etcd
一般
https://github.com/coreos/etcd
https://github.com/coreos/etcd/blob/master/Documentation/docs.md
https://coreos.com/etcd/docs/latest/getting-started-with-etcd.html Getting started with etcd
https://etcd.io/docs/v3.5/learning/ Design doc
A Closer Look at Etcd: The Brain of a Kubernetes Cluster
etcd 提供 KV service,watch service,lease service。 LeaseGrant 创建一个租约,当服务器在给定 time to live 时间内没有接收到 keepAlive 时租约过期。etcd提供了leader选举、分布式时钟、分布式锁、持续监控(watch)和集群内各个成员的 liveness 监控等功能。zookeer虽然也实现了类似的功能,但是不方便易用,还需借助Netflix提供的Apache Curator库。
一致性算法是用来解决一致性问题的,那么什么是一致性问题呢? 在分布式系统中,一致性问题(consensus problem)是指对于一组服务器,给定一组操作,我们需要一个协议使得最后它们的结果达成一致. 更详细的解释就是,当其中某个服务器收到客户端的一组指令时,它必须与其它服务器交流以保证所有的服务器都是以同样的顺序收到同样的指令,这样的话所有的服务器会产生一致的结果,看起来就像是一台机器一样.
对于一致性,k8s 采用乐观锁机制,Kubernetes通过定义资源版本字段实现了乐观并发控制,资源版本(ResourceVersion)字段包含在Kubernetes对象的元数据(Metadata)中。当服务器端收到数据时,将数据中的版本号与服务器端的做对比,如果不一致,则说明数据已经被修改,返回冲突错误。确实,我在 dashboard web ui 修改 yaml 的时候,经常会遇到这个错误。
http://jolestar.com/etcd-architecture/
谈谈 etcd 架构与设计对于一致性,k8s 采用乐观锁机制,Kubernetes通过定义资源版本字段实现了乐观并发控制,资源版本(ResourceVersion)字段包含在Kubernetes对象的元数据(Metadata)中。当服务器端收到数据时,将数据中的版本号与服务器端的做对比,如果不一致,则说明数据已经被修改,返回冲突错误。确实,我在 dashboard web ui 修改 yaml 的时候,经常会遇到这个错误。
watch
在把玩 k8s 过程中,感觉这个 watch 机制既神奇又危险:系统中不断变化的东西很多,watch 的人也很多,如何能在变化后快速的得到通知?乍一看这个 watch 不就是简单的观察者模式么?一切都 watch 搞定,这么简单的东西能 hold 住?感觉。。。 主要是这个里面 observer 和 subject 多了之后,之间的关系的维护和定位就复杂了。
Etcd 架构与实现解析 Etcd v3 支持从任意版本开始watch。包含两种 watcherGroup,一种是synced,一种是unsynced,如果 group 用户很大,则每次 sync 岂不很耗时?这个 watcherGroup 如果只关联到特定的 subject,就和上面经典模型一样,那 group 里面就小很多,但这样 group 就一堆了:有多少个 subject 就有多少 watcherGroup。 这就引入 gRPC proxy,etcd 的反向代理,请求会被聚合到 proxy,proxy 再分发给后面 etcd 集群。
+-------------+
| etcd server |
+------+------+
^ watch key A (s-watcher)
|
+-------+-----+
| gRPC proxy | <-------+
| | |
++-----+------+ |watch key A (c-watcher)
watch key A ^ ^ watch key A |
(c-watcher) | | (c-watcher) |
+-------+-+ ++--------+ +----+----+
| client | | client | | client |
| | | | | |
+---------+ +---------+ +---------+
这样 watch 操作就可以合并:如果多个 client watch 同一个的 key,则 proxy 会合并成一个 watch。key-value 发生变化时,etcd server 只用通知 proxy。由于 watch 是 grpc 流连接,大量的 watch etcd server 会造成 server 连接太多而负担太重。现阶段不做负载均衡,只是随机挑选一个作为server,当这个server挂掉再切换到其他的。 貌似很简单,我猜这个里面有很多 grpc 的编程细节。而且会有不少的限制比如sync不及时。 上面都是 watch key A,如果每个 client watch 的 key 都很分散,这个聚合就没有意义了。 然后,要开几个 proxy 呢?如果都把请求都引入这个 proxy,这个poxy就成了瓶颈了。k8s 中都是通过 api server 来 watch,所以 api server 也起到了 proxy 的作用了?
这里有个 issue,当节点有 2000 个时,etcd 成为瓶颈,换成 v3 api 后问题缓解。https://alexstocks.github.io/html/etcd.html 这里也谈到了性能。
Client 如果 watch 后自己不小心挂了或者代码忘了写停止 watch 的逻辑,etcd 自己应该有个 timeout 机制吧(TTL超时)。 etcd v3原理分析 https://yuerblog.cc/2017/12/10/principle-about-etcd-v3/
operator
直接 helm 安装 operator:
helm install stable/etcd-operator
这个会创建三个operator pod:backup, operator, restore。然后手工创建一个 etcd 集群:
kubectl create -f example/example-etcd-cluster.yaml
这个文件内容很简单:
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
## Adding this annotation make this cluster managed by clusterwide operators
## namespaced operators ignore it
# annotations:
# etcd.database.coreos.com/scope: clusterwide
spec:
size: 3
version: "3.2.13"
这个 CRD 会创建三个 etcd pod,还有两个服务(一个cluster监听2379和2380端口,一个cluster-client只监听2379端口)。通过创建的 k8s service 访问,看上去是负载均衡的,但是因为是 gRPC 长连接,会不会一直定位到某个节点?这里牵涉到 kube-proxy,即便 etcd client 能通过 nodeport service 调用 api 获取节点列表,但是因为无法访问,所以还是必须通过 nodeport 访问。
loadbalance
http://manguijie.top/2018/09/grpc-name-resolve-loadbalance 这个有点借鉴。 原来我看过的是这个 https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes-without-tears/
上面 emoji 和 voting 都是 gRPC 接口,web 会转化为 REST 接口 暴露给浏览器 和 bot。我对 voting 伸缩到 5 个,确实只有一个 pod CPU 占用率会有显示。web 使用 Node.js gRPC 访问 voting,文章推荐用 Linkerd 来解决。etcd 和这个有点不同:全部都是gRPC 而且通过 service 的 kube-proxy 访问。https://blog.bugsnag.com/envoy/ 这里说:
Kubernetes’ kube-proxy is essentially an L4 load balancer so we couldn’t rely on it to load balance the gRPC calls between our microservices.
kube-proxy 是 L4 路由,通过 iptable 或者 ipvs 来负载均衡,而 gRPC 是更上层的 http/2,L4 无法决定路由。
etcd operator 官方文档里面表明 in cluster 和 outside cluster 都是可以负载均衡的。outside 他用的是 loadbalance service,这样在 OpenStack 下就就是 HAProxy,L7 proxy,确实可以。内部的 ClusterIP 的呢?内部 service 访问都是用 DNS 的方式?这就是说 kube-proxy 只给 nodeport 用?https://cizixs.com/2017/03/30/kubernetes-introduction-service-and-kube-proxy/ pod ip 会变,所以用 service的 clusterip(固定 ip),这样说 service 流量都会经过 kube-proxy? nginx ingress 不会,他 watch service,然后直接负载均衡的方式访问 pod。
从另外一方面,对于一个访问 etcd 集群的请求,如何知道访问的是集群中的哪个节点?
curl https://example-client.default.svc:30373/metrics -k –cert ./etcd-client.crt –key ./etcd-client.key
返回数据有点多,换成 https://example-client.default.svc:30373/v2/stats/self 这个会显示节点名字,刚好可以用。遗憾的是这里和预想不同的是名字会在三个 pod name 中不断变化,说明负载均衡是起作用的。不对,这里的 HTTP 短链接肯定会被负载均衡,应该查看 gRPC 长连接是否负载均衡,这就更难查证了。找了几个 etcd goclient v2 v3,都没有 stats/self 对应的 API。放弃。
https://www.haproxy.com/blog/haproxy-1-9-2-adds-grpc-support/ haproxy 似乎不需要特殊的配置
https://coreos.com/etcd/docs/latest/op-guide/monitoring.html 这里有监控方法,本身有吐出metrics,可以给Prometheus用。用了 prometheus operator,包含grafana(现在能操作alert rule,默认密码是 prom-operator),创建一个ServiceMonitor来抓取数据。我在其 UI 上面已经看到有很多预定义target了,但是crd里面一个没有(原来在不同namespaces下)。https://github.com/coreos/prometheus-operator/blob/master/contrib/kube-prometheus/examples/example-app/servicemonitor-frontend.yaml servicemonitor 例子。
现在 operator 默认已经创建了一个 server,不要 CRD 了么?原来在不同 namespaces 下。 现在 target 定义为 servicemonitor,也就是只能监控 k8s service。
[centos@k8s-1 ~]$ kubectl get servicemonitors.monitoring.coreos.com --all-namespaces
NAMESPACE NAME AGE
default etcd 58s
mon happy-tiger-prometheus-ope-alertmanager 1h
mon happy-tiger-prometheus-ope-apiserver 1h
mon happy-tiger-prometheus-ope-coredns 1h
mon happy-tiger-prometheus-ope-kube-controller-manager 1h
mon happy-tiger-prometheus-ope-kube-etcd 1h
mon happy-tiger-prometheus-ope-kube-scheduler 1h
mon happy-tiger-prometheus-ope-kube-state-metrics 1h
mon happy-tiger-prometheus-ope-kubelet 1h
mon happy-tiger-prometheus-ope-node-exporter 1h
mon happy-tiger-prometheus-ope-operator 1h
mon happy-tiger-prometheus-ope-prometheus 1h
现在我写的default etcd CRD 不生效,但是上面的 mon happy-tiger-prometheus-ope-kubelet 是可以监控到所有4个节点的(prometheus ui->Targets),可以参考他的。几番折腾还是不行,查看 troubleshooting 这里Overview of ServiceMonitor tagging and related elements,
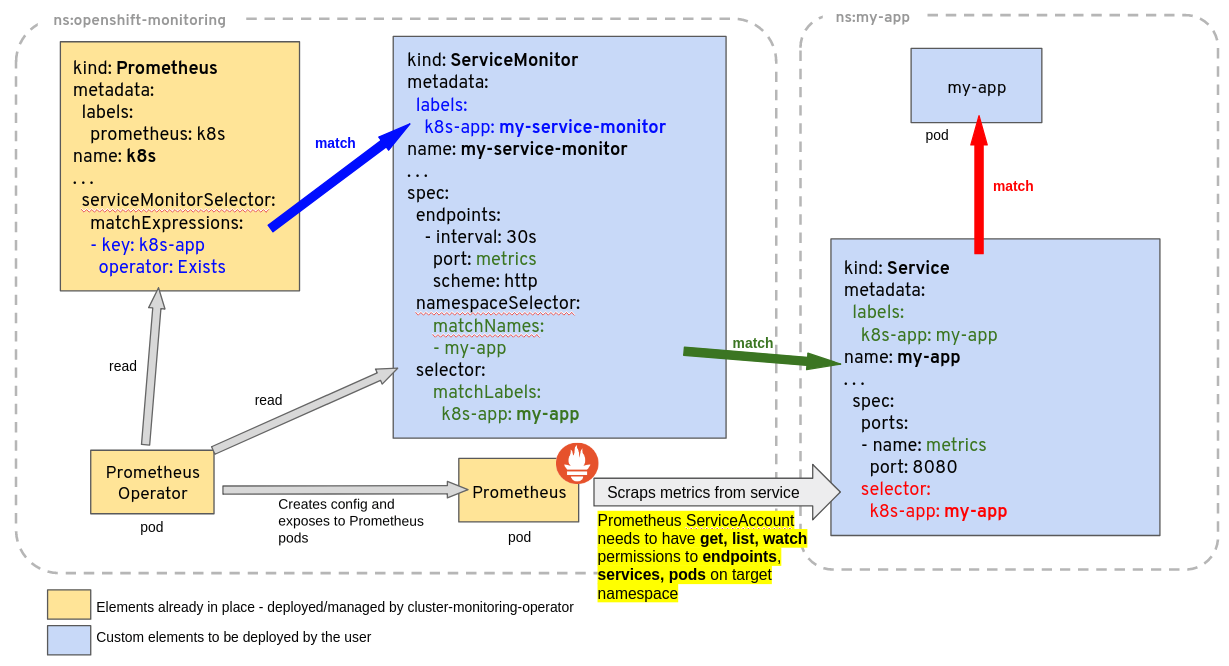
这个图挺好,原来prometheus crd本身也有个selector,我的ServiceMonitor CRD 要加个 release: happy-tiger label,颇为精妙,但是这样搞目的何在?存在多个prometheus server?多租户?
现在可以看到 prometheus reload了,也有了新的target,但是为DOWN状态,因为我的加密了。happy-tiger-prometheus-ope-apiserver 这个是HTTPS,可以参考。详细参数定义(这个文档似乎是自动生成的),不同参数 target ui那里报的错不同。 证书通过 secret 传给 prometheus,secret 从 default namespace来(etcd operator创建的),修改后会新创建一个prometheus server pod(而不是重启),operator会给这个pod赋予一个新的volumeMounts 包含我创建的secret。最后成功,最终的 CRD 定义:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-scrape
namespace: default
labels:
app: etcd
release: happy-tiger
spec:
selector:
matchLabels:
app: etcd
targetLabels:
- app
endpoints:
- honorLabels: true
interval: 30s
port: client
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ca/etcd-client-ca.crt
certFile: /etc/prometheus/secrets/etcd-ca/etcd-client.crt
keyFile: /etc/prometheus/secrets/etcd-ca/etcd-client.key
insecureSkipVerify: true
serverName: example-client.default.svc
namespaceSelector:
matchNames:
- default
tlsconfig这块不知道哪些是必须的,先全部填上。这个 ServiceMonitor 似乎确实是k8s service,matchLabels 匹配到了有重复,这是因为 etcd service 有两个。 这样其只能监听 k8s service 了?如何监听其他类型资源或者外部资源?
kubectl edit servicemonitors.monitoring.coreos.com happy-tiger-prometheus-ope-apiserver -n mon 这里面name不让修改,说是不存在,这里 operator 也很为难,因为修改后 watch 的点之类的全变了。
https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus 这个还提供 HA 方案。
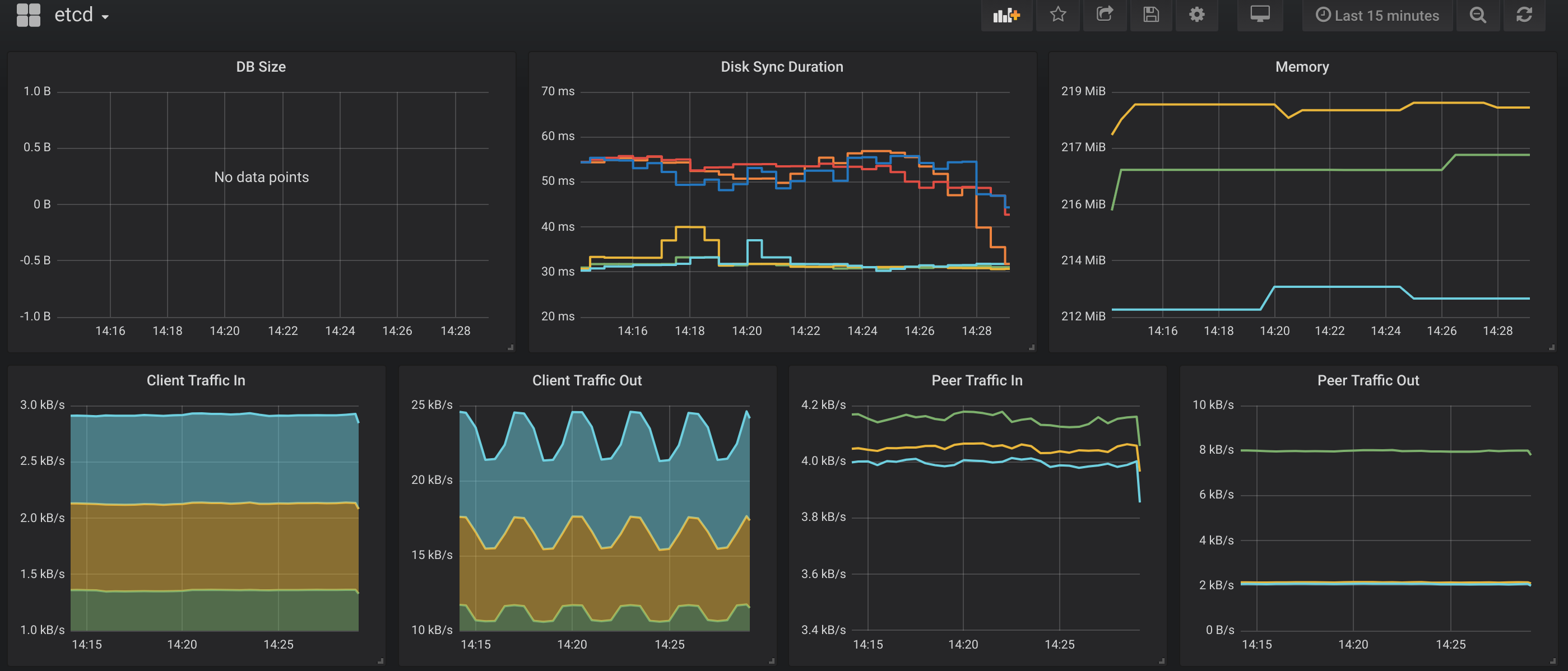
stack 类型的图表,和一般曲线图不同,整体颜色表示数量。peer trafic in 可能是节点之间的同步通信,client traffic in 是外部客户端的通信,从client看,有一个节点的 in 数据是其他两个的两倍,但是 out 就很均衡了。
玩玩这个集群
https://coreos.com/etcd/docs/latest/op-guide/grpc_proxy.html
kubectl run -i --tty --rm debug --image=quay.io/coreos/etcd:v3.2.13 --restart=Never -- sh
进入 pod console后:
ETCDCTL_API=3 etcdctl --endpoints=http://example-etcd-cluster-client:2379 member list --write-out table
这个会返回三个节点信息
etcd grpc-proxy start --endpoints=http://example-etcd-cluster-client:2379 --listen-addr=127.0.0.1:2379
这个命令不知道怎么打开debug
etcdctl --endpoints=http://localhost:2379 member list
unexpected status code 404 这说明这个grpc-proxy不够智能?不是,原来前面要加 ETCDCTL_API=3,member list返回:0, started, debug, , 127.0.0.1:23790,分开列出三个节点给–endpoints参数,还是一样,说明暂时还是没有办法判断是否这个proxy是监听了三个节点,不过应该如此。仔细看文档,原来member list返回的表示一个节点,只是没有名字而已,要加名字得额外参数。
backup https://github.com/coreos/etcd-operator/blob/master/doc/user/walkthrough/backup-operator.md 一个稳定集群来说 backup 是很重要的,这个 workthrough 是备份到 3 大云厂商的存储(abs, s3 & gcs)。其实自己备份也很简单:
ETCDCTL_API=3 ./etcdctl snapshot save snapshot.db
etcd-operator inside
主页也显示了如何动态操作集群的方法,比如手工删除一个 etcd pod,k8s 会创建一个新的。这个功能原来是 k8s 提供的,现在由 operator 来负责创建新的。
[centos@k8s-1 etcd-operator]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-ncfdnfrtkv 1/1 Running 0 46m
example-etcd-cluster-swvz82mp7j 1/1 Running 0 47m
example-etcd-cluster-zwsggd9wjn 1/1 Running 0 45m
kubectl delete pod example-etcd-cluster-swvz82mp7j —now
[centos@k8s-1 etcd-operator]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-8lfj7crfvh 1/1 Running 0 2m
example-etcd-cluster-ncfdnfrtkv 1/1 Running 0 49m
example-etcd-cluster-zwsggd9wjn 1/1 Running 0 48m
删除后 operator pod 里面有日志:
time="2018-09-29T03:07:06Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:06Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="running members: example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="cluster membership: example-etcd-cluster-swvz82mp7j,example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="removing one dead member" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="removing dead member \"example-etcd-cluster-swvz82mp7j\"" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="etcd member (example-etcd-cluster-swvz82mp7j) has been removed" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="removed member (example-etcd-cluster-swvz82mp7j) with ID (0)" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:14Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:22Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:22Z" level=info msg="running members: example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:22Z" level=info msg="cluster membership: example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:22Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:22Z" level=error msg="failed to reconcile: fail to add new member (example-etcd-cluster-bjwwqf4pjw): etcdserver: unhealthy cluster" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="running members: example-etcd-cluster-zwsggd9wjn,example-etcd-cluster-ncfdnfrtkv" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="cluster membership: example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-swvz82mp7j,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="removing one dead member" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="removing dead member \"example-etcd-cluster-swvz82mp7j\"" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="removed member (example-etcd-cluster-swvz82mp7j) with ID (8427753874285086848)" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:30Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:38Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:38Z" level=info msg="running members: example-etcd-cluster-ncfdnfrtkv,example-etcd-cluster-zwsggd9wjn" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:38Z" level=info msg="cluster membership: example-etcd-cluster-zwsggd9wjn,example-etcd-cluster-ncfdnfrtkv" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:38Z" level=info msg="added member (example-etcd-cluster-8lfj7crfvh)" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:38Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:46Z" level=info msg="skip reconciliation: running ([example-etcd-cluster-ncfdnfrtkv example-etcd-cluster-zwsggd9wjn]), pending ([example-etcd-cluster-8lfj7crfvh])" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:07:54Z" level=info msg="skip reconciliation: running ([example-etcd-cluster-ncfdnfrtkv example-etcd-cluster-zwsggd9wjn]), pending ([example-etcd-cluster-8lfj7crfvh])" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:02Z" level=info msg="skip reconciliation: running ([example-etcd-cluster-ncfdnfrtkv example-etcd-cluster-zwsggd9wjn]), pending ([example-etcd-cluster-8lfj7crfvh])" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:10Z" level=info msg="skip reconciliation: running ([example-etcd-cluster-ncfdnfrtkv example-etcd-cluster-zwsggd9wjn]), pending ([example-etcd-cluster-8lfj7crfvh])" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:18Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:18Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:26Z" level=info msg="Start reconciling" cluster-name=example-etcd-cluster pkg=cluster
time="2018-09-29T03:08:26Z" level=info msg="Finish reconciling" cluster-name=example-etcd-cluster pkg=cluster
红色swvz82mp7j是被删除,绿色 example-etcd-cluster-8lfj7crfvh 是新创建的 pod。从集群中移除挂掉的成员,从上面看是由 operator 完成的,添加成员这个可以由 operator 来发起。这些事情如果用 helm chart 来做就很笨拙,因为他只能固定加入到第一个节点,详细看 Consul 条目。
查看新创建 etcd pod YAML 定义:
- command:
- /usr/local/bin/etcd
- --data-dir=/var/etcd/data
- --name=example-etcd-cluster-8lfj7crfvh
- --initial-advertise-peer-urls=http://example-etcd-cluster-8lfj7crfvh.example-etcd-cluster.jx.svc:2380
- --listen-peer-urls=http://0.0.0.0:2380
- --listen-client-urls=http://0.0.0.0:2379
- --advertise-client-urls=http://example-etcd-cluster-8lfj7crfvh.example-etcd-cluster.jx.svc:2379
- --initial-cluster=example-etcd-cluster-ncfdnfrtkv=http://example-etcd-cluster-ncfdnfrtkv.example-etcd-cluster.jx.svc:2380,
example-etcd-cluster-8lfj7crfvh=http://example-etcd-cluster-8lfj7crfvh.example-etcd-cluster.jx.svc:2380,
example-etcd-cluster-zwsggd9wjn=http://example-etcd-cluster-zwsggd9wjn.example-etcd-cluster.jx.svc:2380
- --initial-cluster-state=existing
每个参数的具体定义看这里。–initial-cluster 指定集群的所有成员,这样新节点就可以加入到集群中。Operator 只需要传递参数就可以了吧?上面的 “added member” 是为何意?pkg/cluster/reconcile.go addOneMember 方法里面,先调用etcdcli.MemberAdd,这个是 etcd API,然后 createPod。也就是说两步都做了,而这个也是官方 Change etcd cluster size 的步骤:1) 先运行 etcdctl member add 命令,这个会返回一个 member.ID,这个 ID 只在 etcd operator 里面使用(kubectl edit 看不到),k8s 不使用。暂时不知道这个 ID 和 name 有何不同。2) 根据命令返回的ID createPod。对于一个新的 etcd 节点来说,已有的节点列表是未知的,所以要先用 etcdctl member add 的返回的节点列表作为 –initial-cluster 参数。所以需要 1)步骤,但是对于这里的 operator 来说,因为自己已经维护了节点列表,所以1)步骤似乎是没有必要的。这就引出了 operator 的一个尴尬:集群的状态和自己维护的状态是重复的。更像一个 master-slave 中的 master,对于 etcd/consul 这种对等架构来是个奇怪的存在,而对于Failover(故障转移)这种功能是项目自己负责呢还是 operator 来负责?如果 operator 自己挂了呢?我的建议是:operator 和集群自己的功能一定不要重复,他们应该互为补充。
1) 和 2) 之间没有用事务,也就是可能 1) 成功运行了但是 2) 没有运行。
MemberAdd 时的代码有些意思:
ctx, cancel := context.WithTimeout(context.Background(), constants.DefaultRequestTimeout)
resp, err := etcdcli.MemberAdd(ctx, []string{newMember.PeerURL()})
cancel()
具体解释可以看 GoLang 条目里面的 context 解释,上面的 MemberAdd 是 block 的,所以可以马上调用 cancel。
Etcd cluster 定义放在 kubectl edit etcdclusters.etcd.database.coreos.com 里面,为什么不搞成一数组呢?这样数据更清晰。
一次重启节点后,operator 创建的 pod 没有启动,状态为『已结束:Completed』,operator pod 有日志:level=warning msg="all etcd pods are dead." 这里 issue 说是已知问题,因为默认数据没有序列化,既然存储对 etcd 性能关系巨大并且推荐使用 SSD,这应该是个很重要的特征,但是现在还是不可用,localstorage也不支持。
更多可以参考官方设计文档 https://github.com/coreos/etcd-operator/tree/master/doc/design