测试下 Rook
CNCF首个云原生存储项目——ROOK,基于成熟的 Ceph。
https://rook.io/docs/rook/v0.8/ceph-quickstart.html
Design Doc https://github.com/rook/rook/tree/master/design
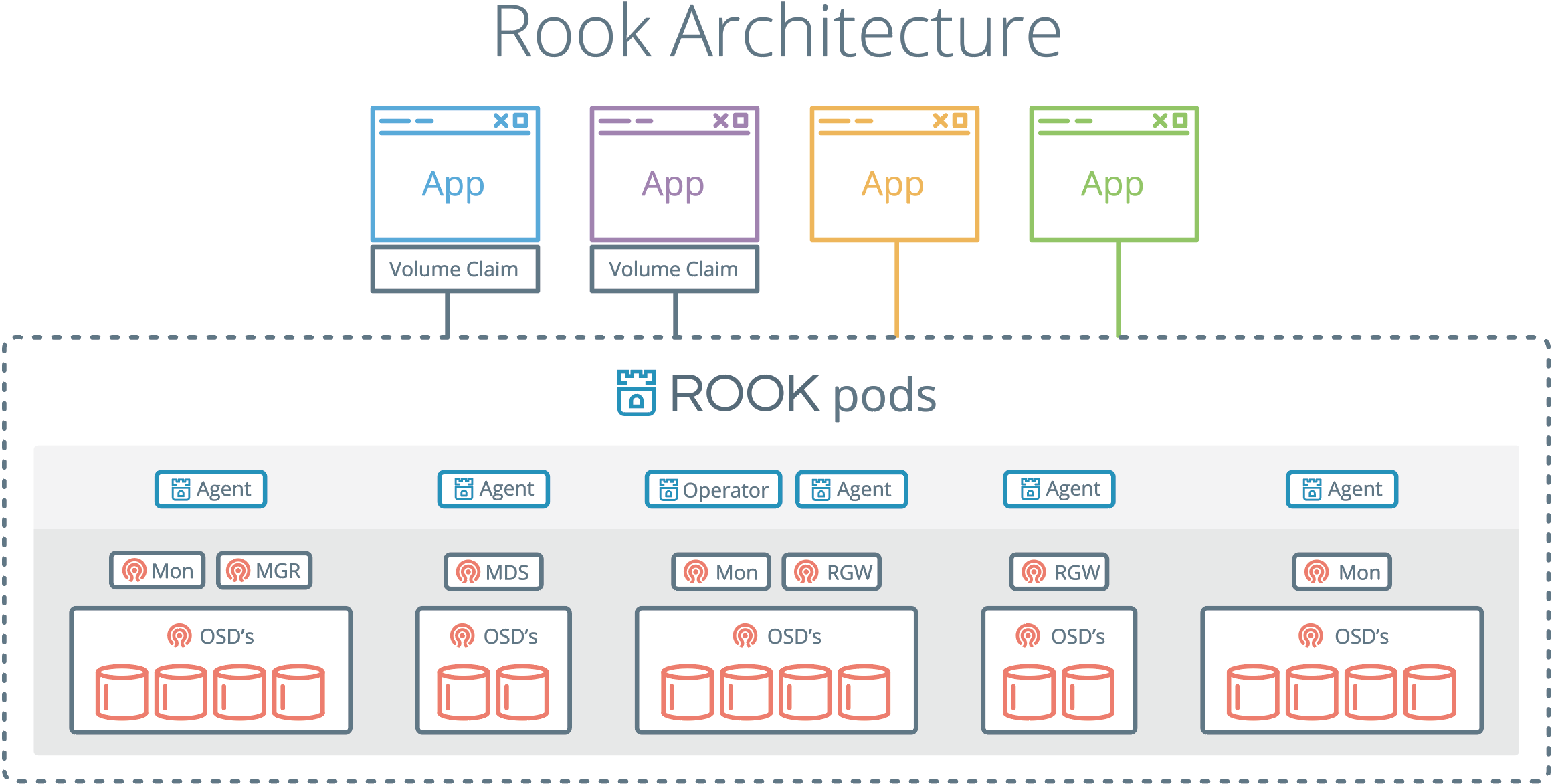
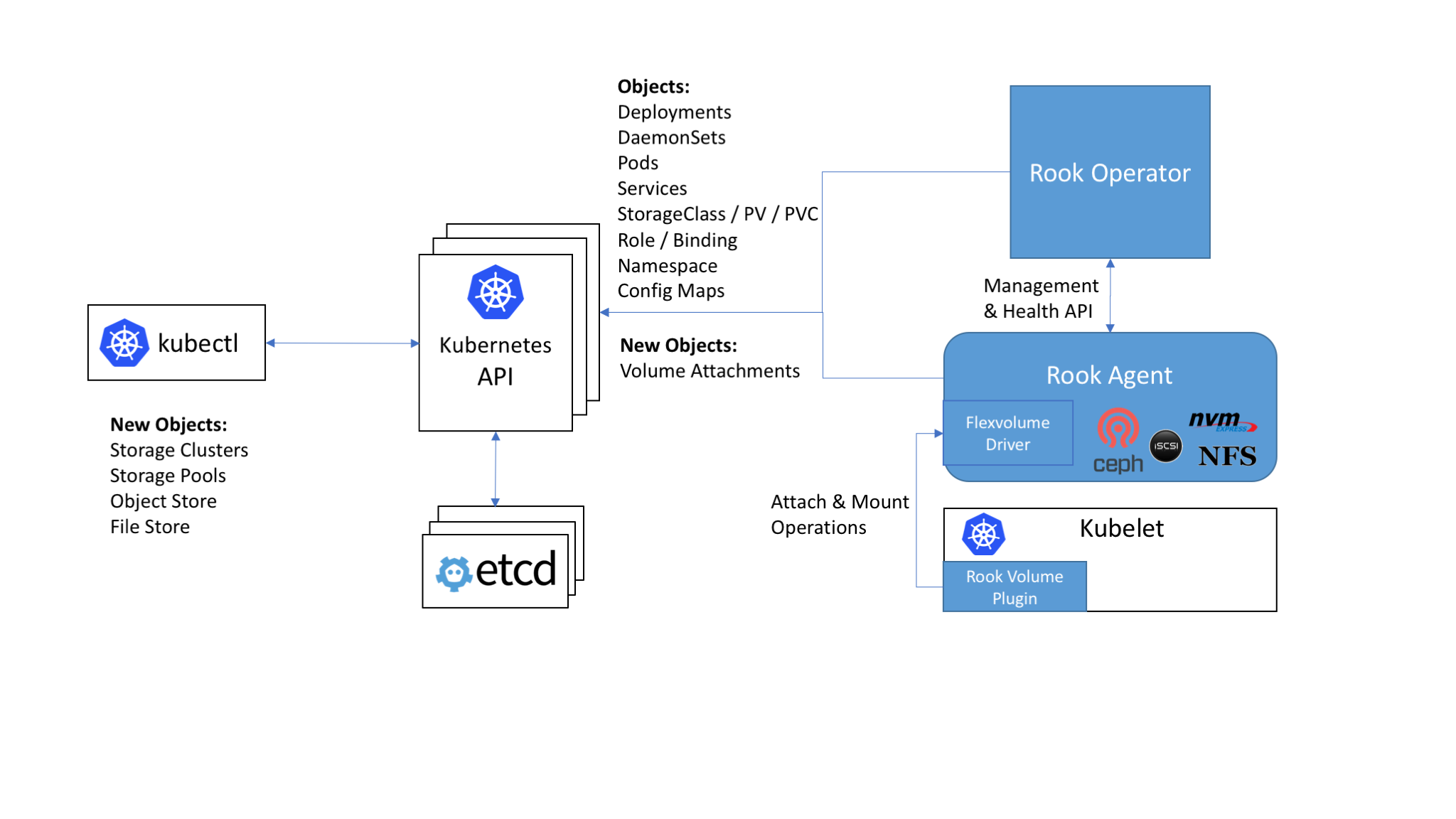
Ref https://rook.io/docs/rook/v0.8/
怎么保证磁盘的访问性能呢?不过 Ceph 部署比较复杂,这样统一管理似乎也有优势,更重要的是可以监控起来,也可以更容易的伸缩。总的来说,如果是个分布式系统,则迁移到 k8s 上是有优势的。 这里看 volume plugin 会直接分区和 Mount 磁盘?如果这样就和自己安装 Ceph 性能差别不大了。 这里连接磁盘方式就有多种了。上面是直接 mount 节点上面的磁盘,但是一般架构存储和计算是分开的,存储一般需要较多的磁盘,机架格局和计算不同。如此需要部署一个单独的 k8s 存储集群了?
原来它用的是 FlexVolume 这种扩展,https://rook.io/docs/rook/v0.8/flexvolume.html Flexvolume 似乎只是一种让 kubelet 直接运行的二进制文件,放在 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/下面,这些不是容器镜像。使用这些文件可以直接对节点上的磁盘操作,比如分区和挂载,似乎和每个节点上安装 ceph-common 一样,但是这个是由 k8s 来管理安装和更新,不用手工干预。为什么不放 pod 里面?pod 无法访问磁盘?不对啊,osd server 是直接访问的。问题是 osd server 能直接访问节点的磁盘比如/dev/vdb 么?
[centos@k8s-4 ~]$ sudo ls /var/lib/rook/osd0 -lh
总用量 44K
lrwxrwxrwx 1 root root 58 9月 27 07:07 block -> /dev/disk/by-partuuid/8f0c90b3-e76f-47f7-940f-79165b5f54c1
lrwxrwxrwx 1 root root 58 9月 27 07:07 block.db -> /dev/disk/by-partuuid/9c5ad55d-764e-4425-a688-7d16171629d1
lrwxrwxrwx 1 root root 58 9月 27 07:07 block.wal -> /dev/disk/by-partuuid/d1dc01e5-e5eb-45c6-a50e-0b11d05a3a99
[centos@k8s-4 ~]$ lsblk --output NAME,PARTLABEL,PARTUUID
NAME PARTLABEL PARTUUID
vda
└─vda1
vdb
├─vdb1 ROOK-OSD0-WAL d1dc01e5-e5eb-45c6-a50e-0b11d05a3a99
├─vdb2 ROOK-OSD0-DB 9c5ad55d-764e-4425-a688-7d16171629d1
└─vdb3 ROOK-OSD0-BLOCK 8f0c90b3-e76f-47f7-940f-79165b5f54c1
这样就很清楚了,容器还是以文件的形式来访问宿主机,而上面的符号连接应该是由 rook flexvolume 来完成的。UNIX 任何皆文件的哲学果然强大。这样就能理解为什么重建 ceph cluster 时为什么要删除/var/lib/rook 目录了。
其 quickstart 默认用的是主机磁盘文件系统:If you are using dataDirHostPath to persist rook data on kubernetes hosts, make sure your host has at least 5GB of space available on the specified path. 为什么不提供直接 mount 主机上面的磁盘 /dev/sdb 这种方式?https://rook.io/docs/rook/v0.8/ceph-cluster-crd.html#storage-selection-settings deviceFilter * sdb: Only selects the sdb device if found,直接这样就可以?这个是节点上面的磁盘吧,容器能直接访问磁盘?如果某个节点没有磁盘,那这个上面也不会安装 Ceph?Operator 这么智能?我可以搞一个有多个磁盘的裸机然后加入已有集群。
按照 https://rook.io/docs/rook/v0.8/ceph-quickstart.html 安装之。默认磁盘时安装在 host 机器上的 /var/lib/rook,我 3 个节点,会有 3 个 osd pod,一个 mgr pod,3 个 monitor pod,每个节点都有一个。整个速度挺快的,比自己整 ceph 集群快多了。mgr pod 就是自带的 Dashboard web ui。ceph version 12.2.7 luminous (stable),operator,果然比我 Ceph 门外汉更专业。Dashboard 可实时刷新数据,用的是轮训,感觉监控起来比命令行要方便。不过看不到 pool 下面的对应 pvc 的卷。
现在添加磁盘,先给 k8s-4 节点分配一个新硬盘,然后设置 cluster.yaml useAllDevices: true,这会对节点上所有的非操作系统的磁盘分区。kubectl apply 没变化,只能全删除后重建。但是这次一个 osd server 也没有。osd-prepare-k8s-4 上有日志:
2018-09-13 09:15:57.545604 I | exec: Running command: lsblk /dev/vdb --bytes --pairs --output NAME,SIZE,TYPE,PKNAME
2018-09-13 09:15:57.548315 I | exec: Running command: udevadm info --query=property /dev/vdb1
2018-09-13 09:15:57.550359 I | sys: non-rook partition:
2018-09-13 09:15:57.550378 I | exec: Running command: udevadm info --query=property /dev/vdb
2018-09-13 09:15:57.552510 I | cephosd: skipping device vdb that is in use (not by rook). fs: , ownPartitions: false
2018-09-13 09:15:57.562849 I | cephosd: configuring osd devices: {"Entries":{}}
不能自己分区?可能是为了保护数据。好吧,我删除 /dev/vdb1 分区,然后重建集群。为什么每次都要重建?现在有一个 osd server 了!好耶!有了这个 operator,重建 ceph 集群真是好方便!进入到 k8s-4,/dev/vdb 被分成了 3 个区,但是没有看到那个容器挂载了这些分区。对于曾经加入 ceph 过的磁盘,再次加入集群时可以不用删除已有分区。
kubectl apply -f storageclass.yaml 创建 StorageClass:
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 1
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
# Specify the namespace of the rook cluster from which to create volumes.
# If not specified, it will use `rook` as the default namespace of the cluster.
# This is also the namespace where the cluster will be
clusterNamespace: rook-ceph
# Specify the filesystem type of the volume. If not specified, it will use `ext4`.
fstype: xfs
相当简单,不用配置 IP 之类的,和 Openstack 环境下 cinder 挂载类似。然后就可以 helm chart postgresql创建 了。在 postgresql pod 所在的节点上面可以看到 dmesg 里面有:
libceph: mon1 10.100.238.135:6790 session established
rbd: rbd0: capacity 8589934592 features 0x1
[centos@k8s-2-new ~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 366K 0 disk
vda 252:0 0 20G 0 disk
└─vda1 252:1 0 20G 0 part /
rbd0 251:0 0 8G 0 disk /var/lib/kubelet/pods/13be1c5a-b73b-11e8-86d6-aa90b3cbae01/volumes/ceph.rook.io~rook-ceph-system/pvc-139b6b86-b73b-11e8-86d6-aa90b3cbae01
用的和我自己搭建 Ceph 差不多的工具库,不知道这次会不会出现 libceph socket closed 导致节点高负载的问题。ceph 版本不同,provisioner 也不同,希望不会出现吧。(想不到困扰一时的问题这么解决?😂)
上面的 10.100.238.135 是建立在 k8s-4上面 service 的 ClusterIP,这个配置没有写在 StorageClass 里面,我猜是 provisioner 做的自动配置。
怎么通过 ceph-common 命令查看上面的集群呢?https://rook.io/docs/rook/v0.8/toolbox.html 考虑到了,不错。kubectl create -f toolbox.yaml 一行代码就搞定(examples/kubernetes/ceph 这个样例代码做的不错)。文档有问题,连接 pod 的名字不对。这样就可以验证删除 pv 后 Ceph 里面 pool/pv 是否也删除:确实删除了!
验证下稳定性:重启唯一的 osd 节点 k8s-4,结果挂了:qcow2: Image is corrupt; cannot be opened read/write。难道 ceph 把系统盘给修改了?也修复不好,没办法,只能重建。重建后因为我 hostname 没有改,k8s-4 上面自动运行了一个 osd server,但是有错误:
bluestore(/var/lib/rook/osd0/block) _read_bdev_label failed to open /var/lib/rook/osd0/block: (2) No such file or directory
可能 operator 已经记录了 k8s-4 上面有一个磁盘,并且已经 prepare 过,所以认为这个目录下应该对应的配置文件。我觉得重新 repare 下应该可以,现在不知道方法,手工删除 rook 目录,重启 k8s-4。得重建集群了。
[centos@k8s-1 ceph]$ kubectl delete -f cluster.yaml
namespace "rook-ceph" deleted
serviceaccount "rook-ceph-cluster" deleted
role.rbac.authorization.k8s.io "rook-ceph-cluster" deleted
rolebinding.rbac.authorization.k8s.io "rook-ceph-cluster-mgmt" deleted
rolebinding.rbac.authorization.k8s.io "rook-ceph-cluster" deleted
cluster.ceph.rook.io "rook-ceph” deleted
删除卡在最后一步,强制删除后重新安装会显示 cluster.ceph.rook.io “rook-ceph” unchanged,这会导致后面 pod 都不会创建出来。
[centos@k8s-1 ceph]$ kubectl get clusters.ceph.rook.io -n rook-ceph
NAME AGE
rook-ceph 18h
[centos@k8s-1 ceph]$ kubectl delete clusters.ceph.rook.io rook-ceph -n rook-ceph
cluster.ceph.rook.io "rook-ceph" deleted
也是卡在这一步。似乎 CRD 删除容易出现这种问题,ceph-teardown 已经记录了,要删除 CRD 的 finalizer。
然后问题依旧。只能 kubectl delete -f operator.yaml 再重建。
既然在 k8s 中管理 Ceph,一个问题就是动态管理。比如如何添加一个新的磁盘后把这个磁盘加入到 ceph 集群中,这些都能通过操作 CRD 而不用了解 ceph 知识么?添加新磁盘后,pod 的 ceph monitor 会同步更新么?这里描述说:如果 useAllNodes 设置为 false,Nodes can be added and removed over time by updating the Cluster CRD
创建一个新节点,并把其加入到 k8s 中。检测系统,发现 rook-ceph-system 下已经有 rook-ceph-agent & rook-discover pod 运行了(都是守护进程集),rook-ceph namespace 下面并没有新的 ceph-monitor pod。新节点已经 load libceph rbd kernel module,是 rook 加的?新节点上还没有安装 ceph-common 包。然后新节点关机加入新磁盘,启动。rook-discover 日志已经能发现新磁盘 /dev/vdb,但是没有创建对应的 osd pod。我集群 useAllNodes 为 true,应该为自动添加啊。这时候我发现新节点里面 rook-agent 里面有好多错误:
github.com/rook/rook/vendor/github.com/rook/operator-kit/watcher.go:76: Failed to list *v1beta1.Cluster: Get https://10.96.0.1:443/apis/ceph.rook.io/v1beta1/clusters?resourceVersion=0: dial tcp 10.96.0.1:443: i/o timeout
关闭新节点(fedora)上面的防火墙,还是老样子。命令行下 curl -k url 有错误,其他老节点都没问题。dmesg 下面有如下错误:
overlayfs: unrecognized mount option "context="system_u:object_r:container_file_t:s0:c514" or missing value
换成 centos,没有上面错误,但是还是没有 osd pod。这个 Q&A OSD pods are not created on my devices 写了些原因,不过都和我的不一样,不过还是安装起解决办法删除 rook-ceph-operator pod,这样会有一个新的 osd-prepare,但是其运行错误:
2018-09-18 06:28:51.356903 I | partition vda: Could not create partition 2 from 1181696 to 43124735
2018-09-18 06:28:51.356947 I | partition vda: Unable to set partition 2's name to 'ROOK-OSD13-DB'!
2018-09-18 06:28:51.356953 I | partition vda: Error encountered; not saving changes.
failed to configure devices. failed to config osd 13. failed format/partition of osd 13. failed to partion device vda. failed to partition /dev/vda. Failed to complete 'partition vda': exit status 4.
找了下,原来 ceph 需要磁盘至少 30GB,这个错误提示也太隐晦了吧!ceph 果然是古老的东西。这些错误是 ceph 报出来的,这个新节点上面没有安装 ceph-common 客户端。提高磁盘容量之后 osd pod 就创建了。就是这个必须要删除 operator 才能生效有点蹩脚。如果我一早就预备 30gb 就没这个问题?不可能吧,因为不重建 operator pod,连 prepare pod 都不会出来。这个新节点上面 monitor 并没有,可能觉得 3 个就够了。
然后 poweroff 这个节点,节点上的 osd pod 没有迁移到其他节点,状态为『此容器正在等待中』,这是合理的,因为磁盘已经不在了。Ceph Dashboard 中仍显示为 HEALTH_OK。
然后 kubectl delete node,这个时候 pod 为 『此容器组已经出错』0/5 nodes are available: 1 node(s) were not ready, 1 node(s) were out of disk space, 4 node(s) didn’t match node selector. OSD 副本集上有很多选择器:app: rook-ceph-osd;ceph-osd-id: 15;pod-template-hash: 1499787393;rook_cluster: rook-ceph,但是我看各个节点上面都没有这些标签,不知道是怎么匹配的。Ceph Dashboard 没有任何变化。
重建 operator pod,没啥用,k8s 资源都要手工删除。Ceph Dashboard 还是显示已经删除的 OSD Server。
Fedora 重新试一下,使用系统 docker-ce,猜测 rook-agent 网络不通应该是 ipvs 问题(要升级 kube-proxy),现在 agent 没有 timeout 的问题了。再这个节点上测试上面功能,一样问题。提了个 issue。
第二天来发现 mon pod 已经迁移到新节点上,自动迁移已靠近 osd pod?总数还是 3 个。但是有错误:rook error: unknown flag: –config-dir,其他 mon pod 都好好的啊,奇怪。到 hub.docker.com 检查后把镜像版本从 master 改为 v0.8.2 就可以了,这帮人开发瞎搞。
我 30GB 硬盘,ceph 自动分区后为:
# Start End Size Type Name
1 2048 1181695 576M Linux filesyste ROOK-OSD0-WAL
2 1181696 43124735 20G Linux filesyste ROOK-OSD0-DB
3 43124736 62914526 9.4G Linux filesyste ROOK-OSD0-BLOCK
为什么block只有 10Gb,哪里配置?databaseSizeMB & journalSizeMB,去掉这些我修改的参数,重新部署(不需删除已有分区),现在 DB 分区只有 1G。
单独添加某个磁盘还不支持,currently in Rook v0.7, there is only official support for adding and removing entire nodes (with all their disks and directories).
一个节点上如有磁盘要加入 Ceph,则起一个 pod 即可。感觉有点不踏实:如果这个 pod killed 了呢?当然 k8s liveness 会帮忙起一个 pod,新建 pod 也需要其加入已有的 Ceph cluster,这个过程如果很完美则比自己维护一个 ceph 集群可靠性更好。这个是 failed over 么?节点上如果起多个 pod 来提供 HA 可以么?有状态的没法这么干吧。
运行一段时间后,节点还是失去反应,libceph socket closed (con state connecting),好的一点在于日志吐出并不块,CPU 占用率也不高,但是系统还是失去响应,得强制重启。可能原因在于我已经删除了 ceph cluster,它为了保证数据完整,内核不让重启。现在似乎不少节点无法命令行重启。
没有自动创建的 issue 无人解答,自己探索。
<== pkg/operator/ceph/cluster/osd/spec.go makeJob 会创建 prepare Job
<== pkg/operator/ceph/cluster/osd/osd.go startProvisioning,这个方法会遍历 cluster.Storage.Nodes 所有节点,没看到有条件的创建 job
<== pkg/operator/ceph/cluster/osd/osd.go Start
<== pkg/operator/ceph/cluster/cluster.go createInstance
<== pkg/operator/ceph/cluster/controller.go onAdd & handleUpdate ( handleUpdate 实为 onUpdate)
这些 on 方法都是 watch “kind: rook.Cluster” 资源了吧。只监听 Cluster 资源当然不会在添加新节点的时候触发以上过程了!怪不得有地方建议直接删除 Operator pod,这种有点粗鲁。可以 edit cluster,useAllNodes:false,然后加上新节点的 ip,这样可以吧。不知道这样是否会对已有的节点会造成影响。
修改 useAllNodes: false,然后在 nodes 下面定义的一个节点 k8s-4 。部署集群后,一切正常,现在只有一个 OSD server。修改 cluster.yaml(kubectl edit 里面没有节点部分),在加入一个新的节点 k8s-new-node,OSD server 都能顺利创建出来。Operator 有如下日志:
2018-09-27 07:12:00.214724 I | op-cluster: update event for cluster rook-ceph
2018-09-27 07:12:00.214800 I | op-cluster: The list of nodes has changed
2018-09-27 07:12:00.214811 I | op-cluster: update event for cluster rook-ceph is supported, orchestrating update now
2018-09-27 07:12:00.260502 I | op-mon: start running mons
2018-09-27 07:12:00.265528 I | cephmon: parsing mon endpoints: a=10.110.87.214:6790,b=10.110.186.133:6790,c=10.97.189.6:6790
2018-09-27 07:12:00.265684 I | op-mon: loaded: maxMonID=2, mons=map[b:0xc4209c76c0 c:0xc4209c7740 a:0xc4209c7640], mapping=&{Node:map[c:0xc420318840 a:0xc4203187e0 b:0xc420318810] Port:map[]}
2018-09-27 07:12:00.276099 I | op-mon: saved mon endpoints to config map map[data:a=10.110.87.214:6790,b=10.110.186.133:6790,c=10.97.189.6:6790 maxMonId:2 mapping:{"node":{"a":{"Name":"k8s-2-new","Hostname":"k8s-2-new","Address":"192.168.51.12"},"b":{"Name":"k8s-3-new","Hostname":"k8s-3-new","Address":"192.168.51.13"},"c":{"Name":"k8s-4","Hostname":"k8s-4","Address":"192.168.51.14"}},"port":{}}]
2018-09-27 07:12:00.276785 I | cephconfig: writing config file /var/lib/rook/rook-ceph/rook-ceph.config
2018-09-27 07:12:00.277239 I | cephconfig: copying config to /etc/ceph/ceph.conf
2018-09-27 07:12:00.277466 I | cephconfig: generated admin config in /var/lib/rook/rook-ceph
2018-09-27 07:12:00.289078 I | op-mon: Found 1 running nodes without mons
2018-09-27 07:12:00.289120 I | op-mon: ensuring mon rook-ceph-mon-a (a) is started
2018-09-27 07:12:00.394787 I | op-mon: mon a running at 10.110.87.214:6790
2018-09-27 07:12:00.466938 I | op-mon: mon b running at 10.110.186.133:6790
2018-09-27 07:12:09.280754 I | op-osd: 2 of the 2 storage nodes are valid
2018-09-27 07:12:09.280775 I | op-osd: checking if orchestration is still in progress
2018-09-27 07:12:09.283427 I | op-osd: start provisioning the osds on nodes, if needed
2018-09-27 07:12:09.310899 I | op-osd: avail devices for node k8s-4: [{Name:vdb FullPath: Config:map[]}]
2018-09-27 07:12:09.315175 I | op-osd: Removing previous provision job for node k8s-4 to start a new one
2018-09-27 07:12:09.335221 I | op-osd: batch job rook-ceph-osd-prepare-k8s-4 still exists
2018-09-27 07:12:11.341452 I | op-osd: batch job rook-ceph-osd-prepare-k8s-4 deleted
2018-09-27 07:12:11.351147 I | op-osd: osd provision job started for node k8s-4
2018-09-27 07:12:11.455374 I | op-osd: avail devices for node k8s-new-node: [{Name:vdb FullPath: Config:map[]} {Name:sda FullPath: Config:map[]} {Name:vda FullPath: Config:map[]}]
2018-09-27 07:12:11.466879 I | op-osd: osd provision job started for node k8s-new-node
2018-09-27 07:12:11.466905 I | op-osd: start osds after provisioning is completed, if needed
2018-09-27 07:12:11.475870 I | op-osd: osd orchestration status for node k8s-4 is starting
2018-09-27 07:12:11.475917 I | op-osd: osd orchestration status for node k8s-new-node is starting
2018-09-27 07:12:11.475927 I | op-osd: 0/2 node(s) completed osd provisioning
2018-09-27 07:12:12.519123 I | op-osd: osd orchestration status for node k8s-4 is computingDiff
2018-09-27 07:12:12.652414 I | op-osd: osd orchestration status for node k8s-4 is orchestrating
2018-09-27 07:12:12.665979 I | op-osd: osd orchestration status for node k8s-4 is completed
2018-09-27 07:12:12.666037 I | op-osd: starting 1 osd daemons on node k8s-4
2018-09-27 07:12:12.684588 I | op-osd: deployment for osd 0 already exists. updating if needed
2018-09-27 07:12:12.688043 I | op-k8sutil: updating deployment rook-ceph-osd-0
2018-09-27 07:12:14.713141 I | op-k8sutil: finished waiting for updated deployment rook-ceph-osd-0
2018-09-27 07:12:14.713224 I | op-osd: started deployment for osd 0 (dir=false, type=)
2018-09-27 07:12:14.897416 I | op-osd: osd orchestration status for node k8s-new-node is computingDiff
2018-09-27 07:12:15.126273 I | op-osd: osd orchestration status for node k8s-new-node is orchestrating
2018-09-27 07:12:30.533344 I | op-osd: osd orchestration status for node k8s-new-node is completed
2018-09-27 07:12:30.533379 I | op-osd: starting 1 osd daemons on node k8s-new-node
2018-09-27 07:12:30.564077 I | op-osd: started deployment for osd 1 (dir=false, type=)
2018-09-27 07:12:30.596881 I | op-osd: 2/2 node(s) completed osd provisioning
2018-09-27 07:12:30.596940 I | op-osd: checking if any nodes were removed
2018-09-27 07:12:30.645332 I | op-osd: processing 0 removed nodes
2018-09-27 07:12:30.645360 I | op-osd: done processing removed nodes
2018-09-27 07:12:30.645369 I | op-osd: completed running osds in namespace rook-ceph
2018-09-27 07:12:30.645518 I | exec: Running command: ceph osd unset noscrub --cluster=rook-ceph --conf=/var/lib/rook/rook-ceph/rook-ceph.config --keyring=/var/lib/rook/rook-ceph/client.admin.keyring --format json --out-file /tmp/956465413
2018-09-27 07:12:31.559860 I | exec: noscrub is unset
2018-09-27 07:12:31.560148 I | exec: Running command: ceph osd unset nodeep-scrub --cluster=rook-ceph --conf=/var/lib/rook/rook-ceph/rook-ceph.config --keyring=/var/lib/rook/rook-ceph/client.admin.keyring --format json --out-file /tmp/041764000
2018-09-27 07:12:32.695130 I | exec: nodeep-scrub is unset
2018-09-27 07:12:32.695290 I | op-cluster: Done creating rook instance in namespace rook-ceph
2018-09-27 07:12:32.707479 I | op-cluster: succeeded updating cluster in namespace rook-ceph
2018-09-27 07:12:32.707735 I | op-cluster: update event for cluster rook-ceph
2018-09-27 07:12:32.707772 I | op-cluster: update event for cluster rook-ceph is not supported
2018-09-27 07:12:32.710587 I | op-cluster: update event for cluster rook-ceph
2018-09-27 07:12:32.710663 I | op-cluster: update event for cluster rook-ceph is not supported
修改 cluster.yaml,删除 name: “k8s-new-node”,osd pod 等会就会被删除,不错。
按设计来说,operator 确实只需监听 CRD 资源的定义就可以,毕竟这个描述定义所有的内容。但是如何处理 useAllNodes:true?在代码里面监听节点变化当然可以,但如此一来,监听的东西就多的去了,能否用声明式的方法写在 CRD 描述里面?这样监听的订阅和取消都由外部处理。
“kind: Cluster” 指的是 ceph cluster,所以字面上确实和 k8s cluster 不同,这点要注意。
加入新节点没有监听还可以解释,已加入的节点挂起是否监听呢?如果没有这个可用性大打折扣啊。
只监听 CRD 就足够的话,还要 discover & agent pod 做什么呢?其实这两个守护进程可以做到 『watch k8s cluster』同样效果。。。
这个现在在 0.9 milestone 中 https://github.com/rook/rook/milestone/10
Cluster 删除难的问题反复出现,ceph-teardown 写了要删除 CRD 的 finalizer。今天查了下根源,删除时 operator 有日志:
2018-09-27 06:17:08.606342 I | op-cluster: cluster rook-ceph has a deletion timestamp
2018-09-27 06:17:08.616067 I | op-cluster: waiting for volume attachments in cluster rook-ceph to be cleaned up. Retrying in 2s.
2018-09-27 06:17:36.696588 W | op-cluster: exceeded retry count while waiting for volume attachments for cluster rook-ceph to be cleaned up. vols: [{TypeMeta:{Kind:Volume APIVersion:rook.io/v1alpha2} ObjectMeta:{Name:pvc-8cb3ff34-bc95-11e8-86d6-aa90b3cbae01 GenerateName: Namespace:rook-ceph-system SelfLink:/apis/rook.io/v1alpha2/namespaces/rook-ceph-system/volumes/pvc-8cb3ff34-bc95-11e8-86d6-aa90b3cbae01 UID:8ebfb7f1-bc95-11e8-86d6-aa90b3cbae01 ResourceVersion:10884495 Generation:1 CreationTimestamp:2018-09-20 05:25:16 +0000 UTC DeletionTimestamp:<nil> DeletionGracePeriodSeconds:<nil> Labels:map[] Annotations:map[] OwnerReferences:[] Initializers:nil Finalizers:[] ClusterName:} Attachments:[{Node:k8s-3-new PodNamespace:default PodName:toned-waterbuffalo-redis-master-0 ClusterName:rook-ceph MountDir:/var/lib/kubelet/pods/8cb71bfa-bc95-11e8-86d6-aa90b3cbae01/volumes/ceph.rook.io~rook-ceph-system/pvc-8cb3ff34-bc95-11e8-86d6-aa90b3cbae01 ReadOnly:false}]}]
2018-09-27 06:17:36.700940 E | op-cluster: failed to remove finalizer cluster.ceph.rook.io from cluster rook-ceph. Operation cannot be fulfilled on clusters.ceph.rook.io "rook-ceph": the object has been modified; please apply your changes to the latest version and try again
这个目录确实存在,但是 Redis 已经不在了。可能是我上次强制删除时留下的痕迹。这个 operator 有记录每次创建的 pv?但是不是只有 Cluster 这个 resource 么?
[centos@k8s-1 ceph]$ kubectl get volumes.rook.io --all-namespaces
NAMESPACE NAME AGE
rook-ceph-system pvc-8cb3ff34-bc95-11e8-86d6-aa90b3cbae01 7d
果然还有另外一个 CRD。上面目录可以直接删除,然后删除 volume crd。删除 cluster.ceph.rook.io 依然有错误:
op-cluster: failed to remove finalizer cluster.ceph.rook.io from cluster rook-ceph. Operation cannot be fulfilled on clusters.ceph.rook.io "rook-ceph": the object has been modified; please apply your changes to the latest version and try again
一般存储是单独部署的,有自己的控制网络和数据网络。这种让 Ceph 运行在计算集群内的方式是否稳定呢?生产环境如何处理?查了下,可以用 nodeSelector 让 pod 运行在特定的节点上,但是没有找到方法让节点只运行 Ceph 相关 pod 而进行隔离。使用 admission controller 准入控制器 PodNodeSelector 可以定制控制。还是算了,即便约束了我猜这种混合部署的方式稳定性也没提高多少。单独的部署一个新的集群?那计算集群里面的 StorageClass 就得使用标准的 Ceph brd 连接(配置一堆 monitor)?
rook-ceph namespace 已经暴露出了 rook-ceph-mon-[a,b,c] 三个 service,ClusterIP。这个网络是 weave 网络,不知道性能如何。有个配置 hostNetwork,uses network of the hosts instead of using the SDN below the containers. https://github.com/rook/rook/issues/561 hostnetwork support
考虑到容器网络的复杂和各种 policy 控制,Ceph 这种大数据量的似乎不适合容器化,适合的地方在于监控和恢复。 如果应用和 Ceph 在同一集群,则网络问题似乎并不大。
其他存储
这个 Rook 现在已经支持很多存储:Ceph, CockroachDB, Minio, Cassandra, EdgeFS
这个如果支持 Gluster 似乎是很好的,既然都有对磁盘有支持。 暂时不支持,说是 heketi 的存储模型只能让一个进程打开。 虽然 Gluster 已经够简单,但是我看了下其 Samba 方案挺复杂,真不想配置,我只是想试试而已,自己配置肯定有很多坑。在深入了解一个东西前并准备真正去用前,为什么要趟这些坑呢?而且这些坑会让人知难而退。而这些也是开源虽然火热也有其痛点,云服务厂商的 PaaS 的开箱即用优势便在这里。如果说 IaaS 只是方便了运维,PaaS 面向的则是开发者。
EdgeFS https://rook.io/docs/rook/v0.9/edgefs-storage.html http://edgefs.io/ https://itnext.io/edgefs-cluster-with-rook-in-google-cloud-885227625b9b Geo-transparent,我理解是多云环境的不同的数据中心的 db 合起来为一个统一的 db。这不和 CockroachDB 一样了么。
从最早对 Rook 的怀疑,到现在 Rook 的蓬勃发展,真是有趣的事情。 https://github.com/rook/rook/releases 看看每个 release 的 feature 也是一件有趣的事情。
单独升级ceph, What version of Ceph would you like with that?,Decoupling the Ceph version