Helm / Monocular
安装
- https://github.com/kubernetes-helm/monocular
- Kubernetes包管理器Helm现在由CNCF托管 http://www.infoq.com/cn/news/2018/06/helm-hosted-cncf
- Google Charts https://github.com/helm/charts
- helm upgrade jxing stable/nginx-ingress 升级已有 chart 0/4 nodes are available: 1 node(s) had taints that the pod didn’t tolerate, 3 node(s) didn’t have free ports for the requested pod ports. 端口没有释放,升级策略导致?
[fedora@kong-ct5vbhkzjgv2-master-0 ~]$ helm ls
Error: configmaps is forbidden: User "system:serviceaccount:kube-system:default" cannot list configmaps in the namespace "kube-system"
[fedora@kong-ct5vbhkzjgv2-master-0 ~]$ kubectl create clusterrolebinding add-on-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
clusterrolebinding "add-on-cluster-admin” created
https://github.com/helm/helm/issues/2687
nginx-ingress 是做何而用?似乎是作为前端代理。
if “helm install stable/nginx-ingress”, then I can get Ingress Ip in “kubectl get ingress” soon. But can’t access it. If “helm install stable/nginx-ingress –set controller.hostNetwork=true” which is for Kubeadm, no IP and I get IP directly from Dashboard and can access it. After long time, this way can get IP also.
nginx-ingress is an Ingress controller that uses ConfigMap to store the nginx configuration. nginx 配置在 ui-vhost 这个 configmap 里面,然后被monocular/deployment/monocular/templates/ui-deployment.yaml 使用和 mount,但是 ui server 要 nginx 配置有何用呢?这个配置需要告诉 nginx啊。nginx是如何动态获取这个配置的?
monocular/deployment/monocular/templates/ingress.yaml 定义了 Ingress meta 信息,然后 nginx-ingress controller会获取这个公共的信息。ingress controller 会消化这个 rules 信息并将其转换为自己实现所需的配置。
After deploy, error. mongodb pod say “Unable to mount volumes for pod “anxious-hog-mongodb-mvx69_default(e9e)”: timeout expired waiting for volumes to attach/mount for pod “default”/”anxious-hog-mongodb-mvx69”. list of unattached/unmounted volumes=[data]”
And There is a pending PV claim request. It need 8Gi storage. So just enlarge my PV? Yes. After enlarge. The pending claim turn to Green. I search monocular code and didn’t find PV claim description. But the error pods didn’t refresh/re-create automatically. helm delete/install.
Re-create ceph pool: sudo rbd create real-pool/doo –size 10096, map, format, mount, umount.
mongodb installed on vm3. On vm3, run journalctl --no-pager -u kubelet -n 100 to check recent 100 log. And looks vm3 didn’t configure ceph. Add it to make sure sudo rbd list running successfully. No. I have defined secretRef.
Ceph 太麻烦,改成 NFS 的 PV,这里 helm 还要ReadWriteOnce模式,独占式的?然后 claim 就成绿色的了。然后不用重新发布 monocular,它会自己反复尝试,然后我在 Nfs目录下就可以看到 conf/mongodb.conf 文件。这个 PV 似乎每次 monocular install 后就不能用了,只能删除后重建。后来在反复 monocular install 过程中,我删除了 nfs 下面的文件,然后 mongo pod 就报错说 conf 找不到。难道这个 pod 不知道我已经删除了么?
Error executing ‘postInstallation’: Path ‘/bitnami/mongodb/conf’ does not exists. 换一个 nfs 名字还是不行,后来发现 nfs 根目录下面有个 .initialized 文件,我日,这样来初始化有点low啊。删除 monogo pod,conf data 文件就自动产生了。
总的来说,api server 下载 charts 有点漫长,整个过程也有点漫长。
api pods 在连上 mongo db 后,会从https://kubernetes-charts.storage.googleapis.com下载大量东西,然后存到 mongo 中去。这个过程有点漫长,过程中 pod 显示会有错误,这个不大好。然后访问 UI 时,kubectl get ingress 没有显示 IP,随便找了个界面可以访问,但是所有/api/开头的都返回404,似乎这个 Proxy 没有转发。”helm install stable/nginx-ingress –set controller.hostNetwork=true” 这种方法刚开始也是404错误,过一段时间后ok了,kubectl get ingress 也会返回IP。另外一种安装 nginx-ingress的方法一直404。 Runwget localhost:8081/v1/charts in API Pod terminal can return json. On 404 cluster, this API works too. So something was wrong in Ingress.
DEBUG. Nginx-ingress-controller 有如下 log:
192.168.18.2 - [192.168.18.2] - - [20/Apr/2018:07:55:25 +0000] "GET /assets/icons/menu.svg HTTP/2.0" 200 215 "https://192.168.51.13/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36" 33 0.001 [default-affable-worm-monocular-ui-80] 10.40.0.2:8080 215 0.001 200
192.168.18.2 - [192.168.18.2] - - [20/Apr/2018:07:55:26 +0000] "GET /api/v1/charts HTTP/2.0" 404 19 "https://192.168.51.13/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36" 27 0.376 [default-affable-worm-monocular-api-80] 10.40.0.4:8081 19 0.376 404
10.40.0.4:8081 这个IP 所在 API POD 我进入命令行,wget localhost:8081/v1/charts可以获取。在nginx-ingress controller 命令行下,直连api pod 可以,但是 curl -k https://localhost:/api/v1/charts 不成功。直接查看 /etc/nginx/nginx.conf 发现里面的内容好的坏的相差很大:
upstream default-exacerbated-parrot-monocular-api-80 {
# Load balance algorithm; empty for round robin, which is the default
least_conn;
keepalive 32;
server 10.40.0.11:8081 max_fails=0 fail_timeout=0;
server 10.32.0.13:8081 max_fails=0 fail_timeout=0;
}
server {
location ~* ^/api/(?<baseuri>.*) {
set $proxy_upstream_name "default-exacerbated-parrot-monocular-api-80";
# In case of errors try the next upstream server before returning an error
proxy_next_upstream error timeout invalid_header http_502 http_503 http_504;
rewrite /api/(.*) /$1 break;
rewrite /api/ / break;
proxy_pass http://default-exacerbated-parrot-monocular-api-80;
}
错误的里面没有上面的 rewrite,表现和这个一模一样:https://github.com/kubernetes-helm/monocular/issues/422 。但是我好的是第二天部署的,第二天的 Docker image 就修复了这个问题?尝试按照上面加上rewrite的定制,然后就OK了。可能坏的集群上面删除 image cache 可能会好吧。
删除已安装的 helms,其删除后返回charts列表,这个有细粒度的控制。
[root@k8s-1 centos]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
coiled-fox-nginx-ingress-controller LoadBalancer 10.109.246.144 <pending> 80:30827/TCP,443:30194/TCP 22d
coiled-fox-nginx-ingress-default-backend ClusterIP 10.103.27.158 <none> 80/TCP 22d
[root@k8s-1 centos]# curl 10.103.27.158
default backend - 404
default-backend 是一个fallback的server。那系统中只能由一个ingress-controller么?既然monocular定义的ingress并没有制定由那个controller来转发,这个是任意指派的?我自己又部署了一个,helm install stable/nginx-ingress –set controller.hostNetwork=true。这次分配到另外一个ip(可能这个是controller.hostNetwork=true的效果)。尝试发布应用,感觉这两个LB其实是一个啊。
多次重启的问题
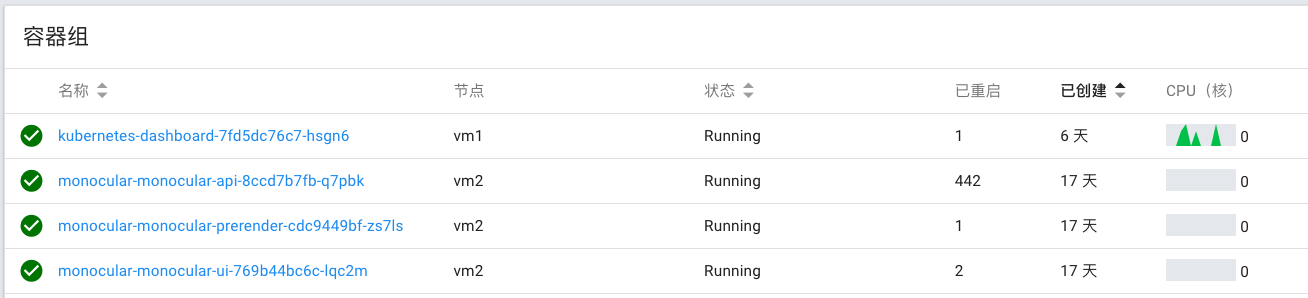 和ingress有关 https://github.com/kubernetes-helm/monocular/issues/444 Helm 安装会挂起的问题 https://github.com/kubernetes/helm/issues/2224#issuecomment-356344286
和ingress有关 https://github.com/kubernetes-helm/monocular/issues/444 Helm 安装会挂起的问题 https://github.com/kubernetes/helm/issues/2224#issuecomment-356344286
初始化的时候多次重启的问题 https://github.com/kubernetes-helm/monocular/issues/450,因为在下载大量 charts。而且有两个 api server,说明有 HA 了,但为什么好的那个不服务呢?
Readiness probe failed: Get http://10.32.0.32:8081/healthz: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
我试了下,curl http://10.32.0.32:8081/healthz -v 返回 200,log 里面也可以看到。
看代码已经做了 go channel,相应不及时而已?monocular/src/api/data/cache/cache.go Refresh() 方法刷新数据,这个问题不好重新啊。
有时候错误又为 Liveness probe failed: Get http://10.40.0.50:8081/healthz: read tcp 10.40.0.0:50584->10.40.0.50:8081: read: connection reset by peer
time="2018-06-26T05:56:59Z" level=info msg="Configuration bootstrap init" configFile="/monocular/config/monocular.yaml"
time="2018-06-26T05:56:59Z" level=info msg="Configuration file found!"
time="2018-06-26T05:56:59Z" level=info msg="Loading CORS from config file"
time="2018-06-26T05:56:59Z" level=info msg="Loading repositories from config file"
time="2018-06-26T05:56:59Z" level=info msg="Configuration bootstrap finished"
time="2018-06-26T05:56:59Z" level=info msg="Using cache directory" path="/monocular/repo-data” ——>这里等了半天
time="2018-06-26T05:57:22Z" level=info msg="Deprecated chart skipped" name=telegraf...
time="2018-06-26T05:57:22Z" level=info msg="Deprecated chart skipped" name=kubed
time="2018-06-26T05:57:23Z" level=info msg="Local cache missing" name=dex version=0.1.0
time="2018-06-26T05:57:23Z" level=info msg="Downloading metadata" dest="/monocular/repo-data/stable/dex/0.1.0/chart.tgz" source="https://kubernetes-charts.storage.googleapis.com/dex-0.1.0.tgz"
time="2018-06-26T05:57:23Z" level=info msg="Storing in cache" path="/monocular/repo-data/stable/dex/0.1.0/README.md"
time="2018-06-26T05:57:23Z" level=error msg="Error on DownloadAndExtractChartTarball" error="open /tmp/chart653157453/dex/README.md: no such file or directory"
time="2018-06-26T05:57:27Z" level=info msg="Deprecated chart skipped" name=burrow...
time="2018-06-26T05:57:27Z" level=info msg="Deprecated chart skipped" name=kubewatch
time="2018-06-26T05:57:28Z" level=info msg="Storing in cache" path="/monocular/repo-data/incubator/fluentd/0.1.4/README.md"
time="2018-06-26T05:57:28Z" level=error msg="Error on DownloadAndExtractChartTarball" error="open /tmp/chart801321288/fluentd/README.md: no such file or directory"
time="2018-06-26T05:57:28Z" level=warning msg="authentication is disabled" error="no signing key, ensure MONOCULAR_AUTH_SIGNING_KEY is set"
time="2018-06-26T05:57:28Z" level=info msg="Started Monocular API server" addr=":8081"
[negroni] 2018-06-26T05:57:33Z | 200 | 130.925µs | 10.40.0.44:8081 | GET /healthz —>开始响应probeness
这个是 container 启动的日志,耗时较长,这个时候重启还情有可原,但是起来后应该就一直能响应 /healthz 了啊?/healthz 和 update log 有时候是穿插进行的,似乎update 并没有block /healthz。
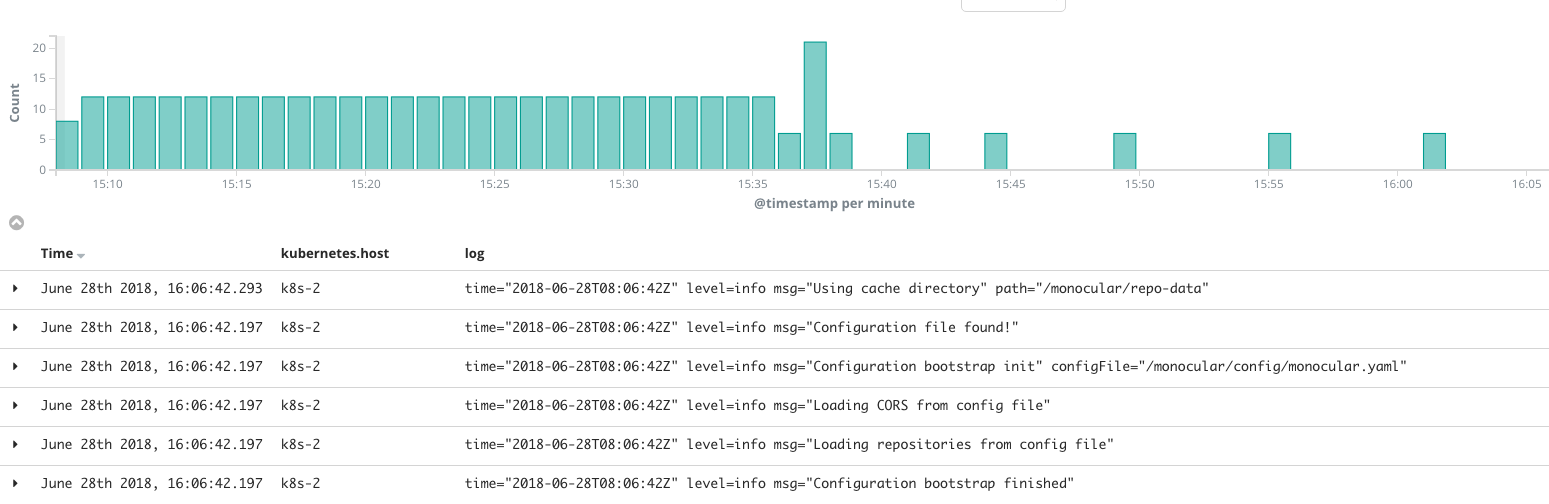
从上面看,17 * 24 = 408,那每个一小时重启一次了?这个和 main.go 里面设置的 cacheRefreshInterval 是一致的。
cache.go.Refresh 里面已经做了 go channel,说明是异步的,为什么不响应 /healthz 呢?
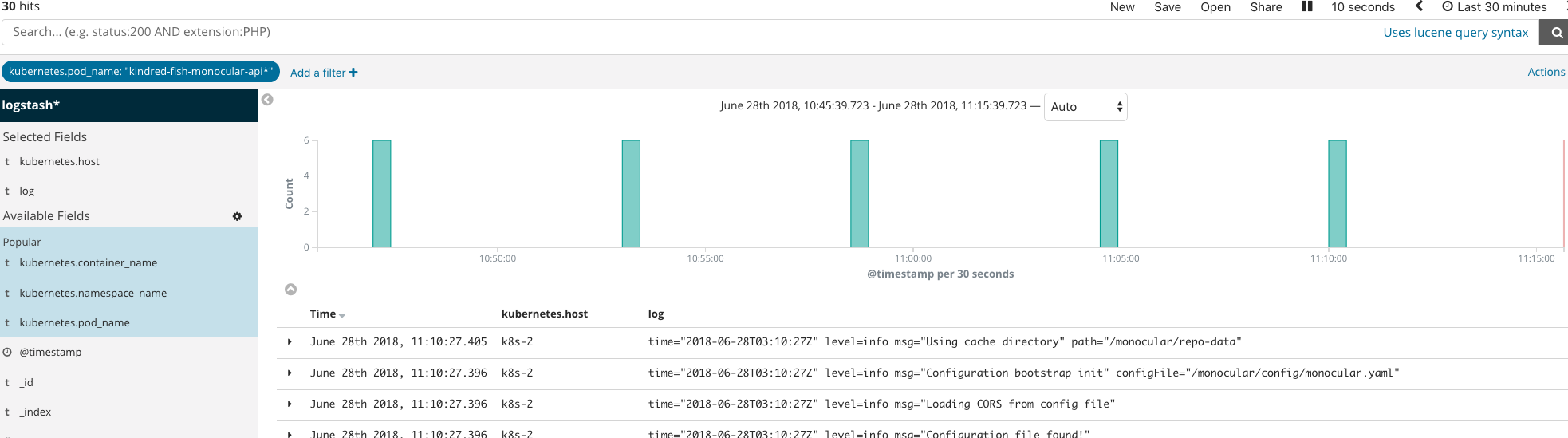
上图是 chart 初次安装时的 EFK,可以看到准确的每隔 5 分钟后重启一次。
"livenessProbe": {
"httpGet": {
"path": "/healthz",
"port": 8081,
"scheme": "HTTP"
},
"initialDelaySeconds": 180,
"timeoutSeconds": 10,
"periodSeconds": 10,
"successThreshold": 1,
"failureThreshold": 3
}
这个合起来是 180 + (10 + 10) *3,没有 300 秒啊?差不多吧。
前面间隔短是/healthz,后面的每次都是上面的几个 log,间隔 5 分钟。这时候是 Readiness probe failed 的。每次都在重启?在成功相应 /healthz 前有次确实在拉取 chart 的日志,然后就马上恢复 /healthz 了。
在 master node 上面运行 journalctl –no-pager -u kubelet 显示了一堆 monocular 的日志,其中:
Container {Name:monocular Image:bitnami/monocular-api… is dead, but RestartPolicy says that we should restart it.
这个出现间隔为 16 秒,probe 的间隔?
按照 Started Monocular API server 过滤,确实是每隔一小时成功重启一次。
尝试修改其源代码:monocular/src/api, make bootstrap,需要先运行这个,否则 go 会报找不到依赖的错误。然后运行 src/api 下面运行 make docker-build,编译成功的是 linux 格式。这个是运行在Docker 里面,他应该会把依赖保存在 Docker Volume 里面。
默认的 push URL 地址是 bitnami/monocular-api:latest,现在改为 fkpwolf/monocular-api:x.x on docker hub.
这个monocular分为ui, api, prerender,初始化chart cache是prerender做的?但是我看到很多chart的下载是在api里面做的,但是api又两个啊,这个不引发竞争?cache.go 里面有个锁 sync.RWMutex,但并没有解决问题。而且这锁不是多个 api 容器间的分布式锁吧?
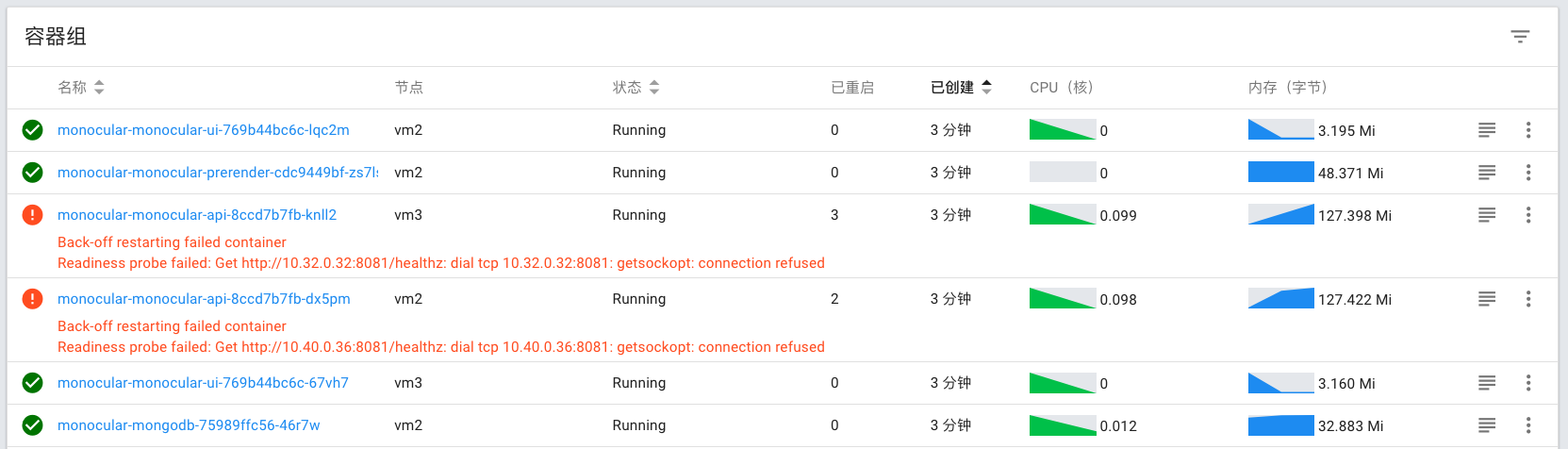
上面两个API server 显示 probe 失败,因为它在拉数据。那 k8s 为什么不把它给 kill 了呢?好像虽然会 probe failed,但是 container 还是一直运行。还是虽然 kill 但是索引已经建好就不用重新创建?果然,一会就 CrashLoopBackOff 了。
为什么没有响应/healthz 呢?难道 goroutine 没有切换?One goroutine trap:when would Goroutine context switch? Go 里面的并行并非多线程,而是一个线程里面的轮换运行,只有当 IO 操作的时候才会切换,比如 http, print 等等。
手工写了个 /refresh rest api,disable foreground repository refresh so I can invoke my REST in clear env. Soon I found when I invoke /refresh, pod just restart!!! So kubelet didn’t know reason and just know it was dead. In dmesg:
[147701.430156] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
[147913.262269] monocular invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=-998
[147913.264347] monocular cpuset=docker-5d3a4c6e75105b3ef0bdfd215ebec12e9a2d32341f369e75125954cb3eeed903.scope mems_allowed=0
[147913.266552] CPU: 0 PID: 26049 Comm: monocular Tainted: G ------------ T 3.10.0-693.11.6.el7.x86_64 #1
[147913.268829] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Ubuntu-1.8.2-1ubuntu1 04/01/2014
[147913.270941] Call Trace:
[147913.271944] [<ffffffff816a5ea1>] dump_stack+0x19/0x1b
[147913.273406] [<ffffffff816a1296>] dump_header+0x90/0x229
[147913.274871] [<ffffffff816b9bff>] ? apic_timer_interrupt+0xff/0x240
[147913.276481] [<ffffffff81187be6>] ? find_lock_task_mm+0x56/0xc0
[147913.278070] [<ffffffff811f34c8>] ? try_get_mem_cgroup_from_mm+0x28/0x60
[147913.279611] [<ffffffff81188094>] oom_kill_process+0x254/0x3d0
[147913.281107] [<ffffffff811f71e6>] mem_cgroup_oom_synchronize+0x546/0x570
[147913.282787] [<ffffffff811f6660>] ? mem_cgroup_charge_common+0xc0/0xc0
[147913.284431] [<ffffffff81188924>] pagefault_out_of_memory+0x14/0x90
[147913.286000] [<ffffffff8169f65e>] mm_fault_error+0x68/0x12b
[147913.287382] [<ffffffff816b3a21>] __do_page_fault+0x391/0x450
[147913.288920] [<ffffffff816b3bc6>] trace_do_page_fault+0x56/0x150
[147913.290461] [<ffffffff816b325a>] do_async_page_fault+0x1a/0xd0
[147913.291854] [<ffffffff816af928>] async_page_fault+0x28/0x30
[147913.293325] Task in /kubepods.slice/kubepods-podbee65b57_7e71_11e8_9ced_d24398b14524.slice/docker-5d3a4c6e75105b3ef0bdfd215ebec12e9a2d32341f369e75125954cb3eeed903.scope killed as a result of limit of /kubepods.slice/kubepods-podbee65b57_7e71_11e8_9ced_d24398b14524.slice
[147913.298709] memory: usage 233472kB, limit 233472kB, failcnt 3028
[147913.300052] memory+swap: usage 233472kB, limit 9007199254740988kB, failcnt 0
[147913.301744] kmem: usage 0kB, limit 9007199254740988kB, failcnt 0
[147913.303218] Memory cgroup stats for /kubepods.slice/kubepods-podbee65b57_7e71_11e8_9ced_d24398b14524.slice: cache:0KB rss:0KB rss_huge:0KB mapped_file:0KB swap:0KB inactive_anon:0KB active_anon:0KB inactive_file:0KB active_file:0KB unevictable:0KB
[147913.447142] Memory cgroup stats for /kubepods.slice/kubepods-podbee65b57_7e71_11e8_9ced_d24398b14524.slice/docker-bf8a40c68a97ea71175febbf2551262a881b3dd519b37a31e8e2837c2f743531.scope: cache:0KB rss:44KB rss_huge:0KB mapped_file:0KB swap:0KB inactive_anon:0KB active_anon:44KB inactive_file:0KB active_file:0KB unevictable:0KB
[147913.492743] Memory cgroup stats for /kubepods.slice/kubepods-podbee65b57_7e71_11e8_9ced_d24398b14524.slice/docker-5d3a4c6e75105b3ef0bdfd215ebec12e9a2d32341f369e75125954cb3eeed903.scope: cache:0KB rss:233428KB rss_huge:2048KB mapped_file:0KB swap:0KB inactive_anon:0KB active_anon:233428KB inactive_file:0KB active_file:0KB unevictable:0KB
[147913.544835] [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
[147913.546739] [24389] 0 24389 253 1 4 0 -998 pause
[147913.548605] [24518] 0 24518 66805 60921 134 0 -998 monocular
[147913.550548] Memory cgroup out of memory: Kill process 26074 (monocular) score 54 or sacrifice child
[147913.552593] Killed process 24518 (monocular) total-vm:267220kB, anon-rss:232620kB, file-rss:11064kB, shmem-rss:0kB
[147919.170462] SELinux: mount invalid. Same superblock, different security settings for (dev mqueue, type mqueue)
But I found log in EFK:
kube-state-metrics The expected resources are &{map[cpu:{0.106000000 DecimalSI} memory:{251658240.000000000 BinarySI}] map[cpu:{0.106000000 DecimalSI} memory:{251658240.000000000 BinarySI}]}
kube-state-metrics Resources are within the expected limits.
Then Edit the monocular Deployment. Default is :
"resources": {
"limits": {
"cpu": "100m",
"memory": "128Mi"
},
"requests": {
"cpu": "100m",
"memory": "128Mi"
}
}
YAML define it? Or k8s default? I change to 228M. Still OOM. Change all(request & limit since I didn’t know difference) to 428M, same Issue. Keep request to 428. Change limit to 928. OK.
I change chart’s buffered channel to 4. Original is len(charts). Set memory to 228. No OOM. But get error:
Readiness probe failed: Get http://10.40.0.44:8081/healthz: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
The node was low on resource: imagefs.
Container runtime did not kill the pod within specified grace period.
And k8s create the third pod at this time! So the cluster think this time need to create new pods. RS setting is 2.
/dev/vda1 8.0G 4.9G 3.1G 62% /monocular
/dev/vda1 8.0G 4.9G 3.1G 62% /dev/termination-log
/dev/vda1 8.0G 4.9G 3.1G 62% /monocular/config
Oh, 8G is just my KVM virtual disk size. Try to set “sizeLimit”: “1Gi” of emptyDir. The download size > 1GB? Should not possible. Same issue. Later after downloaded all, I checked and found the whole size is just 240MB.
Add a 20G vm k8s-4. How to make the monocular-api run the k8s-4? Assigning Pods to Nodes:
"nodeSelector": {
"kubernetes.io/hostname": "k8s-4"
}
Test again. After reboot 2 times, service OK. dmesg didn’t show oom. Didn’t know why reboot. Now send /refresh REST call again, to see how it update when all charts has been cached. Very fast. No error. Why it happened so frequently in past? Need restore(image & config) and verify again.
ch := make(chan chanItem, 4 /len(charts)/). Charts are 2000+. I change to 4. Later I found that “Counting semaphore, 25 downloads max in parallel”. So my changes is useless?
For frontend refresh, need as a Go routine. After do this, now a new pod just 2 restart to download all charts.
Q: When do Refresh(), didn’t inset new data to DB?
在prerender里面进入命令行:
root@erstwhile-deer-monocular-prerender-d556b95c9-k8n6x:/app# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4212 340 ? Ss May31 0:06 tini -- node server.js
root 12 0.0 0.6 886444 26076 ? Sl May31 0:00 node server.js
root 18 0.0 0.6 919228 26444 ? Sl May31 0:00 /opt/bitnami/node/bin/node /app/server.js
root 28 0.0 0.8 1321720 33960 ? Sl May31 0:09 /app/node_modules/phantomjs-prebuilt/lib/phantom/bin/phantomjs --load-im
root 42 0.0 0.0 20260 1960 ? Ss+ 15:46 0:00 bash
root 46 0.0 0.0 20260 1952 ? Ss 15:46 0:00 bash
root 49 0.0 0.0 17492 1144 ? R+ 15:46 0:00 ps aux
All Tini does is spawn a single child (Tini is meant to be run in a container), and wait for it to exit all the while reaping zombies and performing signal forwarding. If you are using Docker 1.13 or greater, Tini is included in Docker itself. 依赖关系为:
bitnami/node -> bitnami/minideb -> [tiny](https://github.com/bitnami/minideb-extras)
这样追踪一个容器有点繁琐,不知道有没有更好的办法。
“PhantomJS的功能,就是提供一个浏览器环境的命令行接口,你可以把它看作一个“虚拟浏览器”,除了不能浏览,其他与正常浏览器一样。”他用这个做啥?
root@erstwhile-deer-monocular-prerender-d556b95c9-k8n6x:/app# cat README.md
Prerender Service ![]()
Google, Facebook, Twitter, Yahoo, and Bing are constantly trying to view your website… but they don’t execute javascript. That’s why we built Prerender. Prerender is perfect for AngularJS SEO, BackboneJS SEO, EmberJS SEO, and any other javascript framework.
Behind the scenes, Prerender is a node server from prerender.io that uses phantomjs to create static HTML out of a javascript page. We host this as a service at prerender.io but we also open sourced it because we believe basic SEO is a right, not a privilege!
It should be used in conjunction with these middleware libraries to serve the prerendered HTML to crawlers for SEO. Get started in two lines of code using Rails or Node.
https://prerender.io/ 有谁会爬这个monocular的站点呢?
有时候不能安装,说是这个已经有了:
helm ls --all // 列出全部
helm del --purge monocular
为什么留下 cache?这个有什么用呢?cache = chart + value,保存了 value。
helm del $(helm ls --short --deleted) --purge // purge 清空已经删除的
inside
How Helm Uses ConfigMaps to Store Data,原来这么土?为什么不用专门存储?因为作为一个包管理器,如果依赖太多就是先有鸡还是先有蛋的问题了。因为 etcd 大小限制,每个 ConfigMap 被限制在1M 以下,所以里面数据做成了 base64的。如此一来 etcd 有被搞坏趋势啊。kubectl get configmap -n kube-system -l “OWNER=TILLER” 这样显示所有的 release,这是用 label 来组建关系啊。每个 release = Chart + Values,这样比如根据 release name 就能计算出 release 所有的创建出来的资源?这个算法有点小复杂吧。
https://blog.openshift.com/wp-content/uploads/Monocular-on-OpenShift.pdf
Helm 只是一个命令行工具,Tiller 是一个服务,但是一般有没有办法通过 REST 来访问之,只能通过 Helm Client。https://banzaicloud.com/blog/helm-rest-api/ 3rd 实现。
https://github.com/helm/community/blob/master/helm-v3/000-helm-v3.md 不分客户端 / 服务器端的单服务架构——无需 Tiller,数据存在 CRD 里面。只要保持简单,其还是能和 operator 竞争的。恕我直言,对Helm大家还是要三思而后用。
初探云原生应用管理(二): 为什么你必须尽快转向 Helm v3
添加参数配置功能
Roadmap 里面说要到 1.0 才会有这个功能 Configure values on install
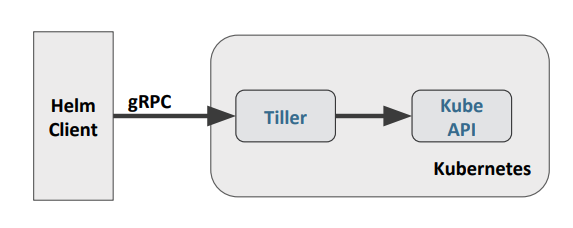
首先要获得 values.yaml 内容。Release 比如安装应用,是在 api/handlers/releases/releases.go 里面做的,其调用 api/data/helm/client/client.go,后者就是上面图中的 Helm Client,通过 gRPC 可以直接安装一个本地的 Chart tar 安装包。最终通过 helm go client 来 gRPC 调用(api/data/helm/releases/releases.go),其他语言就没法了。
对于 Chart,则是直接访问(api/handlers/charts/charts.go)本地的 Chart tar 内容,其调用 chartsImplementation 也就是 api/data/cache/cache.go,后者从 MongoDB 获取数据。代码写的看不懂,有这么复杂么?直接访问 https://vm1/api/helm/api/assets/stable/anchore-engine/0.2.0/README.md 这个可以有值,但是改为 values.yaml 没有,进入 pod cmd,相应目录下确实没有,README.md 有,原来这个是其特意从 tar 里面解压出来的。chart meta 似乎不是从 tar 里面解压获取而是从 chart repository index 直接获取?chart_package_helper.go 里面有 var filesToKeep = []string{“README.md”},这表面只解压这个文件。然后 README.md 还有图标文件会作为 negroni 的静态服务器的资源,还单独用一个第三方库?懒惰。
src/api/vendor/k8s.io/helm/pkg/helm/client.go 这个会最终调用 tiller service,service 定义 https://github.com/helm/helm/blob/master/_proto/hapi/services/tiller.proto
gGPC hello world https://grpc.io/docs/quickstart/go.html
先定义 proto 接口定义文件,包含接口方法名、输入格式和输出格式。然后根据其生成一个 .pb.go 文件,类似 Java RMI stub。然后依赖这个文件,server 实现接口,client 调用接口。
差不多了,开始写代码。先确定如何测试。如果每次修改都搞一个 Docker Image,这个倒还好,主要是 monocular-api 初始化会拉很多镜像,这个有点麻烦,精简其 repo?另外一种办法是 gRPC 直连 Tiller,Tiller 是 ClusterIP,改 NodePort 不好,后来找到一种办法:
kubectl port-forward pod-46r7w 27017:27017 -n kube-system
kubectl port-forward service/monocular-api 27017:27017 -n kube-system 这种更好
Kubectl proxy 只能 HTTP 吧,这种可以是 TCP,范围更广。
但是这种方法因为开发环境没有设置DNS 为 k8s DNS,代码里面必须手工切换 localhost 和 service hostname,所以暂时只能修改 /etc/hosts 这种笨方法,或者通过参数传递:默认是service name,可以接受参数为 localhost。
https://github.com/helm/helm/blob/master/pkg/helm/helm_test.go 这个有展示如何操作 helm api,我试过发现其接受的字符串其实为 json 格式,不是 “a”=“a”, “b”=“b” 这种。
添加参数要修改接口定义 CreateReleaseBody,这个是 swagger 产生出来的,修改 swagger.xml 然后运行 make swagger-serverstub,这个也是个 docker 运行,强啊,会生成一堆文件。
Hashmap swagger 定义 https://swagger.io/docs/specification/data-models/dictionaries/
https://kubernetes-charts.storage.googleapis.com/ 这里下载一个 stable chart tgz 文件作为测试例子
有个问题:似乎带 values 时每次创建的都是同样的 release name(UUID 使用完了?),结果导致返回成功,但是 helm ls 看不到。
Proposal: Monocular 1.0 - improvements and redefining project focus 这个版本会解决大多数的问题,使用 Jobs 来同步,切分模块,去掉安装应用这种 in-cluster 的功能,推荐用 kubeapp 代替,chart 仓库用 CRD 管理(这种需要修改后动态加载的都适合 CRD)。
写 Helm 时候如果要添加一个已有的 Chart,比如 MySql,如何直接调用或者添加呢?如果能用 Juju 展示出来更佳。
monocular/deployment/monocular/requirements.yaml 里面包含:
dependencies:
- name: mongodb
version: 0.4.17
repository: https://kubernetes-charts.storage.googleapis.com
这个设计可以。https://github.com/kubernetes/helm/blob/master/docs/helm/helm_dependency.md 依赖也可以为本地的目录。https://github.com/kubernetes/helm/blob/master/docs/charts.md 讲了不少 dependency。
https://docs.bitnami.com/kubernetes/how-to/create-your-first-helm-chart/
Chartmuseum
https://github.com/helm/chartmuseum/pull/53 Multi-Tenancy POC
Chart 安装的时候默认是 DISABLE_API=true,这导致 api 无法访问,可能安全的考虑。
https://github.com/caicloud/helm-registry 才云的
上传的 tgz 的目录名必须和 name 保持一致,否则 monocular 直接到 /tmp/chart187671202/aerospike-fan-zmy/README.md 这种目录下面找,会找不到。
tar -cvzf <name of tarball>.tgz /path/to/source/folder
如何判定这种上传的是可以删除的 chart 呢?chartmuseum 无法更改 chart keyword,要求用户的 tgz/Chart.yaml 包含某些 keyword 肯定不现实。暂时使用 repo.name。
上传和删除数据后如何同步 monocular 呢?其本来有个 /charts/{repo}/{chartName}/refresh REST API,需要改造成当不在是删除已有的。但是 chartmuseum 上传接口并不返回 chart 信息,所以没有办法指定刷新。
即便这种 REST 刷新可以用,也不是好的办法:先发送创建 API,然后发送刷新 API,而这个由前端保证事务完整性和可靠性,如果后端则小题大做了。监控的地方也是:更新 configmap,然后 reload 监控服务。似乎 MQ 的解决办法更可靠一点。或者还是 CRD 来一套?这个是微服务导致的新问题,和分布式事务有关系。
0.8.0 更新 带来了 auth token支持,还有chartmuseum/ui,可以上传,跟我们做的很像啊😄 beego - The web framework used,国人产品,一种模板语言,简单的使用了 jQuery。
配置约束:
- 仓库 name 必须是 chartmuseum,前端依据 repo.name 来判断是不是用户上传的
- Helm 虽然不及 Operator 强大,但对于 k8s 新手来说很有帮助,因为马上有了 PaaS 平台的感觉,安装删除一个应用很方便,对开发帮助胜过运维。