Install OpenStack by Kolla Ansible and Get LoadBalancer IP
安装
指导文档:https://docs.openstack.org/kolla-ansible/latest/user/quickstart.html
CentOS 7.3 多节点Kolla安装 http://www.chenshake.com/kolla-centos-over-more-than-7-3-node-installation/
- fatal: [localhost]: FAILED! => {“changed”: false, “failed”: true, “msg”: “Unknown error message: Tag 4.0.1 not found in repository docker.io/kolla/ubuntu-binary-kolla-toolbox”}. → 修改里面的openstack-version,从auto改为4.0.0。这是因为4.0.1没有push到docker hubs上面?
- deploy后,打开dashboard可以,但是static file都返回404。→ cleanup-containers & cleanup-host in /usr/local/share/kolla-ansible/tools. 这是清空重新部署的常用命令。
fatal: [localhost]: FAILED! => {"failed": true, "msg": "The conditional check ''' not in ''' failed. The error was: Invalid conditional detected: EOL while scanning string literal (<unknown>, line 1)\n\nThe error appears to have been in '/usr/local/share/kolla-ansible/ansible/roles/rabbitmq/tasks/precheck.yml': line 54, column 3, but may\nbe elsewhere in the file depending on the exact syntax problem.\n\nThe offending line appears to be:\n\n\n- fail: msg=\"Hostname has to resolve to IP address of api_interface\"\n ^ here\n"}→ 我看安装程序已经设置hostname的ip为api_interface的ip。- Docker will not be able to stop the nova_libvirt container with those running. → 自己create的nova instance默认是用libvirt(因为我的host机器不是vm),shutdown后就可以运行cleanup-containers了。
- Cannot uninstall ‘PyYAML’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. → pip install pip==8.1.2
- /usr/share/kolla-ansible/init-runonce 文件里面 EXT_NET_CIDR这个是设置浮动IP的范围,必须设置好,这样运行 init-runonce 后,绑定 floating ip可以直接assign外网ip了,否则又得重新部署。http://www.chenshake.com/kolla-installation/ 这个里面有谈到。里面说 这个其实是从 neutron_external_interface 网卡访问的,如何确认?因为在 OpenWrt 是看不到的。
arp -an里面返回对应 IP 地址是 fa:16:3e:62:fb:ed,私营 mac,看了下也不是 vm nic mac,ui 里面看了下,是 network:router_gateway public1 的 Mac 地址。 这次忘了设置,修改再次运行时,报错 This tool should only be run once per deployment. 不想重新运行,按照这里 在界面上创建网络。But notebook can’t ping floating ip & vm can’t ping 192.168.51.1.yum install openswitchthen run ovs-vsctl show, otherwise command not found. No idea. Re-deploy. tools/cleanup-containers & tools/cleanup-host as https://docs.openstack.org/kolla-ansible/latest/user/operating-kolla.html. cmd is in /usr/share/kolla-ansible/tools.
VM ssh 免密码登录必须要在 root 用户下才能进,密钥在root用户下?是的,安装用的是 root 账户。 部署好后,默认的就可以访问 horizon,在 network_interface 上面,admin password is in /etc/kolla/passwords.yml:keystone_admin_password.
安装好后,很多服务比如 swift 没有安装。这个我得自己弄么?Just edit /etc/kolla/globals.yml and enable serivce like cinder. Then kolla-ansible deploy -i all-in-one again. Then OK. 今天又重新装了遍,安装好后,发现horizon没有装(现在默认不装了?),修改global.yaml,enable后重新deploy,居然也没有错,然后可以访问horizon。 可以额外添加的服务,注释里面的值就是默认值。比如默认打开了 horizon, heat。但是我看没有 heat 这个命令,仿照 openstackclient 安装方法 pip install python-heatclient,但是运行时报警:WARNING (shell) “heat stack-list” is deprecated, please use “openstack stack list” instead。
init-runonce 会创建很多初始化的资源,比如网络路由、cirros 磁盘镜像、虚机类型,但是只能运行一次。
Magnum
既然已经有了:enable_horizon_magnum & enable_magnum,启用,然后kolla-ansible deploy,是很方便,就是似乎每次添加一个组件都挺耗时。
刷新后界面上已经有了新的菜单项 Container Infra,但是访问会出错误消息:Error: Unable to retrieve the cluster templates. Error: Unable to retrieve the stats.
客户端用命令行安装 pip install -U python-magnumclient,这个是想当然猜出来的(现在已经用 openstack coe 来代替 magnum 命令了。)。magnum cluster-list 报错:
ERROR: 'NoneType' object has no attribute 'replace' (HTTP 500) (Request-ID: req-6c01fbcf-f883-41e3-a7f9-cecf92c7cf34)
这里同样问题,说是 GitHub 已经 fix 了。但是我看 /etc/kolla/magnum-conductor 下面还是用的 www_authenticate_uri,什么情况。直接跑到 /usr/share/kolla-ansible/ansible/roles/magnum/templates 下修改 magnum.conf.j2,将 www_authenticate_uri 改为 auth_uri,原来上面的 /etc/kolla 都是根据这个来产生的。这个是已知 bug。
重新 deploy 后可以看到/etc/kolla 下面被修改了,但是 docker ps 显示对应镜像还是 半小时前的,所以错误还是一样,如何重新生成呢?清空重新部署。现在magnum ui & cli 都可以运行不出错。这个重新部署很要命,有时可以,有时要清空然后重新部署,有地方说重启全部容器就可以。
然后在界面创建 cluster template,这比命令行方便。但是出现错误(错误都只在 http response 里面才能看到):Cluster type (vm, None, kubernetes) not supported (HTTP 400)
这个错误在命令行下可以看到,所以 UI 做的不行还不如命令行。这种 hello world 一定要能测试通过,否则就失去了 UI 快速上手的意义。
上面错误在这里解释很清楚,原因在于我的 os image 必须带一个属性 os_distro 标明其 linux 发行名,属性可以在 ui 里面的 image meta 加(rocky 只能命令行,UI 会报错)。现在只支持 fedora-atomic, coreos,看来 magnum 知道 k8s 搭建对操作系统很敏感。
openstack image set --property os_distro=fedora-atomic foo
集群创建中一直报错:
Service cinder is not available for resource type Magnum::Optional::Cinder::Volume, reason: cinder volumev3 endpoint is not in service catalog.
这个 Cinder 是必须的么?开启 enable_cinder,重新 deploy,这个不需要任何 backend?先这样再说。 创建集群还是出错,这次用 cli 查看,因为 ui 又连不上。
magnum cluster-show fantest
Resource CREATE failed: resources[0]: resources.kube_masters.Property error: resources.docker_volume.properties.volume_type: Error validating value '': The VolumeType () could not be found.
修改模板 magnum cluster-template-update fedora add volume_driver=cinder,还是一样。我在界面创建卷的时候也看到 No Volume type。openstack volume type list 也为空。
好吧,enable_ceph,重新 deploy,没看到啥变化,只是多了两个 ceph 容器。手工创建一个 volume type,然后创建一个该 type 的 volume,失败。看来部署 Cehp 没有那么简单。
按照下面步骤配置好 Ceph 后,回到这里。现在可以在界面成功创建一个 volume,但是创建 k8s 集群时依然同样错误。这里说缺少一个default_docker_volume_type 字段,docker exec -it magnum_conductor 进去后直接修改,然后 restart container,后来发现 restart 后值丢失,原来要修改 /etc/kolla/magnum-* 下面的对应文件,我猜容器是用 mount /etc 目录的方式来访问配置,这种操作如果放在 k8s 下面做就简单方便很多。这个值原始定义在 /usr/share/kolla-ansible/ansible/roles/magnum/defaults/main.yml 中。这个 volume type 没有绑定特定的 volume backend,可能被当做为默认类型。
现在开始漫长的创建 k8s 集群了。然后特么居然就可以了,一个 master,两个 minion,没有出现任何错误。看来已经颇为稳定了。
尝试创建一个带 load balance 功能的 k8s 集群,失败报错:
ERROR: ResourceTypeUnavailable: : resources.api_lb<file:///var/lib/kolla/venv/lib/python2.7/site-packages/magnum/drivers/common/templates/lb.yaml>: : HEAT-E99001 Service neutron is not available for resource type Magnum::Optional::Neutron::LBaaS::LoadBalancer, reason: Required extension lbaasv2 in neutron service is not available.
好吧,在 kolla 中打开 enable_neutron_lbaas,重新部署。这每次修改 /etc/kolla/globals.yml 都没有记录,到最后也不知道自己做了哪些修改。
这次重新部署 UI 还是出现浏览器 Angular JavaScript 错误:
Error: [$injector:nomod] Module 'horizon.app' is not available! You either misspelled the module name or forgot to load it. If registering a module ensure that you specify the dependencies as the second argument.
这个问题太常见,每次都在添加一个新的 horizon 模块/plugin之后发生,清空再重新部署好了。按理说 kolla/centos-source-horizon:queens 是 binary 的,不会重新构建啊。主 JS 为 http://192.168.51.147/static/dashboard/js/3bf910c7ae4c.js,记下看看这个是否会变。bash 到 horizon 容器中,发现几个 js 文件都是刚刚才产生出来的。暂时不知道办法,清除后重新部署,漫长等待后终于成功。
后来发现创建集群模板那里的 Master LB(–master-lb-enabled) 其实是多 master 的 load balance,和 k8s 里面的 Service LoadBalance 不同。进入 master 节点,查看 /etc/kubernetes 各个配置,都没有--cloud-provider=openstack。cloud_provider_enabled 这个默认不是为 true 么?但是似乎是 Rocky 才有的新功能。我在 magnum-conductor 容器里面查看 configure-kubernetes-master.sh 文件,里面没有考虑到新的标志位。
if [ -n "$TRUST_ID" ]; then
KUBE_API_ARGS="$KUBE_API_ARGS --cloud-config=/etc/kubernetes/kube_openstack__
config --cloud-provider=openstack"
fi
这个 shell 脚本其实是由 magnum 传给 heat,在 fedora atomic 上面运行。从 magnum 源代码看,这个 trust_id 贯穿整个流程,为空为什么在创建集群的时候就报错?troubleshooting 这里有讲到 Trustee for cluster 的问题,折腾几次,发现要修改 /etc/kolla/magnum-*/magnum.conf 里面的 cluster_user_trust 为 True。不知道这个为什么要默认设置为 false。为了固化配置,修改 /etc/kolla/globals.yml,加上 enable_cluster_user_trust: "yes"。
然后把集群里面已经装好的 dashboard service 改为 LoadBalancer 类型的,稍等片刻就能拿到 external IP 了。也试了下 Cinder StorageClass,简单的声明,没有 IP 配置之类,测试成功。有了 cloud provider 获取外部资源确实方便。
OpenStack 到此一游。
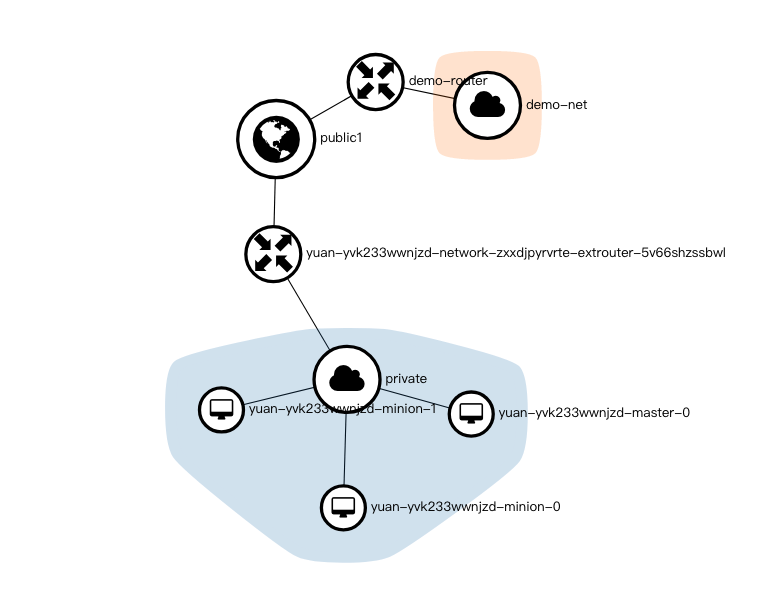
这个网络拓扑可以看到集群时由 1 个 master、2 个 minion 节点组成,属于 private 子网,然后通过一个 router 连接外网。private 子网的端口(Ports)除了 3 个节点,还有 DHCP,和 load balancer。
在 horizon 里面,外网或者内网网络是一个 IP 地址池(子网络),通过路由来连接两个网络,图中路由通过两个接口来连接两个网络。而浮动 ip 是外网子网里面的一个 ip,其和内网子网的某个 ip 做了绑定,这样就能通过浮动 ip 直接访问内网虚拟机。
queens 创建出来 k8s 默认版本是 1.9.3,rocky 的是 1.11.1,暂时没有找到配置 k8s 版本的地方。
k8s 集群删除失败的问题
一直在删除中,重启服务器后 DELETE_FAILED。进入容器查看 /var/log/kolla/magnum/magnum-condductor.log:
ERROR magnum.drivers.heat.driver [req-b693] Cluster error, stack status: DELETE_FAILED, stack_id: c8789bac-6957-48f1-8dd7-94124073c996, reason: Resource DELETE failed: Conflict: resources.network.resources.extrouter_inside: Router interface for subnet 50b433da-d225-413f-89b8-56d94acd7bb0 on router fd2120d9-4599-4a0a-acb0-c237d5bbc126 cannot be deleted, as it is required by one or more floating IPs.
查看 floating IP,只有一个 Dashboard load balance 的还没有删除。浮动 IP 手工释放,但是 load balance 挺难删除,相互依赖,摸索后发现最后删除次序为:pool's healthmonitor —> pool —> listener -> LB -> k8s network。
Magnum 是如何知道这个浮动 ip 资源是属于 k8s 集群(这里叫stack)的呢?并没有 db 保存这些数据啊?还是 heat 做的?为什么创建集群时创建的 etcd & api LB 都可以删除,dashboard 的却不能?资源都属于一个完整的 stack 范围,这个 stack 和 AWS 的是一样的。
openstack stack list
openstack stack resource list foo
全部都在这里,magnum 只是一个支持多集群的工具而已。更多命令看 heat 文档。创建好集群后,各资源为:
| resource_name | physical_resource_id | resource_type | resource_status | updated_time |
|---|---|---|---|---|
| etcd_lb | 0fe47743-fa07-488d-ad2a-4975b2f18825 | file:///usr/lib/python2.7/site-packages/magnum/drivers/common/templates/lb.yaml | CREATE_COMPLETE | 2018-12-10T03:38:08Z |
| kube_masters | 51ff11de-11f8-47c2-aa99-9c01a223e36f | OS::Heat::ResourceGroup | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| network | 0d8ebd19-fad5-4be6-bcf8-121a81a73f31 | file:///usr/lib/python2.7/site-packages/magnum/drivers/common/templates/network.yaml | CREATE_COMPLETE | 2018-12-10T03:38:08Z |
| api_lb | ce7a4d96-0f13-4fa2-8b5f-5f204aa5330f | file:///usr/lib/python2.7/site-packages/magnum/drivers/common/templates/lb.yaml | CREATE_COMPLETE | 2018-12-10T03:38:08Z |
| secgroup_kube_minion | 97c19df9-c9dc-4466-9c01-463aa3c19932 | OS::Neutron::SecurityGroup | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| nodes_server_group | 73e54288-535d-4564-b46c-ceb2adc18e7d | OS::Nova::ServerGroup | CREATE_COMPLETE | 2018-12-10T03:38:08Z |
| secgroup_kube_master | cf148deb-ffd2-474e-aecf-6f913f7f0802 | OS::Neutron::SecurityGroup | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| kube_minions | 8eb65593-bb46-40dc-b98a-90b07878035f | OS::Heat::ResourceGroup | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| api_address_floating_switch | 06644da0-8e50-4512-9e97-458263924be9 | Magnum::FloatingIPAddressSwitcher | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| api_address_lb_switch | a941f98d-a2fe-4077-a375-5fdde66982f8 | Magnum::ApiGatewaySwitcher | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
| etcd_address_lb_switch | f544d40b-6f4a-46be-a29d-6f63e35aac7f | Magnum::ApiGatewaySwitcher | CREATE_COMPLETE | 2018-12-10T03:38:07Z |
可以看到有 api 和 etcd 的 LB。手工设置 Dashboard Service Type 为 LoadBalancer 后,上面列表并没有改变,问题可能出现在这里,看上去只有纳入 heat 管理的资源才会被正确的删除。magnum 创建了 subnet,所有的 Ports (node & LB)都属于这个子网,删除这个网络必须先移除所有的 Ports,k8s 创建 LB (直接调用 OpenStack API)的 magnum 觉得不属于自己管理,所以就不会主动删除,这导致整个网络也无法删除。上面表格里面有个资源类型,比如 LB 的/usr/lib/python2.7/site-packages/magnum/drivers/common/templates/lb.yaml,可能 magnum(或者 heat)严格按照这个来进行创建和删除,这有点像 k8s。
删除上面集群,openstack stack resource list foo 变为:
| resource_name | physical_resource_id | resource_type | resource_status | updated_time |
|---|---|---|---|---|
| network | 0d8ebd19-fad5-4be6-bcf8-121a81a73f31 | file:///usr/lib/python2.7/site-packages/magnum/drivers/common/templates/network.yaml | DELETE_FAILED | 2018-12-10T03:38:08Z |
其他的都已经删除。heat event-list mystack 也可以查看删除失败原因,其实上面所有信息在 Horizon Orchestration 界面上看得更清楚,😄
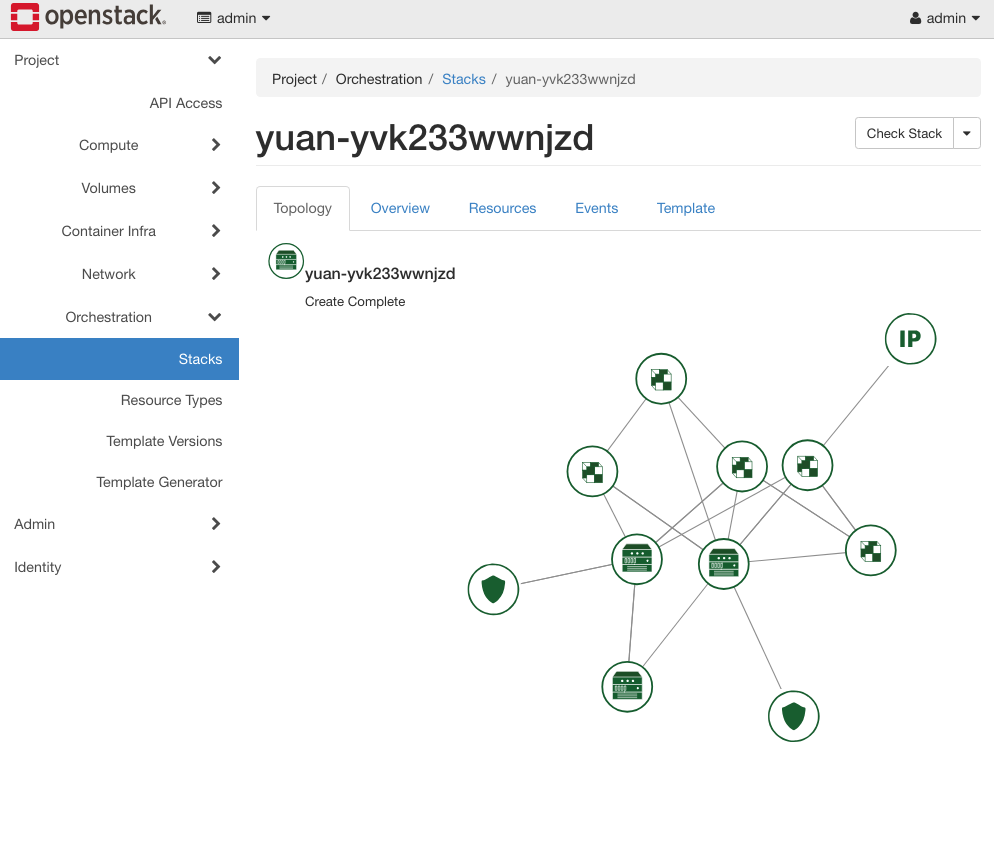
这个可视化编排工具和 AWS 的就非常像了,到底能起多大作用就不得而知了。
疑问:块设备(cinder)是属于哪个资源类型?也会存在同样问题。一种解决办法当 k8s 通过 cloud provider 在 OpenStack 中创建资源时,填入一个新的字段:k8s cluster id,删除时根据 id 找到 lb 和 volume,全部删除。具体查看 openstack_loadbalancer.go , openstack_volumes.go 和 magnum/api/controllers/v1/cluster.py delete 方法。更完美的方法应该是 Cloud Provider 调用 heat 来创建资源(失去了通用性),也就是对 stack 进行操作。不然为什么自动创建的 etcd & api LB 可以删除呢?但是 heat 是根据 template 来创建 stack,所以修改可能没那么容易。
所以这里就要看 heat 的设计理念了。heat 创建 stack 时候,需要传入 template-file 和 environment-file,后者其实就是 template 里面定义的各种参数(这种结构和 Helm 很类似)。template 描述了各种预定义资源,那么当 stack 运行起来后,其自生(应用内部)创建的资源是否属于 stack 管理范围呢?这是个很有意思的取舍。创建集群后,如果使用 magnum 动态扩容 - 添加一个新节点,这个节点在 heat 管理范围内么?AWS 是如何处理的?
k8s 由于采用声明式的方式来定义资源,所以删除的时候就很方便,直接kubectl delete -f files即可,helm 就是这样做的。当然,如果是用 operator/controller 程序创建的,也需要程序来删除了。
使用命令 magnum cluster-update foo replace node_count=3 添加一个节点后,openstack stack resource show foo kube_minions 可以在 links 属性下面看到有 3 个节点,horizon UI 也可以查看。我猜想删除集群时这个新的节点也可以被删除。
这里添加节点有个小问题:heat 已经显示 Update Complete,k8s 运行正常,但是 magnum 还是 UPDATE_IN_PROGRESS。
Ceph
感觉相关依赖没有做好,后面加 Ceph,前面创建好的 Cinder 容器没有重建,容器里面的配置都没有修改,这怎么能行呢?清除后重建集群。登录到后发现 cinder-api 下面还是没有 /etc/ceph/ceph.conf 文件,cinder-volume 有,ceph status 无法登录。ceph-mgr 容器运行 ceph osd pool ls 返回四个已经创建好的 pool:images, volumes, backups, vms。ceph -s 返回 0 kB used, 0 kB / 0 kB avail。日。
这里有详细配置,原来这个需要给硬盘加标签,然后 kolla 才会把这个硬盘分配给 Ceph。我只运行:
parted /dev/sdb -s -- mklabel gpt mkpart KOLLA_CEPH_OSD_BOOTSTRAP 1 -1
还是不行,cinder service-list 显示 cinder-volume ms1@rbd-1 是 down 的状态。但是我看 kolla/centos-source-cinder-volume:rocky 这个容器已经起来。现在问题是几种方法都没有在 docker ps 中看到 ceph-osd/ceph-rbd 容器。再次细看文档:all-in-one 情况下,需要设置 osd pool default size = 1,但是没有 /etc/kolla/config/ceph.conf 这个文件,修改 /usr/share/kolla-ansible/ansible/roles/ceph/templates/ceph.conf.j2,重新 deploy 后已经能看到 /etc/kolla/ceph-osd/ceph.conf 里面有我加的配置。但是还是不行,容量还是为 0 ,/dev/sdb 根本没有考虑进去。
换成 Queens 版本,因为这个没有 Bluestore,也不知道是不是这个原因。再不行得看 ansible 代码了。
这里创建 rbd 都是直接命令行,没有放到配置里面。
不行,/usr/share/kolla-ansible/ansible/roles/ceph/tasks/start_osds.yml 创建 osd 的脚本,但是如何知道运行结果呢?kolla-ansible 运行只输出到屏幕,没有地方看全部日志,可能我没找到。启用 verbose,使用命令
kolla-ansible ... -v | tee log
果然发现:
TASK [ceph : Looking up disks to bootstrap for Ceph OSDs] *********
ok: [localhost] => {"changed": false, "cmd": ["docker", "exec", "-t", "kolla_toolbox", "sudo", "-E", "ansible", "localhost", "-m", "find_disks", "-a", "partition_name=KOLLA_CEPH_OSD_BOOTSTRAP_BS match_mode='prefix' use_udev=True"], "delta": "0:00:01.454122", "end": "2018-11-27 21:46:51.368490", "failed_when_result": false, "rc": 0, "start": "2018-11-27 21:46:49.914368", "stderr": "", "stderr_lines": [], "stdout": "localhost | SUCCESS => {\r\n \"changed\": false, \r\n \"disks\": \"[]\"\r\n}", "stdout_lines": ["localhost | SUCCESS => {", " \"changed\": false, ", " \"disks\": \"[]\"", "}"]}
返回空数组,这是没有找到合适的磁盘了?KOLLA_CEPH_OSD_BOOTSTRAP_BS 为什么是这个?这个是 bluestore,应该是 KOLLA_CEPH_OSD_BOOTSTRAP。这个分区名字是在 /usr/share/kolla-ansible/ansible/roles/ceph/defaults/main.yml 中决定的,接着由 ceph_osd_store_type 决定,在 /usr/share/kolla-ansible/ansible/group_vars/all.yml 这个默认是 bluestore。好的,我在 /etc/kolla/globals.yml 加上 ceph_osd_store_type: “filestore”。重新发布,现在会停在出错的地方,错误很隐晦,手工在 kolla-toolbox container 里面运行:
ansible localhost -m find_disks -a "partition_name=KOLLA_CEPH_OSD_BOOTSTRAP match_mode='prefix' use_udev=True”
重现错误:
localhost | FAILED! => {
"changed": false,
"failed": true,
"msg": "UnicodeDecodeError('ascii', '\\xe6\\x96\\xb0\\xe5\\x8a\\xa0\\xe5\\x8d\\xb7', 0, 1, 'ordinal not in range(128)')"
}
有对应磁盘反而报错,似乎是字符集的问题,问题是这个看不懂。下载源码 find_disk.py,稍作修改,本地运行,发现磁盘有个 LABEL 新加卷,导致出错。parted /dev/sdb 这个命令默认就会产生这个 label。折腾各种命令来修改 label,最后发现这个『新加卷』是原来的 Windows 磁盘,用的 parted 命令并不会删除旧有分区。mkfs.ext4 格式化之 或者使用 parted 交互式方式删除分区。
另外一个问题:
TASK [ceph : Bootstrapping Ceph OSDs] failed: [localhost] (item=[0, {u'fs_uuid': u'', u'journal_device': u'/dev/sdb', u'journal': u'/dev/sdb2', u'partition': u'/dev/sdb1', u'partition_num': u'1', u'journal_num': 2, u'fs_label': u'', u'device': u'/dev/sdb', u'partition_label': u'KOLLA_CEPH_OSD_BOOTSTRAP', u'external_journal': False}]) => {"changed": true, "item": [0, {"device": "/dev/sdb", "external_journal": false, "fs_label": "", "fs_uuid": "", "journal": "/dev/sdb2", "journal_device": "/dev/sdb", "journal_num": 2, "partition": "/dev/sdb1", "partition_label": "KOLLA_CEPH_OSD_BOOTSTRAP", "partition_num": "1"}], "msg": "Container exited with non-zero return code 1"}
这个 bootstrap 容器运行后退出,docker ps --all才能看到。docker logs bootstrap_osd_0 日志里面有:
GPT data structures destroyed! You may now partition the disk using fdisk orother utilities.
Warning: The kernel is still using the old partition table.The new table will be used at the next reboot.
mkfs.xfs: cannot open /dev/sdb1: Device or resource busy
所以每次清空部署后,最好重启服务器。
现在 OK 了!检查最后成功状态:
[root@ms1 fan]# lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 238.5G 0 disk
├─sdb1 8:17 0 233.5G 0 part /var/lib/ceph/osd/6fce7aad-0b42-4a0e-bdca-8bb7c9ed7135
└─sdb2 8:18 0 5G 0 part
sdb1 下面都是散放的文件,这个就是 filestore 的意思?现在可以看到有个 kolla/centos-source-ceph-osd:queens 容器在运行。
安装好后,磁盘 label KOLLA_CEPH_OSD_BOOTSTRAP 会被去掉,所以每次清空再次部署时需要自己加上。
Kolla集成外接ceph存储 集成到我原来创建好的 Rook Ceph 上去?滑稽。
启用 Ceph 后,kolla 也会安装 Ceph Dashboard,也就是 ceph-mgr docker image,一个 web 的监控 UI。容器映射端口是多少呢?奇怪的是用 docker port 返回空,netstat -tlnp 才找到端口为 7000。RabbitMQ 也找不到 web ui 端口,不过看来容器化后端口号没变,还是 15672,用户名 openstack。
默认 OpenStack 会创建的 ceph pool 有 images, volumes, backups, vms。images 保持 glance 里面的 Linux Cloud Image,和 glance image-list 返回一样,raw 或者 qcow2 格式。vms 放 vm 节点的启动磁盘(这个不知道如何用命令查看)。volumes 则是 vm 节点的扩展磁盘,和 openstack volume list 返回一样。
Log
Central Logging 原来已经有这个东西。kolla ansible 的部署日志没法记录吧,那时候日志服务还没好。
Kibana 没法起来:/usr/local/bin/kolla_start: line 18: /usr/share/kibana/bin/kibana: No such file or directory 这什么鬼,好吧,binary 镜像没法自己改吧。自己下载 Kibana 本地运行个,毕竟只是个 UI 端,还好 Elasticsearch 能工作。修改配置让其后端连接 kolla 创建好的 Elasticsearch。启动出现错误:Status changed from yellow to red - This version of Kibana requires Elasticsearch v6.5.1 on all nodes. I found the following incompatible nodes in your cluster: v2.4.6 @ 192.168.51.147:9200 (192.168.51.147) 版本不兼容啊,查看其兼容性 matrix, 下载对应 4.6.4 版本。
现在 Kibana 里面是可以看到一堆 log 了,但是对于 magnum,只有 magnum-api,没有 magnum-conductor。后来发现要在 magum.conf 里面设置 debug=True。
虚拟机一直是 scheduling 状态
这里有调试方法,用docker exec -it 进入 shell,cat /var/log/kolla/nova/nova-scheduler.log,
AMQP server on 192.168.51.247:5672 is unreachable: [Errno 111] ECONNREFUSED. Trying again in 6 seconds. Client port: None: error: [Errno 111] ECONNREFUSED
界面显示服务 nova-scheduler down 状态。nova service-list 也显示为 down。 同样问题 docker ps 返回里面有 kolla/centos-binary-rabbitmq:queens 这个 docker 运作中,shell 进去,rabbitmqctl status,lsof -i :5672 看到已经有很多连接了。不对,上面unreachable日志是昨天的。docker ps -a 返回所有 docker,发现 kolla/centos-binary-nova-scheduler:queens 已经退出了。
b63907bcea6e kolla/centos-binary-nova-scheduler:queens "kolla_start" 16 hours ago Exited (0) 13 hours ago nova_scheduler
为什么是 13 小时前,几天上午我开机的时候没有尝试重启这个 docker?我自己运行 docker start nova_scheduler (不能 start id),可以起来,然后就一切好了。(我有尝试关掉防火墙和 selinux,应该没有关系),有的说这个和 NTP 和启动依赖有关系,这个依赖 mq。
Docker ps 有返回 kolla/centos-binary-horizon:queens,这里才知道安装的是 queens 版本。命令行用 —version 返回的都是数字。
ps aux 里面有返回 qemu-kvm 进程,为什么公司机器的就没有呢?难到是因为我用的 qcow2 格式,可以该换 raw 格式,可能性不大。
还有虚机运行的磁盘文件是直接放在宿主机上面:-drive file=/var/lib/nova/instances/78687529-9333-429f-a184-9a13c725fcca/disk,format=qcow2,如果使用了 ceph,会放到 ceph 上面?
部署到 Neutron 时候控制台挂起
一次成功部署后,重启机器,主端口连接不上。清空重新部署,运行到 Running Neutron bootstrap container,控制台 ssh 网络断开,TTY console 登录查看最后日志为:
TASK [neutron : Running Neutron bootstrap container] ******************************************************************************************************
changed: [localhost -> localhost] => {"changed": true, "result": false}
TASK [neutron : Running Neutron lbaas bootstrap container] ************************************************************************************************
fatal: [localhost -> localhost]: FAILED! => {"changed": true, "msg": "'Traceback (most recent call last):\\n File \"/tmp/ansible_kolla_docker_payload_e0UJ1B/__main__.py\", line 874, in main\\n result = bool(getattr(dw, module.params.get(\\'action\\'))())\\n File \"/tmp/ansible_kolla_docker_payload_e0UJ1B/__main__.py\", line 666, in start_container\\n self.pull_image()\\n File \"/tmp/ansible_kolla_docker_payload_e0UJ1B/__main__.py\", line 507, in pull_image\\n repository=image, tag=tag, stream=True\\n File \"/usr/lib/python2.7/site-packages/docker/api/image.py\", line 400, in pull\\n self._raise_for_status(response)\\n File \"/usr/lib/python2.7/site-packages/docker/api/client.py\", line 248, in _raise_for_status\\n raise create_api_error_from_http_exception(e)\\n File \"/usr/lib/python2.7/site-packages/docker/errors.py\", line 31, in create_api_error_from_http_exception\\n raise cls(e, response=response, explanation=explanation)\\nAPIError: 500 Server Error: Internal Server Error (\"Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)\")\\n'"}
NO MORE HOSTS LEFT ****************************************************************************************************************************************
to retry, use: --limit @/usr/share/kolla-ansible/ansible/site.retry
PLAY RECAP ************************************************************************************************************************************************
localhost : ok=311 changed=175 unreachable=0 failed=1
禁用掉 lbaas 也没用。因为是在部署 neutron,所以应该是网络配置出现问题导致后面没法拉镜像。尴尬。为什么不先下载所有镜像然后开始部署?干净 centos 部署没有问题,几次之后就会出现这个问题。有 iptables 之类的残留?这里和这里都有讨论这个问题,似乎 kolla 会创建一个 br-ex 网桥来做外部通信。后来尝试在宿主机中禁用 neutron_external_interface,也就是关掉 DHCP 获取 IP,问题消失,😂
每次清除集群后最好重启下服务器,因为有些 network interface like qbr, qvo, qvb 没有清理干净。
Rocky 创建 k8s 集群失败
CREATE aborted (Task create from SoftwareDeployment "enable_cert_manager_api_deployment" Stack "cai-7fzsht5k5dzv-kube_masters-zmbdkz4oxa5s-0-4zytyo6ftz4h" [3bb2ae99-ee48-41e7-b4d7-a38c93a2da41] Timed out)
在 master 节点上面运行 journalctl | grep runc,
novalocal runc[2745]: E1211 03:57:42.946464 1 reflector.go:205] k8s.io/kubernetes/cmd/kube-scheduler/app/server.go:176: Failed to list *v1.Pod: Get http://127.0.0.1:8080/api/v1/pods?fieldSelector=status.phase%21%3DFailed%2Cstatus.phase%21%3DSucceeded&limit=500&resourceVersion=0: dial tcp 127.0.0.1:8080: connect: connection refused
novalocal runc[2849]: W1211 03:57:43.388424 1 proxier.go:469] Failed to load kernel module ip_vs with modprobe. You can ignore this message when kube-proxy is running inside container without mounting /lib/modules
novalocal runc[2468]: Source [heat] Unavailable.
novalocal runc[2406]: /var/lib/os-collect-config/local-data not found. Skipping
novalocal runc[2468]: publicURL endpoint for orchestration service in null region not found
如此之多错误?运行 runc list 可以看到 atomic 上面 heat 是作为一个容器运行在 master node 上面,查看 log 用 journalctl --no-pager -u heat-container-agent。对于 publicURL endpoint for orchestration service in null region not found 的问题,这里有解释,我本地试了下,openstack endpoint list 包含 heat,Service Type:orchestration,openstack service list 里面也包含 heat,难道是因为 RegionOne 没有传给 heat agent?(/etc/kolla/magnum-conductor/magnum.conf 里面已经定义了 RegionOne)可能因为 heat 依赖 keystone 来找到所有的注册信息。在 master node 上面 cat /var/run/heat-config/heat-config,返回为 [],空数组,正常是一大堆 JSON。从 null regin 看,多半还是配置问题。费劲转为开发模式后还是一样问题😂
Heat 创建一个虚拟机,参数如何传递?cloud-init 还是 ssh?
heat-container-agent 容器会向 heat 报告信息。具体看 https://github.com/openstack/magnum/blob/master/magnum/drivers/k8s_fedora_atomic_v1/templates/kubemaster.yaml,里面有 start_container_agent。注意里面的 write_heat_params,传入大量参数,写入到 /etc/sysconfig/heat-params,里面包含 REGION_NAME="RegionOne",按我理解 heat 拿到 keystone 地址后调用 api,找到 orchestration service 地址,现在看来数据都在。heat-config 是如何产生出来的呢?
heat-engine log,里面可以看到一个个 task 的运行日志:
Task create from ResourceGroup "kube_masters" Stack "tong-wvfftolmtniv" [3d0dae3d-5cce-4e47-976b-400633f92d94] timed out
Task create from SoftwareDeployment "enable_cert_manager_api_deployment" Stack "tong-wvfftolmtniv-kube_masters-4pu45beuteve-0-vsoxums4xz6k" [9f7f80df-9fbd-4624-a029-55b58391dc50] timed out
后面一个 task 属于前面一个。 https://github.com/openstack/magnum/blob/master/magnum/drivers/common/image/heat-container-agent/scripts/heat-config-notify 里面有获取 orchestration endpoint 的代码:
ks = ksclient.Client(
auth_url=iv['deploy_auth_url'],
user_id=iv['deploy_user_id'],
password=iv['deploy_password'],
project_id=iv['deploy_project_id'])
endpoint = ks.service_catalog.url_for(
service_type='messaging', endpoint_type='publicURL',
region_name=iv.get('deploy_region_name'))
这个方法由 55-heat-config 调用,输入为两个文件,上面的大量参数比如 deploy_auth_url 都由 heat-config 传递,其格式为:
[
{
"inputs": [
{
"type": "String",
"name": "deploy_server_id",
"value": "3fb12f6a-cc17-4478-8a2f-ce4cca0bfb8b",
"description": "ID of the server being deployed to"
}
],
"group": "script",
"name": "kong-ob42euoeumne-kube_masters-hfnvgsn727tt-0-k8s_keystone_service-nzkdrrgtemm5",
"outputs": [],
"creation_time": "2018-12-10T08:11:27",
"options": {},
"config": "#!/bin/sh\n\n. /etc/sysconfig/heat-params\nexport PATH=$PATH:/var...."
}
]
master node 上面的 heat agent 容器收到这个请求后执行任务。不是,agent 只是回报 heat 部署进展。因为即使部署失败,我看到 enable_services 还是被触发了。
根据这里的提示,查看 /etc/os-collect-config.conf,果然发现其中 region_name = null,老版本没有这个值。这个文件是如何产生的呢?这个是 nova 配置主机方式,template 定义 在 write-os-apply-config-templates.sh,数据在 /var/lib/os-collect-config/os_config_files.json,其包含 /var/lib/os-collect-config/heat_local.json,里面 region_name: null,其他都有。这里看,这个为 heat local metadata,应该是 heat 创建 vm 时传入。os-collect-config heat_local.py 负责写入 heat_local,数据从 /var/lib/heat-cfntools/cfn-init-data,里面数据等同于 /var/lib/cloud/data/cfn-init-data。Heat Walk-through 里面会做这一步,如此看来,这是 heat bug?因为都是自动化部署出来的,没办法来个途中硬编码确认。
region_name 是 stack 运行的一个参数,dashboard 显示这个值已经传入。
打开 debug 后会输出更多内容,如何打开?
write-os-apply-config-templates.sh 这文件会写入 /var/run/heat-config/heat-config,
echo "" > $oac_templates/var/run/heat-config/heat-config
deployments 变量是容器的输入变量。
关于 heat, Heat metadata service is provided via the CFN API, its primary use is for heat-cfntools to talk to Heat via that API.
Heat Troubleshooting 描述了获取 user data 方法:
curl -s http://169.254.169.254/2009-04-04/user-data
试了下,果然可以(为什么是 2009-04-04 😂),这是 multipart 数据格式。这个是 vm 内置的 metadata server。最后两段为:
--===============2826715925626734437==
Content-Type: text/plain; charset="us-ascii"
MIME-Version: 1.0
...
systemctl enable wc-notify
systemctl start --no-block wc-notify
--===============2826715925626734437==
Content-Type: text/x-cfninitdata; charset="us-ascii"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Content-Disposition: attachment; filename="cfn-init-data"
{"os-collect-config": {"heat": {"password": "x#g*ilkG&E*rNp%9u3z#KQO89bC4FK0!", "user_id": "0a3afbf8af2246bf86c2a480afa766ff", "region_name": null, "stack_id": "tong-wvfftolmtniv-kube_masters-4pu45beuteve-0-vsoxums4xz6k/9f7f80df-9fbd-4624-a029-55b58391dc50", "resource_name": "kube-master", "auth_url": "http://192.168.51.253:5000/v3/", "project_id": "4d70c955bbef4a8a94dfa9c7370042cb"}, "collectors": ["ec2", "heat", "local"]}, "deployments": []}
可以看到里面 region_name 也为空。而这段对应 magnum/drivers/k8s_fedora_atomic_v1/templates/kubemaster.yaml
kube_master_init:
type: OS::Heat::MultipartMime
properties:
parts:
- config: {get_resource: install_openstack_ca}
- config: {get_resource: disable_selinux}
- config: {get_resource: write_heat_params}
- config: {get_resource: configure_etcd}
- config: {get_resource: write_kube_os_config}
- config: {get_resource: configure_docker_storage}
- config: {get_resource: configure_kubernetes}
- config: {get_resource: make_cert}
- config: {get_resource: add_proxy}
- config: {get_resource: start_container_agent}
- config: {get_resource: enable_services}
- config: {get_resource: write_flannel_config}
- config: {get_resource: flannel_config_service}
- config: {get_resource: flannel_service}
- config: {get_resource: kube_apiserver_to_kubelet_role}
- config: {get_resource: master_wc_notify}
可以看出 master_wc_notify 能找到定义,但是 cfn-init-data 没有,可能为 Heat 默认附上。
直接查看 Heat 源代码,nova.py build_userdata 方法会写这块 multipart:
if metadata:
attachments.append((jsonutils.dumps(metadata),
'cfn-init-data', 'x-cfninitdata'))
调用者 heat/heat/engine/resources/openstack/nova/server.py:
metadata = self.metadata_get(True) or {}
userdata = self.client_plugin().build_userdata(
metadata,
ud_content,
instance_user=None,
user_data_format=user_data_format)
metadata 数据会写入 userdata。metadata_get 定义在 heat/engine/resource.py(VS Code 安装扩展后可以方便的查看方法定义)
def metadata_get(self, refresh=False):
if refresh:
self._rsrc_metadata = None
if self.id is None or self.action == self.INIT:
return self.t.metadata()
if self._rsrc_metadata is not None:
return self._rsrc_metadata
rs = resource_objects.Resource.get_obj(self.stack.context, self.id,
refresh=True,
fields=('rsrc_metadata', ))
self._rsrc_metadata = rs.rsrc_metadata
return rs.rsrc_metadata
转为开发模式暨步骤总结
Check Kolla source code. It has branches like stable/rocky. It is very clear. But if you just pip install, you will get master version and can’t get the exact one by OpenStack version. As above shows, master use www_authenticate_uri which was wrong(valid in future). Rocky should use auth_uri. So we should use git branch rather than latest pip package.
- cd /etc/kolla,use old/tested global.yaml & passwords.yml. Just keep these 2 files and clear others.
git checkout stable/rocky- edit ./kolla-ansible/ansible/roles/magnum/defaults/main.yml, set
default_docker_volume_type: "ssdvolume" - edit ./kolla-ansible/ansible/roles/ceph/templates/ceph.conf.j2, set
osd pool default size = 1&osd pool default min size = 1since server has only one disk parted /dev/sdb -s -- mklabel gpt mkpart KOLLA_CEPH_OSD_BOOTSTRAP 1 -1; parted /dev/sdb print- deploy
./kolla-ansible/tools/kolla-ansible -i ./kolla-ansible/ansible/inventory/all-in-one deploy -v | tee log - edit kolla-ansible/tools/init-runonce(IP range) and run it
glance image-create --name atomic27 --visibility public --disk-format raw --container-format bare < Fedora-Atomic-27-1.6.x86_64.rawopenstack image set --property os_distro=fedora-atomic atomic27openstack volume type create "ssdvolume"
Think
- Ansible 是幂等的,也就是说反复部署不会对功能造成影响,这个是理想情况。
- Docker 对宿主机的网络和设备全面接管,和独立运行的程序没啥差别。用容器部署比直接程序更简便么?可能隔离性更好,不需要安装包,对宿主机操作系统影响不大,删除时更加方便。再则兼容性更好,安装过程最怕的是各种兼容性问题。另外:其配置(/etc/kolla/)和运行时(容器)是隔离开的,符合 12 法则应用理论。
- Docker 用的不错。那用了 Docker 还用 OpenStack VM 干啥呢?技术变化太快,总的来说:OpenStack plays the role of the overall data center management. KVM as the multi-tenant compute resource management, and Docker containers as the application deployment package. 容器另外一个问题是强隔离还不够好,vm 能弥补这个缺点。
- 直接用 Docker,出了错只能直接操作 Docker 调试,显然用 k8s 更好些(k8s也能提供高可用性),但牵涉到网络、存储这个问题就更复杂了。
- 漫长的部署居然没有写日志的地方,我只找到使用管道
tee的方法。 - kolla 部署了大量镜像,这些镜像有缓存么?
docker images ls没有看到任何镜像。 - Python 动态语言虽然开发便利,但如何保证类型安全,这里感觉 Go 更为合适,速度更快
- Heat 设计因为模仿了 AWS CloudFormation,和原来 OpenStack 并不十分吻合,很多地方有拼凑之感,颇为恶心
- Heat 编排大量依赖 cloud-init/userdata,隔着 vm 在 Linux 上面各种操作,颇有 hack 之感,k8s 则没有 vm 这个屏障,初始化过程看得清清楚楚。如果一个漫长的过程部署失败,出错的地方分布在不同平台和系统,调试起来心累。
总的来说
太复杂:功能重合、磨合不稳定、技术演变太快。。。云服务提供商有理由用这种混合模式,企业内部还是直接裸机部署 k8s 好了。或许 OpenStack 上面直接使用 Ansible + kubeadm 会简单些。这里使用 kubespray + Terraform 在 OpenStack 上面部署 k8s,我原来以为 kubespray 只是裸机部署的。