscoverer.getServiceURL 可以根据参数的不同发现本应用内的其他服务或者其他应用的服务。这种应用多半为自定义的注册到/cda/twill 的应用。/cda/discoverable 下面的多半还是得用DiscoveryServiceClient 查找到服务。
其中的ProjectService是我自己创建的 Application,这个不在 discoverable 里面,router 是怎么发现和调用的呢?难道统一转到 appfabric 再转到 projectservice?搜索”/method”,cdap-app-fabric/…/ServiceHttpServer.java里面好像是处理转发的。
其实RouterPathLookup已经处理了:
if ((uriParts.length >= 9) && "services".equals(uriParts[5]) && "methods".equals(uriParts[7])) {
//User defined services handle methods on them:
//Path: "/v3/namespaces/{namespace-id}/apps/{app-id}/services/{service-id}/methods/<user-defined-method-path>"
return new RouteDestination(ServiceDiscoverable.getName(uriParts[2], uriParts[4], uriParts[6]));
打开 router debug log,修改/etc/cdap/conf/logback.xml,重启router服务,当调用我自己的project api时,在/var/log/cdap/router.log里面有:
017-05-06 03:54:15,995 - DEBUG [New I/O worker #18:c.c.c.g.r.RouterServiceLookup@195] - Looking up service name {serviceName=service.default.ProjectApp.ProjectServiceHandler, version=null}
2017-05-06 03:54:15,996 - DEBUG [New I/O worker #18:c.c.c.c.g.ProgramDiscoveryServiceClient$1@96] - Create ZKDiscoveryClient for /twill/service.default.ProjectApp.ProjectServiceHandler
这个是在第一次调用时才会触发,再次调用api没有log,应该是被cache了。其他系统自带的services在router启动时就加载了。log上面看,ProgramDiscoveryServiceClient似乎是直接到/cdap/twill下面拿program类型的service了。AppFabricServerTest 有演示如何和DiscoveryServiceClient交互。感觉它的这个服务的发现做的复杂了。
RouterPathLookup有如下注释:
//Check if the call should go to webapp
//If service contains "$HOST" and if first split element is NOT the gateway version, then send it to WebApp
//WebApp serves only static files (HTML, CSS, JS) and so /<appname> calls should go to WebApp
//But stream calls issued by the UI should be routed to the appropriate CDAP service
可同时参考 RouterPathTest。这就是说可以把 webapp 放到一个 jar 包里面,这样 web app 和 REST 都能支持?
AppFabricServer 这个有注册到 Twill,但是在 AppFabricServiceRuntimeModule 里面看,这个只是在 standalone 中才会用到。分布式用的是 AppFabricServiceManager。为什么有 StandaloneAppFabricServer?
原来是 MasterServiceMain 启动了 AppFabricServer,都是 hardcode 的?
AppFabricServer 构造时要传入 @Named(Constants.Service.MASTER_SERVICES_BIND_ADDRESS) InetAddress hostname,这个对于所有的 service 都是一样的么,那定位啥服务,都是 master 的地址就好了。
这些服务都是在 master.service 下面,所以粒度并不是很小,不过如果 master.service 有多个节点,则上面的服务比如 appfabric 也会有多个。但是即便我加了一个 master server,/cdap/discoverable/appfabric/下面依然只有一个,如果停掉一个,里面的值会变化(记得重新登陆zoomkeeper-client),route 也能很平滑的连接到新的 master。这说两个master确实是为主备关系,并非组成集群。根据其架构图,router有做集群,但是这个有用么?router的负载又不大。但是连接的connect多,所以这个集群只是为了IO性能更好。
上面的 load balance 是如何知道各个 router server 的 IP 地址呢?router server都是在安装时就指定了,但是UI/node.js 是如何知道这些信息的呢?读取配置是 parser.js 干的,它在生产环境下会运行 cdap config-tool 来读取文件,具体代码在bin/functions.sh里面,会读取/conf下面的文件,这不也是死的么。我猜在生产环境下,node server 和 router 之间会有个 nginx 之类的转发服务器,那这个服务器怎么知道那些 server 提供 router 功能呢?可能先配置好,这个转发器只能看看那些服务器是 live 的状态。
HBase、Hive 还有 Spark 都是运行在 CDAP 外部,由 HDP 或者 CDH 管理。CDAP 如何知道这些外部服务的信息呢?这个 Ambari——大数据平台的搭建利器之进阶篇 有谈到 『Ambari 中 Service 之间的依赖关系』。
Application
官方文档 对于发布 jar 的应用,其可能包含 workflow, service, map-reduce 各种应用。对于一个 service,其是根据 namespace 创建多个实例么?wrangler 似乎是这样的。否则在另外一个 namespace 怎么用这个 application 呢?每个 service 是一个 YARN 上面的一个任务么?没错,和 master.service 一样是 RUNNING 也就是保持运行的任务。每个 service REST 地址都是 router 的地址,和系统本身的 REST API 一样。router 然后会定位 service 位置的具体节点信息?我现在在分布式的下调用 rest 时候说找不到这个 endpoint :
http://192.168.51.123:11016/v3/namespaces/default/apps/ProjectApp/services/ProjectServiceHandler/methods/project
文档上面Service Discovery,里面 java 代码可以通过上下文获取地址。但是 node 呢?这个东西要 router 做么?还是我扩展 node server?查看YARN,原来application压根没起来:
[Sat Apr 15 05:32:27 +0000 2017] Application is added to the scheduler and is not yet activated. Queue's AM resource limit exceeded. Details : AM Partition = <DEFAULT_PARTITION>; AM Resource Request = <memory:512, vCores:1>; Queue Resource Limit for AM = <memory:3584, vCores:1>; User AM Resource Limit of the queue = <memory:3584, vCores:1>; Queue AM Resource Usage = <memory:3584, vCores:6>;
不懂,大概是资源不够。停掉其他的几个service就可以起来了,然后上面的也可以访问了。这说明router确实做了service的路由。
server上面应用放在/hadoop/YARN/local/usercache/cdap/appcache/application_xxx/container_e07_xxx目录下。
在 Web UI 上面可以看到这个应用的 log:
2017-04-15 05:41:25,507 - INFO [NettyHttpService STARTING:c.c.h.NettyHttpService@257] - Starting ProjectServiceHandler-http http service on address c6406.ambari.apache.org/192.168.64.106:0...
2017-04-15 05:41:25,822 - INFO [NettyHttpService STARTING:c.c.h.NettyHttpService@262] - Started ProjectServiceHandler-http http service on address /192.168.64.106:60954
2017-04-15 05:41:25,921 - INFO [ServiceHttpServer STARTING:c.c.c.i.a.s.ServiceHttpServer@254] - Announced HTTP Service for Service program:default.ProjectApp.-SNAPSHOT.service.ProjectServiceHandler at /192.168.64.106:60954
2017-04-15 05:57:46,946 - INFO [ProjectServiceHandler-http-executor-2:c.c.c.c.g.LocationRuntimeModule@100] - HDFS namespace is /cdap
2017-04-15 05:57:48,321 - INFO [ProjectServiceHandler-http-executor-2:o.a.t.d.AbstractClientProvider@110] - Service discovered at c6406.ambari.apache.org:45204
2017-04-15 05:57:48,327 - INFO [ProjectServiceHandler-http-executor-2:o.a.t.d.AbstractClientProvider@118] - Attempting to connect to tx service at c6406.ambari.apache.org:45204 with timeout 30000 ms.
2017-04-15 05:57:48,366 - INFO [ProjectServiceHandler-http-executor-2:o.a.t.d.AbstractClientProvider@132] - Connected to tx service at c6406.ambari.apache.org:45204
ZooKeeper里面有记录:
[zk: localhost:2181(CONNECTED) 15] get /cdap/twill/service.default.ProjectApp.ProjectServiceHandler/instances/657aaf98-c5c1-4f03-b492-acab457107bb
{"data":{"appId":14,"appIdClusterTime":1491827645044,"containerId":"container_e07_1491827645044_0014_01_000001","localFiles":[{"name":"twill.jar","uri":"hdfs:// c6404.ambari.apache.org:8020/cdap/twill/.cache/1491827995013/twill.jar","lastModified":1491828018694,"size":24044912,"archive":true,"pattern":null},{"name":"runtime.config.jar","uri":"hdfs://c6404.ambari.apache.org:8020/cdap/twill/service.default.ProjectApp.ProjectServiceHandler/657aaf98-c5c1-4f03-b492-acab457107bb/runtime.config.f8e0ba60-13eb-43ae-ab1b-aff5edc61787.jar","lastModified":1492234857687,"size":3121,"archive":true,"pattern":null},{"name":"launcher.jar","uri":"hdfs://c6404.ambari.apache.org:8020/cdap/twill/.cache/1491827995013/launcher.jar","lastModified":1491828012548,"size":5698,"archive":false,"pattern":null},{"name":"application.jar","uri":"hdfs://c6404.ambari.apache.org:8020/cdap/twill/.cache/1491827995013/5b4fc79b180a2b61896cdd284fc422be-application.jar","lastModified":1491882221008,"size":68268289,"archive":true,"pattern":null}]}}
那说明这个 Application 就是一个基于 Twill 的应用了,就和 master.service 一样。
这里的 application 感觉是任何应用都可以么?感觉像一个容器,天生方便处理数据,service还可以scale:据说是可以动态scale。但是不能包含 web/nginx 前端,可惜。 而且似乎多个 service 实例的调用会做负载均衡,有时候会导向某一个,有时候会导向另外一个。
杂项
-
Route Config,对于 service 的多个版本,这个 API 能在服务器端做多版本间的分流,但是前端似乎没有办法指定调用版本。
-
GET http://10.131.40.13:11015/v3/namespaces/default/apps/DataModelApp/services/DataModelService不含 method,这个会返回这个 app 的定义,包含里面所有的的 service handler。设计的不错。 - YARN 只是一个 Java 容器的管理,不是通用的 Docker,也没有网络抽象,所以无法管理一个 Nginx 的实例。Service 也只能用 Java 编程,这个地方某些情况下用 Node.js 效率会更快。这个是个商品买卖的例子。
Purchase 里面通过 REST 创建用户,但是我在 UI Explorer 里面看到的 K-V 都是数字,使用 bin/cdap cli call service PurchaseHistory.UserProfileService GET user/fan 确实可以返回数据。不知道这个存储是什么格式。但是在分布式环境中则可以清晰的显示:
hbase(main):002:0> scan "cdap.user.userProfiles.kv" ROW COLUMN+CELL fan column=d:c, timestamp=1491897459576000000, value={"id":"fan","firstName":"kun","lastName":"pe ng","categories":["fruits"]} -
上传新项目时候,老的 dataset 里面的数据并没有被清空,这点在迁移/滚动升级的时候很有用。
-
项目如果有 REST 服务,jar 包里面会包含 Netty,但是不会包含 Hadoop 的依赖 jar。大小在4MB,还可以接受。我后来使用了 StringUtils,结果发布后保存找不这个类,jar 我解压开已经包含了 common-lang。奇怪。原来那个 lang 是 cdap 自己的,日。自己在 pom.xml 里面加个了,默认设置。OK。我看这里说如果要把依赖的 jar 加到最终的 jar,需要用 maven-dependency-plugin,这个定义在 cdap-4.1.0.pom 里面。
-
对于一个 application 能否访问,web 端做了检测。但是这个只是简单的访问某个API,如果返回 503则显示这个错误,并不是查看服务状态。详见 cdap-ui\app\cdap\components\DataPrep\index.js。
- 有时候前端修改数据的时候会报错:
Object {statusCode: 500, response: "Exception occurred while handling request: Conflict detected for transaction 1493971971778000001.”}原来一个 service 的方法默认都在事务中,如果同时修改,则会出现事务问题。我是以很快的速度两次修改 k-v 里面的同一 key,这样就出现错误了:第一个会被正确提交,第二个会被回滚。造成这个原因在于 value 我用的是 JSON,比如{key-> {a:1, b;2}}。如果 a,b 分开存在不同的 HBase 列簇上面,就不会出现上面问题了?如此看来,这是 k-v 表的优势了?这种一对多的关系在关系数据库里面是保存在不同表上面,a 和 b 也是不同的行。这个实现方式是乐观锁还是悲观锁?这里有描述和例子。其默认是行加锁,粒度更细的是列加锁:同时修改同样行的同样列,则会报错。这样看来有点像数据库的锁,也就是悲观锁。具体由 tephra 实现,其主页有:How It Works:Tephra leverages HBase’s native data versioning to provide multi-versioned concurrency control (MVCC) for transactional reads and writes. With MVCC capability, each transaction sees its own consistent “snapshot” of data, providing snapshot isolation of concurrent transactions。 多版本并发控制,有点类似乐观锁,Oracle、MySQL innodb 都有用这个,也可以看看PostgreSQL的MVCC并发处理。