Kubernetes 日志、跟踪、监控和告警
对于一个分布式且微服务化的系统,这块价值是巨大的。不过一般开发人员都不大重视,各种配置,觉得麻烦。等到系统出了问题手忙脚乱的时候才希望有这么个系统,没有问题则万事大吉。
- 日志是有约定格式的文本文件,每行为一条记录,各字段用 tab 分开
- 监控数据则是特殊一种指标(metrics),比如 cpu 使用率,服务状态和调用次数,随着时间不断发生变化,是一种时间序列数据(time series data)
- 跟踪(trace, telemetry)则是程序代码的调用栈,包括开始/结束时间,请求和响应数据
这些是从不同切面和角度对系统进行分析,数据不同,展示和分析方式也不同。
EFK
EFK由ElasticSearch、Fluentd和Kiabana三个开源工具组成。其中Elasticsearch是一款分布式搜索引擎,能够用于日志的检索,Fluentd是一个实时开源的数据收集器,而Kibana 是一款能够为Elasticsearch 提供分析和可视化的 Web 平台。原来的组合是 ELK: Elasticsearch + Logstash + Kibana。Logstash Java 写的,而 Fluentd 要运行在每个节点上面,原来的不够轻量级,或者说不是 cloud native 的。大数据生态里面的 Flume 也是一款高性能、高可用日志收集系统。
试了几个helm chart,都不顺利。尝试这个,他是基于 kubernetes add-on 里面的代码,较为纯净。部署后会看到有个fluentd-es-v2.2.0 daemon set,但是下面没有任何pods,显示为 0/3。一般来说daemon set 会运行在每个node上面,这里是因为要给node 上面打tag 才会运行。
kubectl label nodes vm2 beta.kubernetes.io/fluentd-ds-ready=true
命令指南。然后马上会在vm2上创建新的pods,不用重启任何东西,他有watch node labels?但是有个错误:
Failed to pull image "k8s.gcr.io/fluentd-elasticsearch:v2.2.0": rpc error: code = Unknown desc = Error response from daemon: manifest for k8s.gcr.io/fluentd-elasticsearch:v2.2.0 not found
在这里浏览和搜索google 的仓库,发现只有 2.1.0版本的。看来这个add-on 确实被遗留的项目。
然后按照文档使用 kubectl proxy 访问。我发现使用 NodePort 不能访问,返回一个 json 错误。现在kibana可以运行,但是没有任何数据。我记得公司集群上面还有些logstach 数据的。按照文档运行 curl -XPUT 'http://elasticsearch-logging:9200/_cluster/settings' -d '{ "transient": { "cluster.routing.allocation.enable": "all" } }' -H 'Content-Type: application/json’。还是不行。 后来发现和这里(腾讯云)遇到问题一模一样,因为centos 的日志输出是journald的,而fluentd 默认是扫描 /var/log/containers 下的日志(今天我发现有的在 /var/lib/docker/containers/ 下面),所以没有任何数据,而在ubuntu下就可以。
$ vim /etc/sysconfig/docker
增加 OPTIONS='--log-driver=json-file --signature-verification=false'
$ systemctl daemon-reload
$ systemctl restart docker
这种方法其实就是这里说的最优的办法:”将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志收集Pod”。这种配置少,但是要求目录和日志格式都要先约定好,而且 log 要输出到 out,这样 Docker 才会截获这些日志。当然现在日志系统比如 log4j 都支持多个输出目的地(appender)。他这里使用Filebeat来代替Fluentd。Fluent-bit 可以读取更多的类型的日志“ * Read Kubernetes/Docker log files from the file system or through Systemd Journal”。
Add-on 里面默认es 存储是EmptyDir volume,pod 结束就会消失。es 是基于 JAVA,耗内存,容易导致节点 OOM。
只能读取非系统容器的 log,这些是安全的限制?如何读取系统内比如 kube-proxy 的 log?kubernetes/cluster/addons/fluentd-elasticsearch/fluentd-es-configmap.yaml 这个里面表面其能读取 kubelet 的日志。
今天尝试让 office k8s send log -> home k8s,在 office k8s 里面只运行 fluentd-es-configmap.yaml & fluentd-es-ds.yaml,当然更换了 elasticsearch host 地址。kibana 只能看到 weave-net Discovered remote MAC 的日志。查看 fluentd-es 日志,有 [elasticsearch] Could not push logs to Elasticsearch, resetting connection and trying again. read timeout reached。我看 ip 和端口都是对的啊,curl http://192.168.51.11:31954/_search?pretty 运行有返回值。
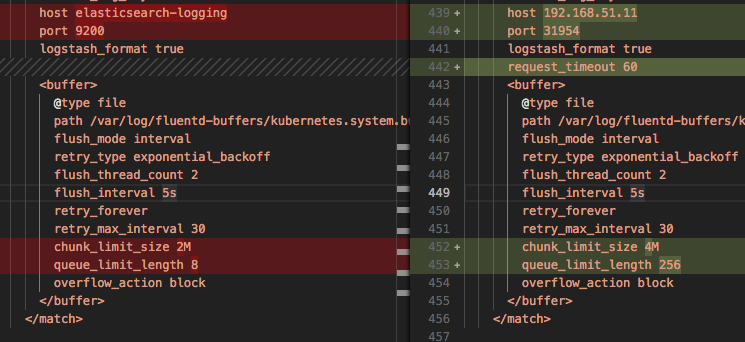
如上修改后,不能连接的错误消失了。现在可以看到些log了,但是还是会出现 ConnectionFailure error=”Could not push logs to Elasticsearch after 2 retries. read timeout reached” 错误。看来两个网络太远了以致 fluentd 不能及时的把日志流 push 到 es。放弃。今天换到 Ceph PVC 存储,还是老样问题,做上述修改后就能看到 log 了。这个是因为存储比 empty-dir 要慢的缘故?elasticsearch-logging 是一个 statefulset,重启对应的 pods 能保留原来的日志么?
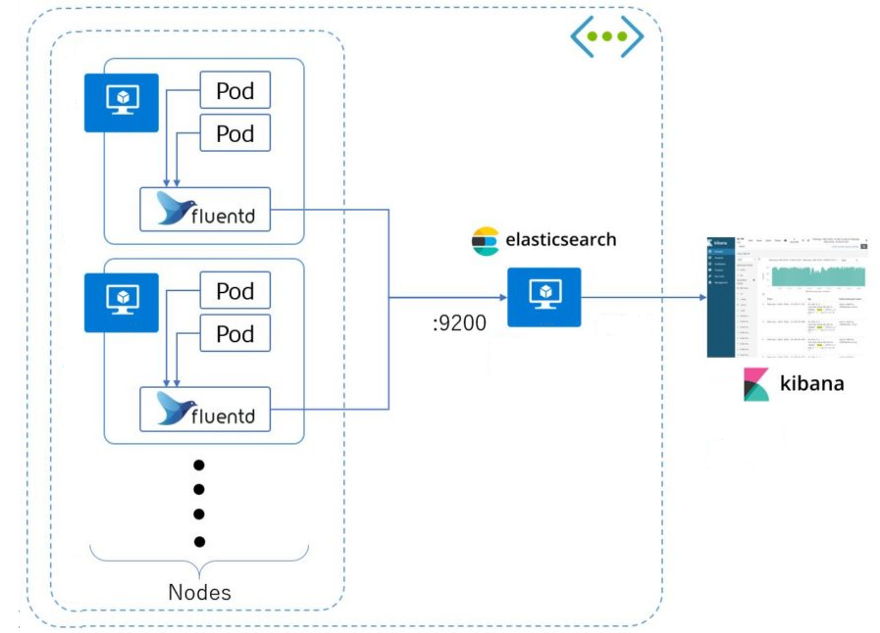
按照上图看,fluentd 不需要使用sidecar 的形式运行在每个pod里面,只需运行在每个节点上。
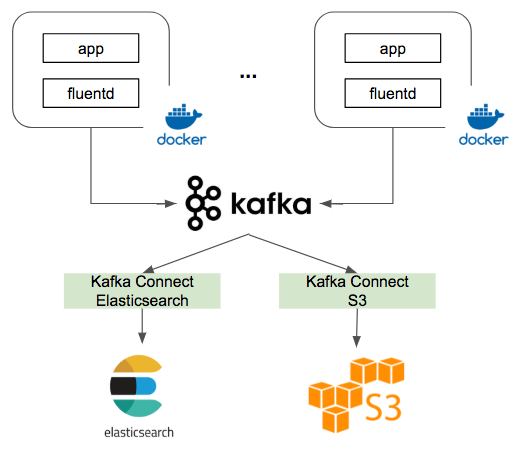
日志收集的场景经常少不了 Kafka,那么 EFK 怎么集成 Kafka 呢?只要在 Filebeat 和 ES 中加入 Kafka:Filebeat 通过 fluent-plugin-kafka 把日志方式到 Kafka 中,然后 Kafka 通过 kafka-connect-elasticsearch 这个 Connector 发送到 ES 中。这样通过水平扩展 Kafka、Elasticsearch 集群能提高系统的吞吐量。
Prometheus - 监控告警
和日志系统不同,监控系统实时监控系统运行状况,通过 metrics 和时间序列实时显示指标。
https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/ 比较和日志的区别,如果要存储日志,其 FAQ 推荐ELK stack。
对比了解Grafana与Kibana的关键差异 http://www.infoq.com/cn/articles/grafana-vs-kibana-the-key-differences-to-know
https://github.com/giantswarm/kubernetes-prometheus 这个一键安装 Prometheus,Grafana,Alertmanager。
Grafana 添加 Prometheus 数据源时,注意其 url 能否浏览器直接访问。
Altermanager 只是对收到的告警做发送工作,而发送会有分组、去重、禁言等各种需求。
Node exporter https://prometheus.io/docs/introduction/first_steps/#installing-the-node-exporter 这个做啥?
https://prometheus.io/docs/introduction/overview/
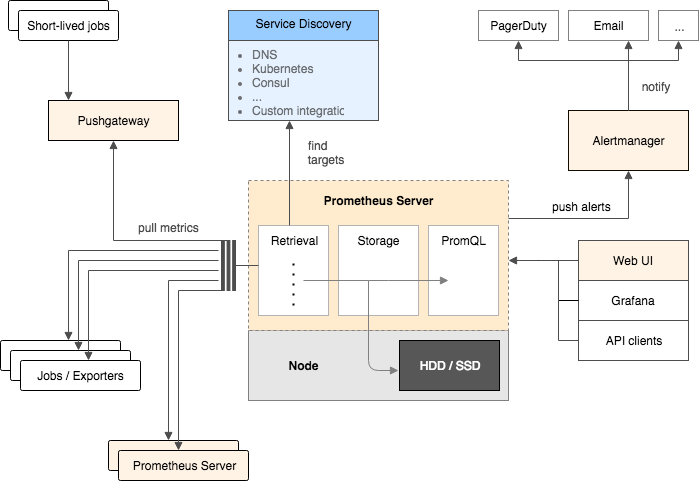
信息的收集速度要快,需要类似 kafka 的消息系统,对已有业务逻辑要影响小。
上面 template 会生成 prometheus-node-exporter 和 node-directory-size-metrics 这两个 Daemon Sets,这样每个节点都有,这两个搜刮器直接访问 cAdvisor?
数据的存储如果时间长了,是不是会很大?https://prometheus.io/docs/prometheus/1.8/storage/ 这个里面说用的是 LevelDB(只是做索引),但是最新的文档里面没有提及。不知道是否更换了。PromQL queries that involve a high number of time series will make heavy use of the LevelDB-backed indexes. 而生产环境就可以用各种时间序列数据库(TSDB, time series database)了,比如常用的 InfluxDB,能处理时间序、度量、事件,注意高可用方案是收费的。
我试的几个一键安装的都没有看到信息存在哪个 PV,只保存最近一天的 log?
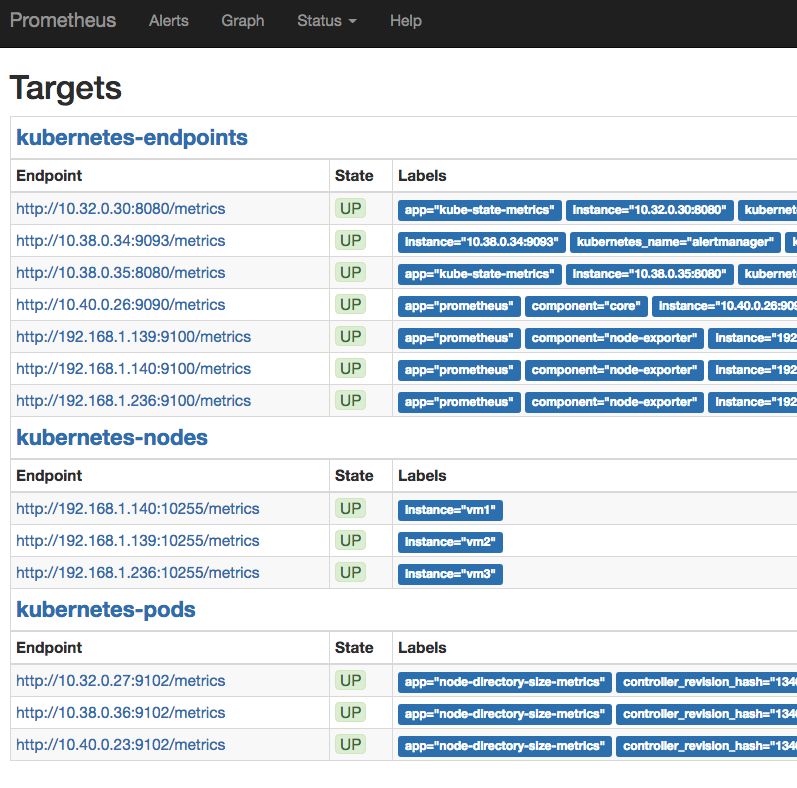
job 会定义任务来扫描 target,比如扫描 k8s 的节点这种 target endpoint。但是上面的架构图里面的 job 应该是数据录入啊,箭头反了么。所有的 alert 上面都有个 job 的 Label 来表明这个 alert 是由谁产生的。https://prometheus.io/docs/concepts/jobs_instances/ 一个 target 一般对应多个 instance,比如扫描(scrape 刮)多个节点的状况,而 job 就是这种类似功能的集合。
下面是 template 默认产生的 target,这个是内置 job 产生的?grafana-import-dashboards[giantswarm/tiny-tools],这个是定制的?
Why do you pull rather than push? 总的来说 pull 简单。pull 模型就需要客户端先保存一部分数据了?
Prometheus原理和源码分析 http://www.infoq.com/cn/articles/Prometheus-theory-source-code “基于pull的数据采集模型一方面降低了客户端复杂度和对外部系统的依赖,另一方面也让客户端实现自由扩展。反观很多基于push模型的监控系统实现,瞬间扩展可能使监控系统服务端出现性能瓶颈,波及整个系统”
每个 metrics 返回的都是多维度的 k-v 值:
node_cpu{cpu="cpu0",mode="system"} 79794.72
node_cpu{cpu="cpu0",mode="user"} 95293.02
对应的 SQL 可以为:
ALERT NodeCPUUsage
IF (100 - (avg(irate(node_cpu{mode="idle"}[5m])) BY (instance) * 100)) > 0.1
FOR 5m
LABELS {severity="page"}
ANNOTATIONS {DESCRIPTION=": CPU 使用率 is above 0.1% (current value is: )", SUMMARY=": 检测到高 CPU 使用率"}
所以这个 SQL 是查所有的 metrics,并没有像传统的说是要查特定的表,这个查找范围不是太大了?
https://github.com/giantswarm/kubernetes-prometheus/issues/89 How to scrape CAdvsior in Kubernetes 1.8. 加上这个 job 后会有更多的 container 信息。
微服务架构下的监控问题应该如何解决?加了很多的定制。
如何监控硬盘S.M.A.R.T信息呢?Textfile Collector 这种方法是直接让 node exporter 读取目录下文件(*.prom)信息,只要文本符合特定格式就可以。文本由脚本生成,example scripts里面有 smartmon.sh 可以直接使用,然后要设置个定时任务来运行脚本生成数据。prom 文件里面并没有时间信息,这说明如果定时任务挂了,最终得到的信息是服务一直在运行,数据没有变化(而不是某个时间段没有数据)。
Prometheus Operator
Stateless is Easy, Stateful is Hard, coreos Operators design for this. Prometheus Operator — 為 Kubernetes 設定及管理 Prometheus. 没大看懂,还是基于 Helm 么?这里的有状态只是配置,并非都是数据库存储。
https://github.com/coreos/prometheus-operator Target Services via Labels: Automatically generate monitoring target configurations based on familiar Kubernetes label queries; no need to learn a Prometheus specific configuration language. 不仅容易配置,而且还容易使用,这个工作量就大了。
https://coreos.com/blog/the-prometheus-operator.html 里面的 third party resources (TPRs) 说法有点老了,现在叫 Custom Resources。两种自定义资源:Prometheus and ServiceMonitor。如果某个应用比如 dashboard 要监控其 frontend,可以在 dashboard yaml (不是 prometheus yaml)里面定义:
apiVersion: monitoring.coreos.com/v1alpha1
kind: ServiceMonitor
metadata:
name: frontend
labels:
tier: frontend
spec:
selector:
matchLabels:
tier: frontend
endpoints:
- port: web # works for different port numbers as long as the name matches
interval: 10s # scrape the endpoint every 10 seconds
就如同在 dashboard 里面定义 service 一样。
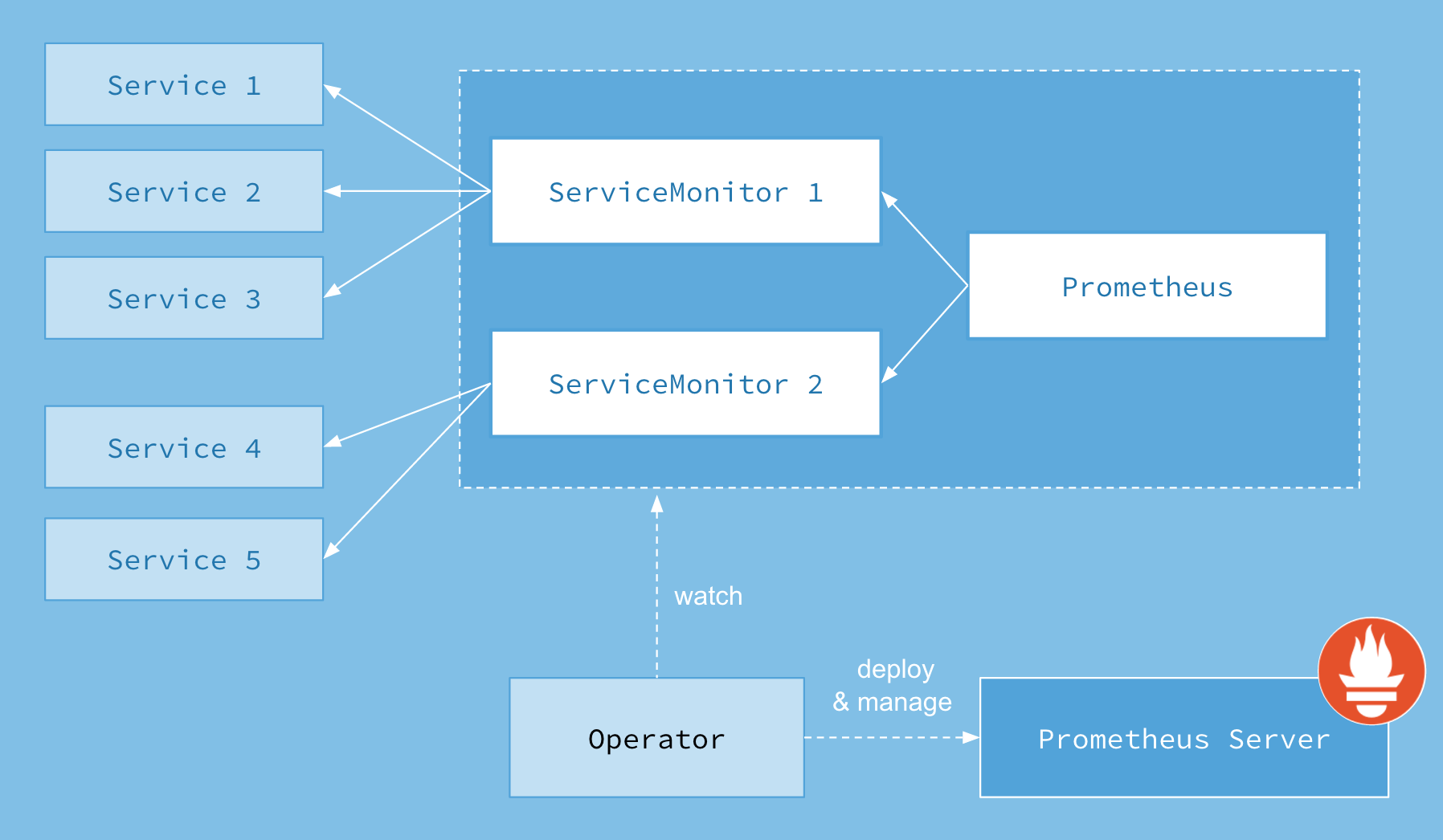
通过这种方式即对 prometheus 进行了隔离,也对如何在 k8s 中使用和驱动 prometheus (开发者自己的领域知识)进行了隔离。
https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus 这个提供安装方法。kubectl create -f manifests/
[root@k8s-1 ~]# kubectl get crd
NAME AGE
alertmanagers.monitoring.coreos.com 18m
prometheuses.monitoring.coreos.com 18m
prometheusrules.monitoring.coreos.com 18m
servicemonitors.monitoring.coreos.com 18m
[root@k8s-1 ~]# kubectl get servicemonitors.monitoring.coreos.com --namespace monitoring
NAME AGE
alertmanager 19m
coredns 18m
kube-apiserver 18m
kube-controller-manager 18m
kube-scheduler 18m
kube-state-metrics 19m
kubelet 18m
node-exporter 18m
prometheus 18m
prometheus-operator 19m
kubectl edit prometheusrules.monitoring.coreos.com prometheus-k8s-rules --namespace monitoring
这里可以直接编辑,说明这些自定义资源的接口(api, cli)都可以重用。UI 还没看到。里面的 rules 都不是 prometheus 标准的 SQL。而且上面的 coredns 我并没有部署啊,预先设置的?
Kubectl get 并不返回这些 CRD,得先自己列出来。以上是对 Service 的监控,我们可能要自己加上对 Helm App 的 CRD。对节点状态呢?
如何监控集群外的服务?比如我运行 kvm 的主机,部署了 node exporter 后,怎么加上这个 target 呢?ServiceMonitor 只能定义 k8s 内部服务,外部的要使用Additional Scrape Configuration,把外部 target 写在 k8s 的 Secret 里面,为什么不用 ConfigMap?我猜是为了用 base64 解决 yaml(prometheus) in yaml(configmap) 的问题。虽然麻烦,好的地方在于修改后 Prometheus 会自动重启。然后在 Granfa 里面不会自动创建对应 Dashboard,我是复制原来的 k8s Nodes Dashboard,然后修改里面的 job 参数(没有作为变量)。
OpenTracing
https://www.jaegertracing.io/docs/architecture/
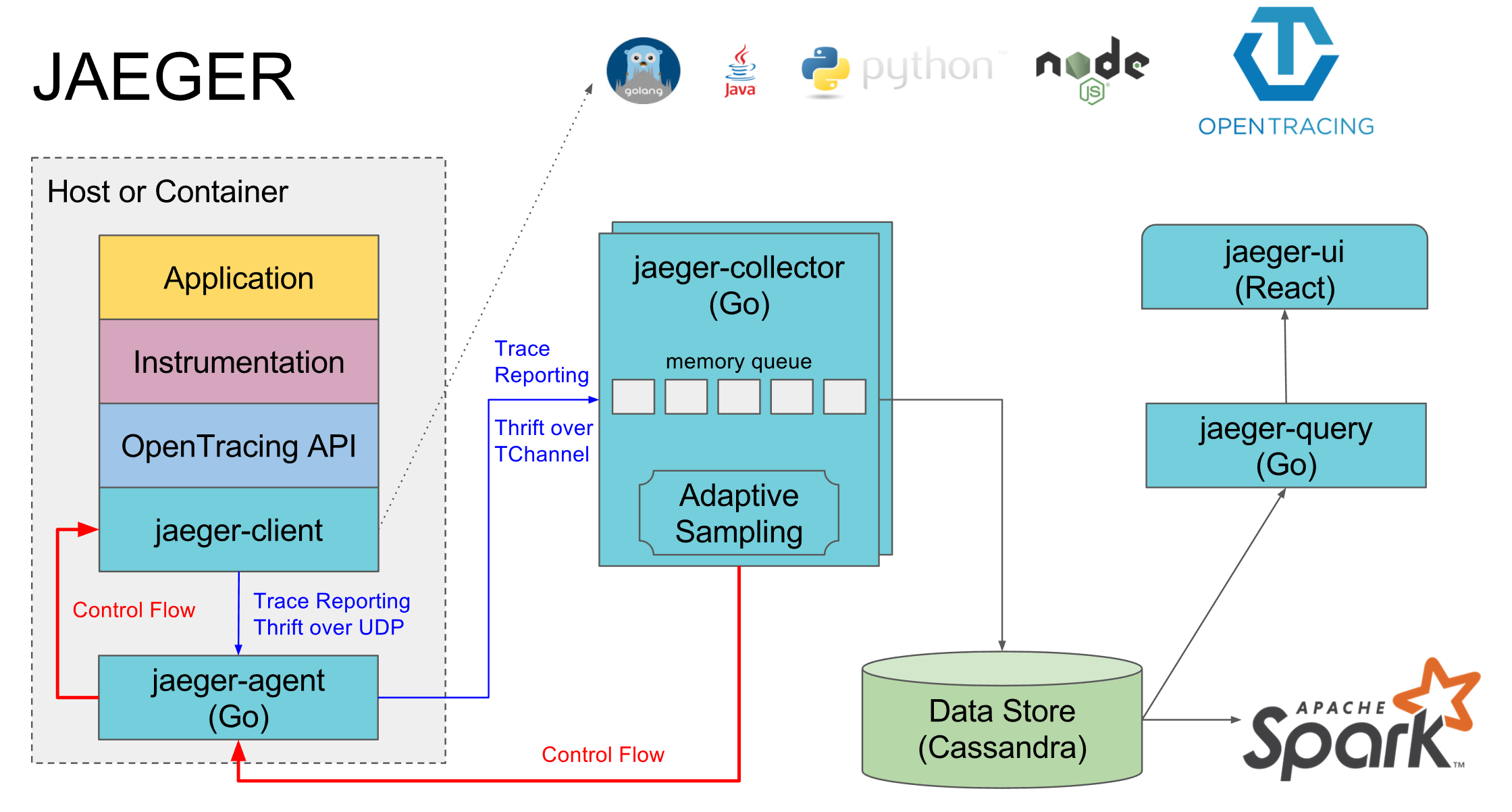
Span 是个完整调用链或者跨度,从开始触发到结果返回。
上面的 jaeger-client 通过 UDP 发送报文,这个报文是单个 trace 还是完整的 span?应该是单个的,完整的是分布式环境。这里上传报文应该有 buffer 吧,否则每次调用就发送报文太耗资源。istio 这块是在 mixer 里面做的上传报文,并非每个 pod 中的 proxy (envoy),proxy 收集数据,所以应该由 proxy 来确定每个 trace 的时间点,proxy 是每个 pod 里面都有,所以这个时间应该相对准确,如果由应用来确定时间则对应用侵入性太大。istio 用的是jaegertracing/all-in-one:1.5,一个 pod 做了 jaeger-agent, jaeger-collector 所有事情,所以并非严格按照上面每个应用/host 上面都安放一个 agent。
jaeger-operator 这个操作起来可能更容易。其部署可以AllInOne,这样所以服务都在一个Pod上面。也可以像Istio那样注入到namespace中,agent作为每个目标Pod的sidecar。也可以DaemonSet方法,在每个host上面只安装一个agent,用户pod可以直接向这个agent发送trace数据(thrift格式),看上去是push模式。
Control Flow 这种反向控制是做何用?
分布式跟踪 jaeger-query 这个 UI (https://github.com/jaegertracing/jaeger Go Lang, React)做的还很专业,能看到调用链和每步花的时间,但是似乎也需要 REST 接口来配合。
这个 Jaeger 是如何无缝的接入到系统中?Istio 如何直接像这个入口发送 log 的呢?看上去要客户端集成 Jaeger 库。
Jaeger 是 CNCF 项目,关注的是 distributed tracing。收集调用链这种数据称为 telemetry,遥测,属于APM(application performance monitor) system 系统
https://github.com/apache/incubator-skywalking 国产,apache 孵化,Java + antd,和 Jaeger 有点像,也对 Istio 做了优化,图形功能更多点。
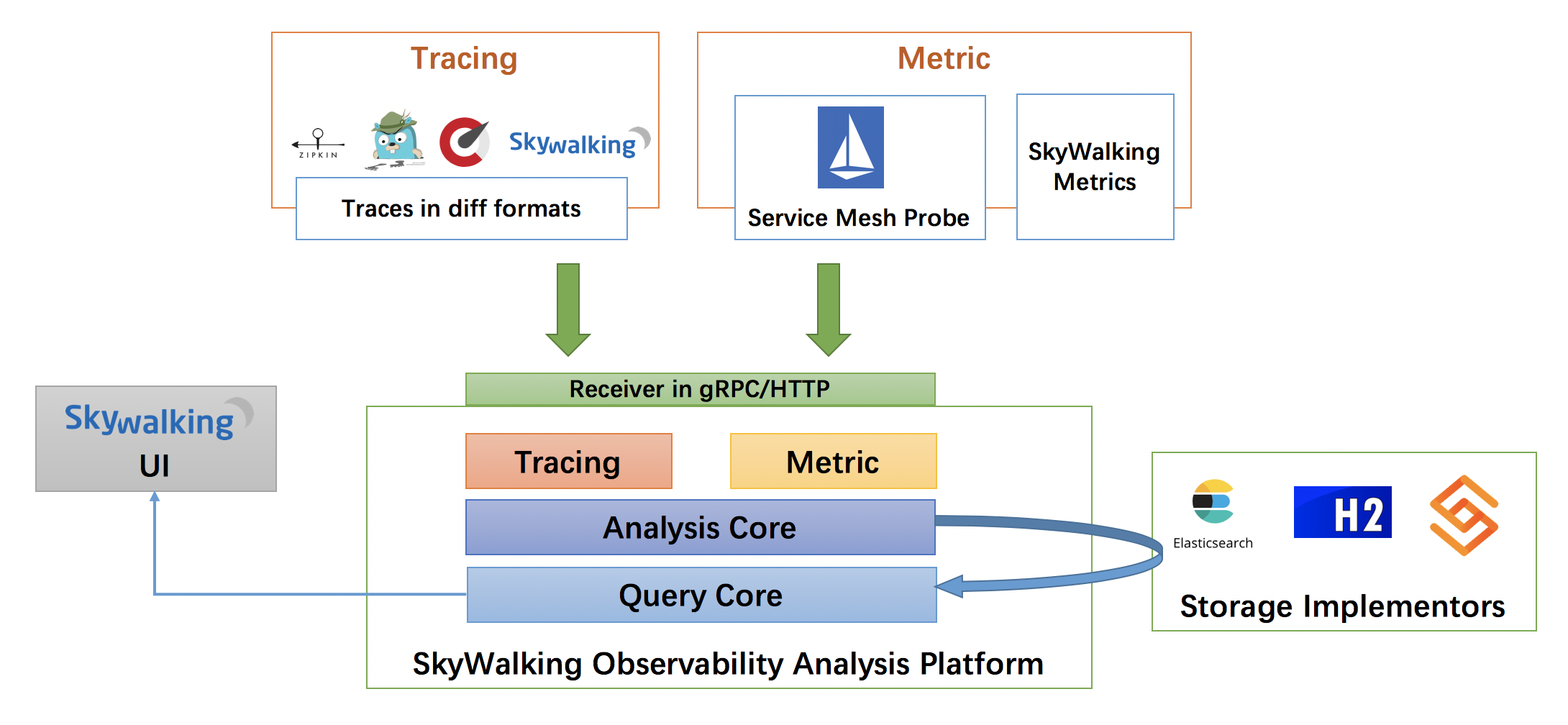
考虑到他也带收集功能,所以对标的应该是 Prometheus - 监控告警,支持ElasticSearch,也支持H2预览版,同时支持ShardingSphere项目用于MySql关系数据库集群的管理。』
Sharding-Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。他们均提供标准化的数据分片、读写分离、柔性事务和数据治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
H2是一个Java编写的关系型数据库,它可以被嵌入Java应用程序中使用,或者作为一个单独的数据库服务器运行。keycloak 默认用的也是这个。当然 keycloak 也是 java 写的。
看来这个 SkyWalking 是 Java 世界的东西了。
Monitoring and Managing Workflows Across Collaborating Microservices 把跟踪数据转化为图形化的工作流,更为直观。业务流程模型和标记法(BPMN, Business Process Model and Notation)是一套图形化表示法,用于以业务流程模型详细说明各种业务流程。
.NET Core 3.0 的新改进:针对分布式应用程序的故障诊断和监控 引出了 W3C Trace Context,这个是标准,会有一个跟踪标识,这样系统不同模块间通过这个标识来串联起一次调用。.Net Core 也支持 OpenTelemetry,很开放。其实对于 Azure 平台,有个 Application Insights 这个大而全的东西,不仅能被动分析发送过来的日志,也能主动分析程序运行时信息比如 HTTP Request 和 Exception。
Think
- 基本上配置都是找到各种数据源
- 如果日志监控这些基础设施本身就不稳定,出现问题就很尴尬了,所以需要分开部署和维护
- 对于开发者来说需要时透明的,不应增加额外负担,比如把日志写到新的地方不需要动源代码
- 这里只是收集数据和初步的分析,和大数据系统有些重合(日志分析是大数据典型案例),所以要考虑各个部分的独立性和灵活性,要有一种数据流(pipeline)的考虑
- 跨语言、跨平台,这样的系统不能对语言和平台有特定要求